This documentation is for an unreleased version of Apache Flink CDC. We recommend you use the latest stable version.
使用 Flink CDC 构建实时数据湖
使用 Flink CDC 构建实时数据湖 #
在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。 但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。
这篇教程将展示如何使用 Flink CDC 构建实时数据湖来应对这种场景,本教程的演示基于 Docker,只涉及 SQL,无需一行 Java/Scala 代码,也无需安装 IDE,你可以很方便地在自己的电脑上完成本教程的全部内容。
接下来将以数据从 MySQL 同步到 Iceberg 为例展示整个流程,架构图如下所示:

你也可以使用不同的 source 比如 Oracle/Postgres 和 sink 比如 Hudi 来构建自己的 ETL 流程。
准备阶段 #
准备一台已经安装了 Docker 的 Linux 或者 MacOS 电脑。
准备教程所需要的组件 #
接下来的教程将以 docker-compose 的方式准备所需要的组件。
使用下面的内容创建一个 docker-compose.yml 文件:
version: '2.1'
services:
sql-client:
user: flink:flink
image: yuxialuo/flink-sql-client:1.13.2.v1
depends_on:
- jobmanager
- mysql
environment:
FLINK_JOBMANAGER_HOST: jobmanager
MYSQL_HOST: mysql
volumes:
- shared-tmpfs:/tmp/iceberg
jobmanager:
user: flink:flink
image: flink:1.13.2-scala_2.11
ports:
- "8081:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
volumes:
- shared-tmpfs:/tmp/iceberg
taskmanager:
user: flink:flink
image: flink:1.13.2-scala_2.11
depends_on:
- jobmanager
command: taskmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 2
volumes:
- shared-tmpfs:/tmp/iceberg
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
volumes:
shared-tmpfs:
driver: local
driver_opts:
type: "tmpfs"
device: "tmpfs"
该 Docker Compose 中包含的容器有:
- SQL-Client: Flink SQL Client, 用来提交 SQL 查询和查看 SQL 的执行结果
- Flink Cluster:包含 Flink JobManager 和 Flink TaskManager,用来执行 Flink SQL
- MySQL:作为分库分表的数据源,存储本教程的
user表
注意:
-
为了简化整个教程,本教程需要的 jar 包都已经被打包进 SQL-Client 容器中了,镜像的构建脚本可以在 GitHub 上找到。 如果你想要在自己的 Flink 环境运行本教程,需要下载下面列出的包并且把它们放在 Flink 所在目录的 lib 目录下,即
FLINK_HOME/lib/。下载链接只对已发布的版本有效, SNAPSHOT 版本需要本地编译
- flink-sql-connector-mysql-cdc-3.3-SNAPSHOT.jar
- flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
- iceberg-flink-1.13-runtime-0.13.0-SNAPSHOT.jar
目前支持 Flink 1.13 的
iceberg-flink-runtimejar 包还没有发布,所以我们在这里提供了一个支持 Flink 1.13 的iceberg-flink-runtimejar 包,这个 jar 包是基于 Iceberg 的 master 分支打包的。 当 Iceberg 0.13.0 版本发布后,你也可以在 apache official repository 下载到支持 Flink 1.13 的iceberg-flink-runtimejar 包。 -
本教程接下来用到的容器相关的命令都需要在
docker-compose.yml所在目录下执行
在 docker-compose.yml 所在目录下执行下面的命令来启动本教程需要的组件:
docker-compose up -d
该命令将以 detached 模式自动启动 Docker Compose 配置中定义的所有容器。你可以通过 docker ps 来观察上述的容器是否正常启动了,也可以通过访问 http://localhost:8081/ 来查看 Flink 是否运行正常。

准备数据 #
-
进入 MySQL 容器中
docker-compose exec mysql mysql -uroot -p123456 -
创建数据和表,并填充数据
创建两个不同的数据库,并在每个数据库中创建两个表,作为
user表分库分表下拆分出的表。CREATE DATABASE db_1; USE db_1; CREATE TABLE user_1 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234","user_110@foo.com"); CREATE TABLE user_2 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_2 VALUES (120,"user_120","Shanghai","123567891234","user_120@foo.com");CREATE DATABASE db_2; USE db_2; CREATE TABLE user_1 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_1 VALUES (110,"user_110","Shanghai","123567891234", NULL); CREATE TABLE user_2 ( id INTEGER NOT NULL PRIMARY KEY, name VARCHAR(255) NOT NULL DEFAULT 'flink', address VARCHAR(1024), phone_number VARCHAR(512), email VARCHAR(255) ); INSERT INTO user_2 VALUES (220,"user_220","Shanghai","123567891234","user_220@foo.com");
在 Flink SQL CLI 中使用 Flink DDL 创建表 #
首先,使用如下的命令进入 Flink SQL CLI 容器中:
docker-compose exec sql-client ./sql-client
我们可以看到如下界面:

然后,进行如下步骤:
-
开启 checkpoint,每隔3秒做一次 checkpoint
Checkpoint 默认是不开启的,我们需要开启 Checkpoint 来让 Iceberg 可以提交事务。 并且,mysql-cdc 在 binlog 读取阶段开始前,需要等待一个完整的 checkpoint 来避免 binlog 记录乱序的情况。
-- Flink SQL Flink SQL> SET execution.checkpointing.interval = 3s; -
创建 MySQL 分库分表 source 表
创建 source 表
user_source来捕获MySQL中所有user表的数据,在表的配置项database-name,table-name使用正则表达式来匹配这些表。 并且,user_source表也定义了 metadata 列来区分数据是来自哪个数据库和表。-- Flink SQL Flink SQL> CREATE TABLE user_source ( database_name STRING METADATA VIRTUAL, table_name STRING METADATA VIRTUAL, `id` DECIMAL(20, 0) NOT NULL, name STRING, address STRING, phone_number STRING, email STRING, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'mysql', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'db_[0-9]+', 'table-name' = 'user_[0-9]+' ); -
创建 Iceberg sink 表
创建 sink 表
all_users_sink,用来将数据加载至 Iceberg 中。 在这个 sink 表,考虑到不同的 MySQL 数据库表的id字段的值可能相同,我们定义了复合主键 (database_name,table_name,id)。-- Flink SQL Flink SQL> CREATE TABLE all_users_sink ( database_name STRING, table_name STRING, `id` DECIMAL(20, 0) NOT NULL, name STRING, address STRING, phone_number STRING, email STRING, PRIMARY KEY (database_name, table_name, `id`) NOT ENFORCED ) WITH ( 'connector'='iceberg', 'catalog-name'='iceberg_catalog', 'catalog-type'='hadoop', 'warehouse'='file:///tmp/iceberg/warehouse', 'format-version'='2' );
流式写入 Iceberg #
-
使用下面的 Flink SQL 语句将数据从 MySQL 写入 Iceberg 中
-- Flink SQL Flink SQL> INSERT INTO all_users_sink select * from user_source;上述命令将会启动一个流式作业,源源不断将 MySQL 数据库中的全量和增量数据同步到 Iceberg 中。 在 Flink UI 上可以看到这个运行的作业:
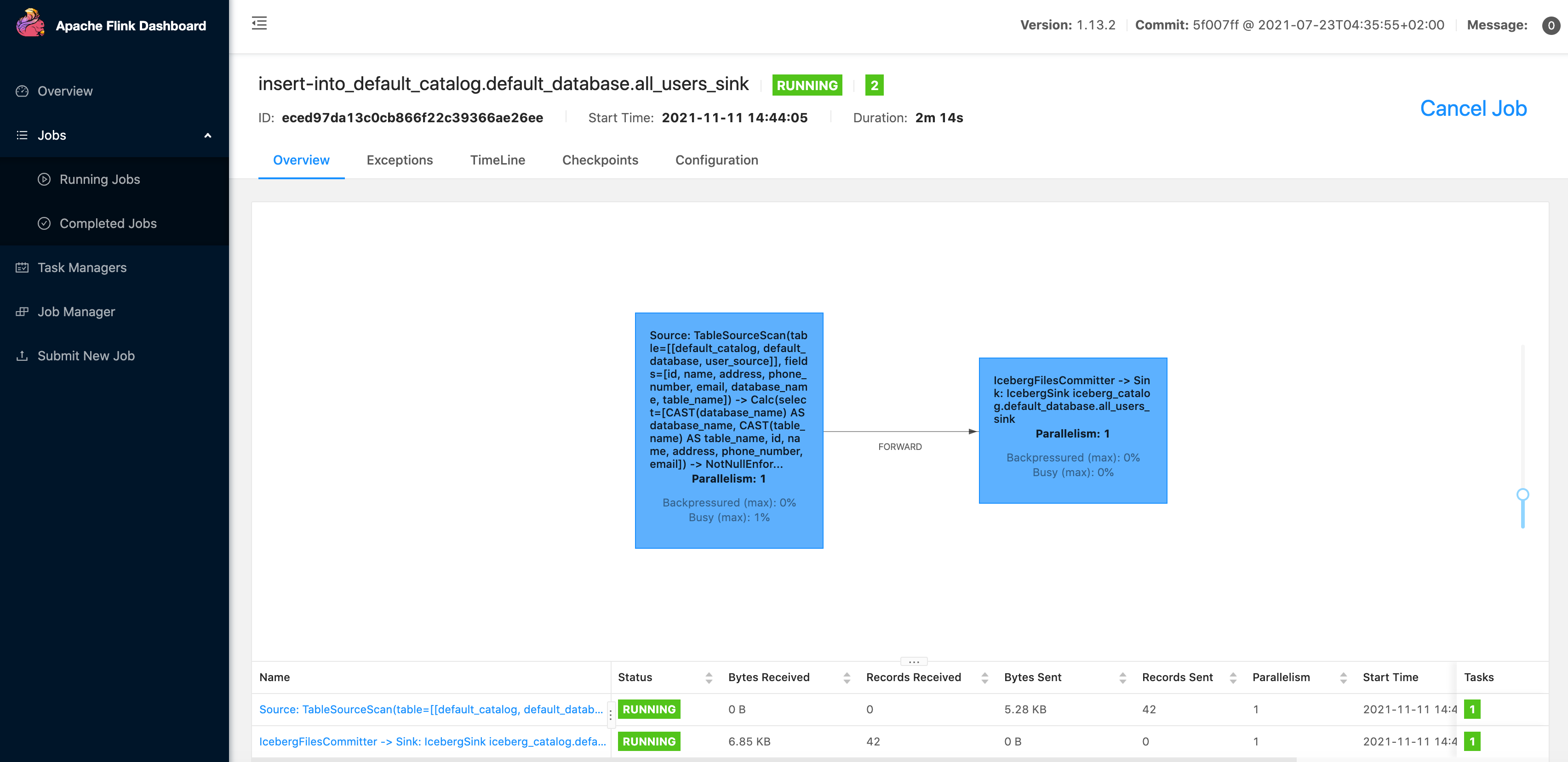
然后我们就可以使用如下的命令看到 Iceberg 中的写入的文件:
docker-compose exec sql-client tree /tmp/iceberg/warehouse/default_database/如下所示:
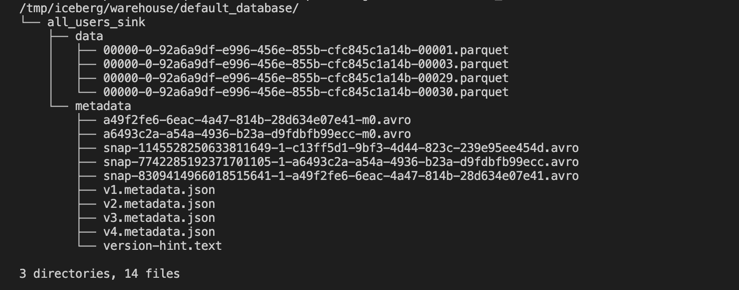
在你的运行环境中,实际的文件可能与上面的截图不相同,但是整体的目录结构应该相似。
-
使用下面的 Flink SQL 语句查询表
all_users_sink中的数据-- Flink SQL Flink SQL> SELECT * FROM all_users_sink;在 Flink SQL CLI 中我们可以看到如下查询结果:

-
修改 MySQL 中表的数据,Iceberg 中的表
all_users_sink中的数据也将实时更新:(3.1) 在
db_1.user_1表中插入新的一行--- db_1 INSERT INTO db_1.user_1 VALUES (111,"user_111","Shanghai","123567891234","user_111@foo.com");(3.2) 更新
db_1.user_2表的数据--- db_1 UPDATE db_1.user_2 SET address='Beijing' WHERE id=120;(3.3) 在
db_2.user_2表中删除一行--- db_2 DELETE FROM db_2.user_2 WHERE id=220;每执行一步,我们就可以在 Flink Client CLI 中使用
SELECT * FROM all_users_sink查询表all_users_sink来看到数据的变化。最后的查询结果如下所示:

从 Iceberg 的最新结果中可以看到新增了
(db_1, user_1, 111)的记录,(db_1, user_2, 120)的地址更新成了Beijing,且(db_2, user_2, 220)的记录被删除了,与我们在 MySQL 做的数据更新完全一致。




环境清理 #
本教程结束后,在 docker-compose.yml 文件所在的目录下执行如下命令停止所有容器:
docker-compose down