User-defined Functions
User-defined functions are an important feature, because they significantly extend the expressiveness of queries.
- Register User-Defined Functions
- Scalar Functions
- Table Functions
- Aggregation Functions
- Table Aggregation Functions
- Best Practices for Implementing UDFs
- Integrating UDFs with the Runtime
Register User-Defined Functions
In most cases, a user-defined function must be registered before it can be used in an query. It is not necessary to register functions for the Scala Table API.
Functions are registered at the TableEnvironment by calling a registerFunction() method. When a user-defined function is registered, it is inserted into the function catalog of the TableEnvironment such that the Table API or SQL parser can recognize and properly translate it.
Please find detailed examples of how to register and how to call each type of user-defined function
(ScalarFunction, TableFunction, and AggregateFunction) in the following sub-sessions.
Scalar Functions
If a required scalar function is not contained in the built-in functions, it is possible to define custom, user-defined scalar functions for both the Table API and SQL. A user-defined scalar functions maps zero, one, or multiple scalar values to a new scalar value.
In order to define a scalar function, one has to extend the base class ScalarFunction in org.apache.flink.table.functions and implement (one or more) evaluation methods. The behavior of a scalar function is determined by the evaluation method. An evaluation method must be declared publicly and named eval. The parameter types and return type of the evaluation method also determine the parameter and return types of the scalar function. Evaluation methods can also be overloaded by implementing multiple methods named eval. Evaluation methods can also support variable arguments, such as eval(String... strs).
The following example shows how to define your own hash code function, register it in the TableEnvironment, and call it in a query. Note that you can configure your scalar function via a constructor before it is registered:
public class HashCode extends ScalarFunction {
private int factor = 12;
public HashCode(int factor) {
this.factor = factor;
}
public int eval(String s) {
return s.hashCode() * factor;
}
}
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// register the function
tableEnv.registerFunction("hashCode", new HashCode(10));
// use the function in Java Table API
myTable.select("string, string.hashCode(), hashCode(string)");
// use the function in SQL API
tableEnv.sqlQuery("SELECT string, hashCode(string) FROM MyTable");By default the result type of an evaluation method is determined by Flink’s type extraction facilities. This is sufficient for basic types or simple POJOs but might be wrong for more complex, custom, or composite types. In these cases TypeInformation of the result type can be manually defined by overriding ScalarFunction#getResultType().
The following example shows an advanced example which takes the internal timestamp representation and also returns the internal timestamp representation as a long value. By overriding ScalarFunction#getResultType() we define that the returned long value should be interpreted as a Types.TIMESTAMP by the code generation.
public static class TimestampModifier extends ScalarFunction {
public long eval(long t) {
return t % 1000;
}
public TypeInformation<?> getResultType(Class<?>[] signature) {
return Types.SQL_TIMESTAMP;
}
}In order to define a scalar function, one has to extend the base class ScalarFunction in org.apache.flink.table.functions and implement (one or more) evaluation methods. The behavior of a scalar function is determined by the evaluation method. An evaluation method must be declared publicly and named eval. The parameter types and return type of the evaluation method also determine the parameter and return types of the scalar function. Evaluation methods can also be overloaded by implementing multiple methods named eval. Evaluation methods can also support variable arguments, such as @varargs def eval(str: String*).
The following example shows how to define your own hash code function, register it in the TableEnvironment, and call it in a query. Note that you can configure your scalar function via a constructor before it is registered:
// must be defined in static/object context
class HashCode(factor: Int) extends ScalarFunction {
def eval(s: String): Int = {
s.hashCode() * factor
}
}
val tableEnv = BatchTableEnvironment.create(env)
// use the function in Scala Table API
val hashCode = new HashCode(10)
myTable.select('string, hashCode('string))
// register and use the function in SQL
tableEnv.registerFunction("hashCode", new HashCode(10))
tableEnv.sqlQuery("SELECT string, hashCode(string) FROM MyTable")By default the result type of an evaluation method is determined by Flink’s type extraction facilities. This is sufficient for basic types or simple POJOs but might be wrong for more complex, custom, or composite types. In these cases TypeInformation of the result type can be manually defined by overriding ScalarFunction#getResultType().
The following example shows an advanced example which takes the internal timestamp representation and also returns the internal timestamp representation as a long value. By overriding ScalarFunction#getResultType() we define that the returned long value should be interpreted as a Types.TIMESTAMP by the code generation.
object TimestampModifier extends ScalarFunction {
def eval(t: Long): Long = {
t % 1000
}
override def getResultType(signature: Array[Class[_]]): TypeInformation[_] = {
Types.TIMESTAMP
}
}In order to define a Python scalar function, one can extend the base class ScalarFunction in pyflink.table.udf and implement an evaluation method. The behavior of a Python scalar function is determined by the evaluation method which is named eval.
The following example shows how to define your own Python hash code function, register it in the TableEnvironment, and call it in a query. Note that you can configure your scalar function via a constructor before it is registered:
class HashCode(ScalarFunction):
def __init__(self):
self.factor = 12
def eval(self, s):
return hash(s) * self.factor
# use StreamTableEnvironment since Python UDF is not supported in the old planner under batch mode
table_env = StreamTableEnvironment.create(env)
# register the Python function
table_env.register_function("hash_code", udf(HashCode(), DataTypes.BIGINT(), DataTypes.BIGINT()))
# use the function in Python Table API
my_table.select("string, bigint, string.hash_code(), hash_code(string)")
# use the function in SQL API
table_env.sql_query("SELECT string, bigint, hash_code(bigint) FROM MyTable")There are many ways to define a Python scalar function besides extending the base class ScalarFunction.
Please refer to the Python Scalar Function documentation for more details.
Table Functions
Similar to a user-defined scalar function, a user-defined table function takes zero, one, or multiple scalar values as input parameters. However in contrast to a scalar function, it can return an arbitrary number of rows as output instead of a single value. The returned rows may consist of one or more columns.
In order to define a table function one has to extend the base class TableFunction in org.apache.flink.table.functions and implement (one or more) evaluation methods. The behavior of a table function is determined by its evaluation methods. An evaluation method must be declared public and named eval. The TableFunction can be overloaded by implementing multiple methods named eval. The parameter types of the evaluation methods determine all valid parameters of the table function. Evaluation methods can also support variable arguments, such as eval(String... strs). The type of the returned table is determined by the generic type of TableFunction. Evaluation methods emit output rows using the protected collect(T) method.
In the Table API, a table function is used with .joinLateral or .leftOuterJoinLateral. The joinLateral operator (cross) joins each row from the outer table (table on the left of the operator) with all rows produced by the table-valued function (which is on the right side of the operator). The leftOuterJoinLateral operator joins each row from the outer table (table on the left of the operator) with all rows produced by the table-valued function (which is on the right side of the operator) and preserves outer rows for which the table function returns an empty table. In SQL use LATERAL TABLE(<TableFunction>) with CROSS JOIN and LEFT JOIN with an ON TRUE join condition (see examples below).
The following example shows how to define table-valued function, register it in the TableEnvironment, and call it in a query. Note that you can configure your table function via a constructor before it is registered:
// The generic type "Tuple2<String, Integer>" determines the schema of the returned table as (String, Integer).
public class Split extends TableFunction<Tuple2<String, Integer>> {
private String separator = " ";
public Split(String separator) {
this.separator = separator;
}
public void eval(String str) {
for (String s : str.split(separator)) {
// use collect(...) to emit a row
collect(new Tuple2<String, Integer>(s, s.length()));
}
}
}
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
Table myTable = ... // table schema: [a: String]
// Register the function.
tableEnv.registerFunction("split", new Split("#"));
// Use the table function in the Java Table API. "as" specifies the field names of the table.
myTable.joinLateral("split(a) as (word, length)")
.select("a, word, length");
myTable.leftOuterJoinLateral("split(a) as (word, length)")
.select("a, word, length");
// Use the table function in SQL with LATERAL and TABLE keywords.
// CROSS JOIN a table function (equivalent to "join" in Table API).
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)");
// LEFT JOIN a table function (equivalent to "leftOuterJoin" in Table API).
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE");// The generic type "(String, Int)" determines the schema of the returned table as (String, Integer).
class Split(separator: String) extends TableFunction[(String, Int)] {
def eval(str: String): Unit = {
// use collect(...) to emit a row.
str.split(separator).foreach(x => collect((x, x.length)))
}
}
val tableEnv = BatchTableEnvironment.create(env)
val myTable = ... // table schema: [a: String]
// Use the table function in the Scala Table API (Note: No registration required in Scala Table API).
val split = new Split("#")
// "as" specifies the field names of the generated table.
myTable.joinLateral(split('a) as ('word, 'length)).select('a, 'word, 'length)
myTable.leftOuterJoinLateral(split('a) as ('word, 'length)).select('a, 'word, 'length)
// Register the table function to use it in SQL queries.
tableEnv.registerFunction("split", new Split("#"))
// Use the table function in SQL with LATERAL and TABLE keywords.
// CROSS JOIN a table function (equivalent to "join" in Table API)
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
// LEFT JOIN a table function (equivalent to "leftOuterJoin" in Table API)
tableEnv.sqlQuery("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")IMPORTANT: Do not implement TableFunction as a Scala object. Scala object is a singleton and will cause concurrency issues.
'''
Java code:
// The generic type "Tuple2<String, Integer>" determines the schema of the returned table as (String, Integer).
// The java class must have a public no-argument constructor and can be founded in current java classloader.
public class Split extends TableFunction<Tuple2<String, Integer>> {
private String separator = " ";
public void eval(String str) {
for (String s : str.split(separator)) {
// use collect(...) to emit a row
collect(new Tuple2<String, Integer>(s, s.length()));
}
}
}
'''
table_env = BatchTableEnvironment.create(env)
my_table = ... # type: Table, table schema: [a: String]
# Register the java function.
table_env.register_java_function("split", "my.java.function.Split")
# Use the table function in the Python Table API. "as" specifies the field names of the table.
my_table.join_lateral("split(a) as (word, length)").select("a, word, length")
my_table.left_outer_join_lateral("split(a) as (word, length)").select("a, word, length")
# Register the python function.
# Use the table function in SQL with LATERAL and TABLE keywords.
# CROSS JOIN a table function (equivalent to "join" in Table API).
table_env.sql_query("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
# LEFT JOIN a table function (equivalent to "left_outer_join" in Table API).
table_env.sql_query("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")Please note that POJO types do not have a deterministic field order. Therefore, you cannot rename the fields of POJO returned by a table function using AS.
By default the result type of a TableFunction is determined by Flink’s automatic type extraction facilities. This works well for basic types and simple POJOs but might be wrong for more complex, custom, or composite types. In such a case, the type of the result can be manually specified by overriding TableFunction#getResultType() which returns its TypeInformation.
The following example shows an example of a TableFunction that returns a Row type which requires explicit type information. We define that the returned table type should be RowTypeInfo(String, Integer) by overriding TableFunction#getResultType().
public class CustomTypeSplit extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
Row row = new Row(2);
row.setField(0, s);
row.setField(1, s.length());
collect(row);
}
}
@Override
public TypeInformation<Row> getResultType() {
return Types.ROW(Types.STRING(), Types.INT());
}
}class CustomTypeSplit extends TableFunction[Row] {
def eval(str: String): Unit = {
str.split(" ").foreach({ s =>
val row = new Row(2)
row.setField(0, s)
row.setField(1, s.length)
collect(row)
})
}
override def getResultType: TypeInformation[Row] = {
Types.ROW(Types.STRING, Types.INT)
}
}Aggregation Functions
User-Defined Aggregate Functions (UDAGGs) aggregate a table (one or more rows with one or more attributes) to a scalar value.
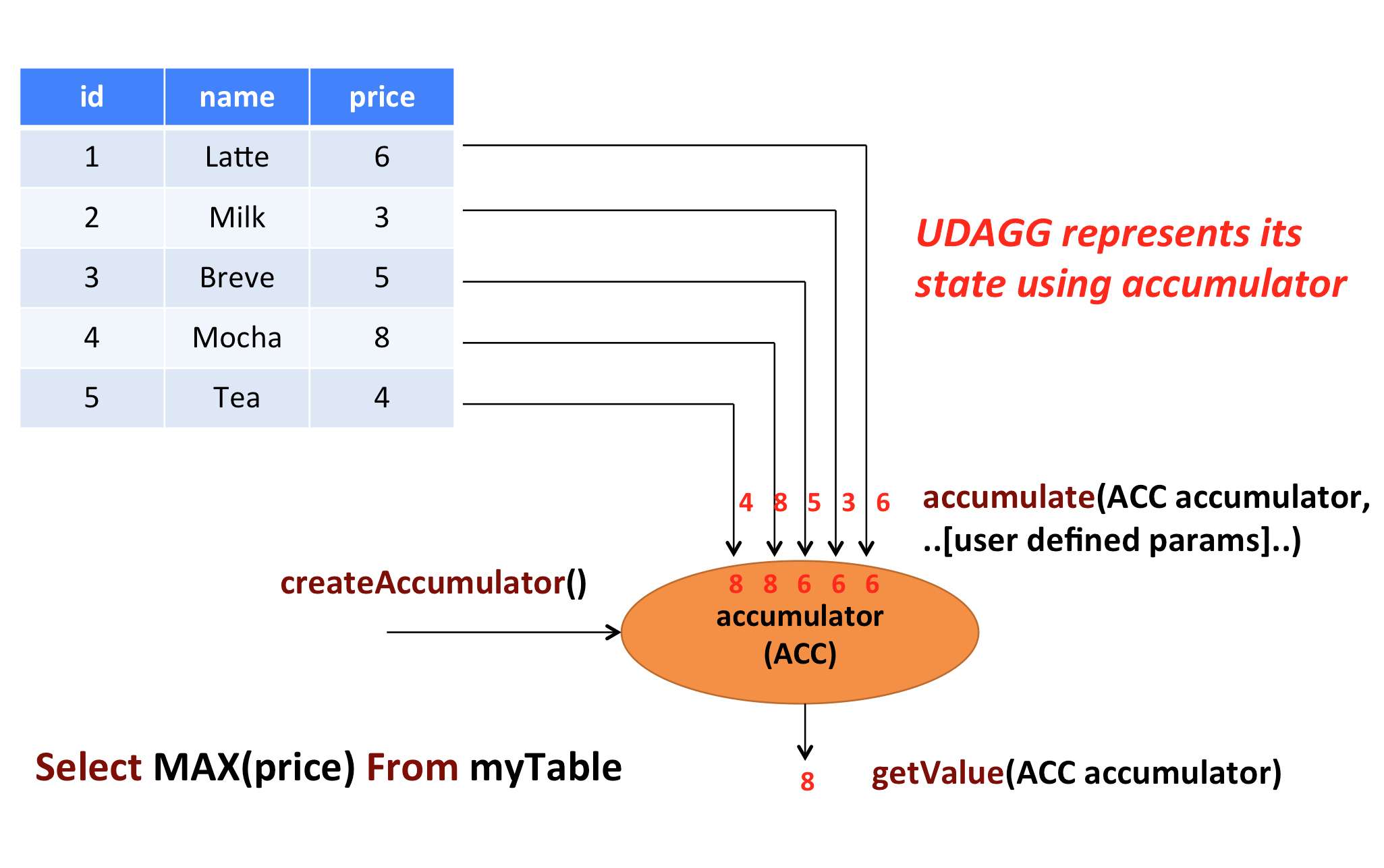
The above figure shows an example of an aggregation. Assume you have a table that contains data about beverages. The table consists of three columns, id, name and price and 5 rows. Imagine you need to find the highest price of all beverages in the table, i.e., perform a max() aggregation. You would need to check each of the 5 rows and the result would be a single numeric value.
User-defined aggregation functions are implemented by extending the AggregateFunction class. An AggregateFunction works as follows. First, it needs an accumulator, which is the data structure that holds the intermediate result of the aggregation. An empty accumulator is created by calling the createAccumulator() method of the AggregateFunction. Subsequently, the accumulate() method of the function is called for each input row to update the accumulator. Once all rows have been processed, the getValue() method of the function is called to compute and return the final result.
The following methods are mandatory for each AggregateFunction:
createAccumulator()accumulate()getValue()
Flink’s type extraction facilities can fail to identify complex data types, e.g., if they are not basic types or simple POJOs. So similar to ScalarFunction and TableFunction, AggregateFunction provides methods to specify the TypeInformation of the result type (through
AggregateFunction#getResultType()) and the type of the accumulator (through AggregateFunction#getAccumulatorType()).
Besides the above methods, there are a few contracted methods that can be
optionally implemented. While some of these methods allow the system more efficient query execution, others are mandatory for certain use cases. For instance, the merge() method is mandatory if the aggregation function should be applied in the context of a session group window (the accumulators of two session windows need to be joined when a row is observed that “connects” them).
The following methods of AggregateFunction are required depending on the use case:
retract()is required for aggregations on boundedOVERwindows.merge()is required for many batch aggregations and session window aggregations.resetAccumulator()is required for many batch aggregations.
All methods of AggregateFunction must be declared as public, not static and named exactly as the names mentioned above. The methods createAccumulator, getValue, getResultType, and getAccumulatorType are defined in the AggregateFunction abstract class, while others are contracted methods. In order to define a aggregate function, one has to extend the base class org.apache.flink.table.functions.AggregateFunction and implement one (or more) accumulate methods. The method accumulate can be overloaded with different parameter types and supports variable arguments.
Detailed documentation for all methods of AggregateFunction is given below.
/**
* Base class for user-defined aggregates and table aggregates.
*
* @param <T> the type of the aggregation result.
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
public abstract class UserDefinedAggregateFunction<T, ACC> extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
public ACC createAccumulator(); // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
public TypeInformation<T> getResultType = null; // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
public TypeInformation<ACC> getAccumulatorType = null; // PRE-DEFINED
}
/**
* Base class for aggregation functions.
*
* @param <T> the type of the aggregation result
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* AggregateFunction represents its state using accumulator, thereby the state of the
* AggregateFunction must be put into the accumulator.
*/
public abstract class AggregateFunction<T, ACC> extends UserDefinedAggregateFunction<T, ACC> {
/** Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An AggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs]); // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs]); // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and dataset grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an {@link java.lang.Iterable} pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> its); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized.
* The returned value could be either an early and incomplete result
* (periodically emitted as data arrive) or the final result of the
* aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @return the aggregation result
*/
public T getValue(ACC accumulator); // MANDATORY
/**
* Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for
* dataset grouping aggregate.
*
* @param accumulator the accumulator which needs to be reset
*/
public void resetAccumulator(ACC accumulator); // OPTIONAL
/**
* Returns true if this AggregateFunction can only be applied in an OVER window.
*
* @return true if the AggregateFunction requires an OVER window, false otherwise.
*/
public Boolean requiresOver = false; // PRE-DEFINED
}/**
* Base class for user-defined aggregates and table aggregates.
*
* @tparam T the type of the aggregation result.
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
abstract class UserDefinedAggregateFunction[T, ACC] extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
def createAccumulator(): ACC // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
def getResultType: TypeInformation[T] = null // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
def getAccumulatorType: TypeInformation[ACC] = null // PRE-DEFINED
}
/**
* Base class for aggregation functions.
*
* @tparam T the type of the aggregation result
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* AggregateFunction represents its state using accumulator, thereby the state of the
* AggregateFunction must be put into the accumulator.
*/
abstract class AggregateFunction[T, ACC] extends UserDefinedAggregateFunction[T, ACC] {
/**
* Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An AggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and dataset grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, its: java.lang.Iterable[ACC]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized.
* The returned value could be either an early and incomplete result
* (periodically emitted as data arrive) or the final result of the
* aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @return the aggregation result
*/
def getValue(accumulator: ACC): T // MANDATORY
/**
* Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for
* dataset grouping aggregate.
*
* @param accumulator the accumulator which needs to be reset
*/
def resetAccumulator(accumulator: ACC): Unit // OPTIONAL
/**
* Returns true if this AggregateFunction can only be applied in an OVER window.
*
* @return true if the AggregateFunction requires an OVER window, false otherwise.
*/
def requiresOver: Boolean = false // PRE-DEFINED
}The following example shows how to
- define an
AggregateFunctionthat calculates the weighted average on a given column, - register the function in the
TableEnvironment, and - use the function in a query.
To calculate an weighted average value, the accumulator needs to store the weighted sum and count of all the data that has been accumulated. In our example we define a class WeightedAvgAccum to be the accumulator. Accumulators are automatically backup-ed by Flink’s checkpointing mechanism and restored in case of a failure to ensure exactly-once semantics.
The accumulate() method of our WeightedAvg AggregateFunction has three inputs. The first one is the WeightedAvgAccum accumulator, the other two are user-defined inputs: input value ivalue and weight of the input iweight. Although the retract(), merge(), and resetAccumulator() methods are not mandatory for most aggregation types, we provide them below as examples. Please note that we used Java primitive types and defined getResultType() and getAccumulatorType() methods in the Scala example because Flink type extraction does not work very well for Scala types.
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
// register function
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("wAvg", new WeightedAvg());
// use function
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user");import java.lang.{Long => JLong, Integer => JInteger}
import org.apache.flink.api.java.tuple.{Tuple1 => JTuple1}
import org.apache.flink.api.java.typeutils.TupleTypeInfo
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.AggregateFunction
/**
* Accumulator for WeightedAvg.
*/
class WeightedAvgAccum extends JTuple1[JLong, JInteger] {
sum = 0L
count = 0
}
/**
* Weighted Average user-defined aggregate function.
*/
class WeightedAvg extends AggregateFunction[JLong, CountAccumulator] {
override def createAccumulator(): WeightedAvgAccum = {
new WeightedAvgAccum
}
override def getValue(acc: WeightedAvgAccum): JLong = {
if (acc.count == 0) {
null
} else {
acc.sum / acc.count
}
}
def accumulate(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {
acc.sum += iValue * iWeight
acc.count += iWeight
}
def retract(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {
acc.sum -= iValue * iWeight
acc.count -= iWeight
}
def merge(acc: WeightedAvgAccum, it: java.lang.Iterable[WeightedAvgAccum]): Unit = {
val iter = it.iterator()
while (iter.hasNext) {
val a = iter.next()
acc.count += a.count
acc.sum += a.sum
}
}
def resetAccumulator(acc: WeightedAvgAccum): Unit = {
acc.count = 0
acc.sum = 0L
}
override def getAccumulatorType: TypeInformation[WeightedAvgAccum] = {
new TupleTypeInfo(classOf[WeightedAvgAccum], Types.LONG, Types.INT)
}
override def getResultType: TypeInformation[JLong] = Types.LONG
}
// register function
val tEnv: StreamTableEnvironment = ???
tEnv.registerFunction("wAvg", new WeightedAvg())
// use function
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")'''
Java code:
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
// The java class must have a public no-argument constructor and can be founded in current java classloader.
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
'''
# register function
t_env = ... # type: StreamTableEnvironment
t_env.register_java_function("wAvg", "my.java.function.WeightedAvg")
# use function
t_env.sql_query("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")Table Aggregation Functions
User-Defined Table Aggregate Functions (UDTAGGs) aggregate a table (one or more rows with one or more attributes) to a result table with multi rows and columns.
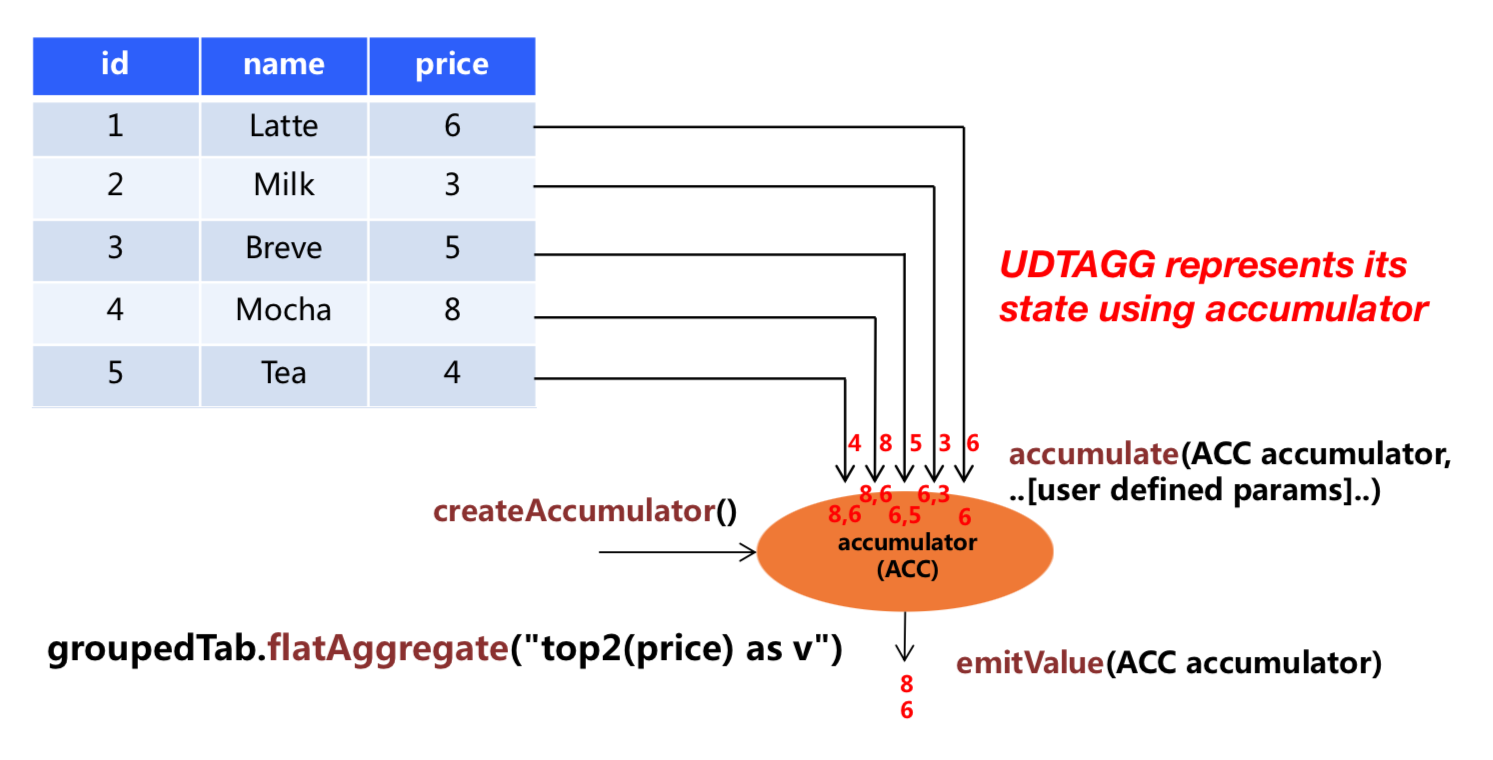
The above figure shows an example of a table aggregation. Assume you have a table that contains data about beverages. The table consists of three columns, id, name and price and 5 rows. Imagine you need to find the top 2 highest prices of all beverages in the table, i.e., perform a top2() table aggregation. You would need to check each of the 5 rows and the result would be a table with the top 2 values.
User-defined table aggregation functions are implemented by extending the TableAggregateFunction class. A TableAggregateFunction works as follows. First, it needs an accumulator, which is the data structure that holds the intermediate result of the aggregation. An empty accumulator is created by calling the createAccumulator() method of the TableAggregateFunction. Subsequently, the accumulate() method of the function is called for each input row to update the accumulator. Once all rows have been processed, the emitValue() method of the function is called to compute and return the final results.
The following methods are mandatory for each TableAggregateFunction:
createAccumulator()accumulate()
Flink’s type extraction facilities can fail to identify complex data types, e.g., if they are not basic types or simple POJOs. So similar to ScalarFunction and TableFunction, TableAggregateFunction provides methods to specify the TypeInformation of the result type (through
TableAggregateFunction#getResultType()) and the type of the accumulator (through TableAggregateFunction#getAccumulatorType()).
Besides the above methods, there are a few contracted methods that can be
optionally implemented. While some of these methods allow the system more efficient query execution, others are mandatory for certain use cases. For instance, the merge() method is mandatory if the aggregation function should be applied in the context of a session group window (the accumulators of two session windows need to be joined when a row is observed that “connects” them).
The following methods of TableAggregateFunction are required depending on the use case:
retract()is required for aggregations on boundedOVERwindows.merge()is required for many batch aggregations and session window aggregations.resetAccumulator()is required for many batch aggregations.emitValue()is required for batch and window aggregations.
The following methods of TableAggregateFunction are used to improve the performance of streaming jobs:
emitUpdateWithRetract()is used to emit values that have been updated under retract mode.
For emitValue method, it emits full data according to the accumulator. Take TopN as an example, emitValue emit all top n values each time. This may bring performance problems for streaming jobs. To improve the performance, a user can also implement emitUpdateWithRetract method to improve the performance. The method outputs data incrementally in retract mode, i.e., once there is an update, we have to retract old records before sending new updated ones. The method will be used in preference to the emitValue method if they are all defined in the table aggregate function, because emitUpdateWithRetract is treated to be more efficient than emitValue as it can output values incrementally.
All methods of TableAggregateFunction must be declared as public, not static and named exactly as the names mentioned above. The methods createAccumulator, getResultType, and getAccumulatorType are defined in the parent abstract class of TableAggregateFunction, while others are contracted methods. In order to define a table aggregate function, one has to extend the base class org.apache.flink.table.functions.TableAggregateFunction and implement one (or more) accumulate methods. The method accumulate can be overloaded with different parameter types and supports variable arguments.
Detailed documentation for all methods of TableAggregateFunction is given below.
/**
* Base class for user-defined aggregates and table aggregates.
*
* @param <T> the type of the aggregation result.
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
public abstract class UserDefinedAggregateFunction<T, ACC> extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
public ACC createAccumulator(); // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
public TypeInformation<T> getResultType = null; // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
public TypeInformation<ACC> getAccumulatorType = null; // PRE-DEFINED
}
/**
* Base class for table aggregation functions.
*
* @param <T> the type of the aggregation result
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute a table aggregation result.
* TableAggregateFunction represents its state using accumulator, thereby the state of
* the TableAggregateFunction must be put into the accumulator.
*/
public abstract class TableAggregateFunction<T, ACC> extends UserDefinedAggregateFunction<T, ACC> {
/** Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. A TableAggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs]); // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs]); // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and dataset grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an {@link java.lang.Iterable} pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> its); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the collector used to output data
*/
public void emitValue(ACC accumulator, Collector<T> out); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* Different from emitValue, emitUpdateWithRetract is used to emit values that have been updated.
* This method outputs data incrementally in retract mode, i.e., once there is an update, we
* have to retract old records before sending new updated ones. The emitUpdateWithRetract
* method will be used in preference to the emitValue method if both methods are defined in the
* table aggregate function, because the method is treated to be more efficient than emitValue
* as it can outputvalues incrementally.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the retractable collector used to output data. Use collect method
* to output(add) records and use retract method to retract(delete)
* records.
*/
public void emitUpdateWithRetract(ACC accumulator, RetractableCollector<T> out); // OPTIONAL
/**
* Collects a record and forwards it. The collector can output retract messages with the retract
* method. Note: only use it in {@code emitRetractValueIncrementally}.
*/
public interface RetractableCollector<T> extends Collector<T> {
/**
* Retract a record.
*
* @param record The record to retract.
*/
void retract(T record);
}
}/**
* Base class for user-defined aggregates and table aggregates.
*
* @tparam T the type of the aggregation result.
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
abstract class UserDefinedAggregateFunction[T, ACC] extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
def createAccumulator(): ACC // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
def getResultType: TypeInformation[T] = null // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
def getAccumulatorType: TypeInformation[ACC] = null // PRE-DEFINED
}
/**
* Base class for table aggregation functions.
*
* @tparam T the type of the aggregation result
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* TableAggregateFunction represents its state using accumulator, thereby the state of
* the TableAggregateFunction must be put into the accumulator.
*/
abstract class TableAggregateFunction[T, ACC] extends UserDefinedAggregateFunction[T, ACC] {
/**
* Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. A TableAggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and dataset grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, its: java.lang.Iterable[ACC]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the collector used to output data
*/
def emitValue(accumulator: ACC, out: Collector[T]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* Different from emitValue, emitUpdateWithRetract is used to emit values that have been updated.
* This method outputs data incrementally in retract mode, i.e., once there is an update, we
* have to retract old records before sending new updated ones. The emitUpdateWithRetract
* method will be used in preference to the emitValue method if both methods are defined in the
* table aggregate function, because the method is treated to be more efficient than emitValue
* as it can outputvalues incrementally.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the retractable collector used to output data. Use collect method
* to output(add) records and use retract method to retract(delete)
* records.
*/
def emitUpdateWithRetract(accumulator: ACC, out: RetractableCollector[T]): Unit // OPTIONAL
/**
* Collects a record and forwards it. The collector can output retract messages with the retract
* method. Note: only use it in `emitRetractValueIncrementally`.
*/
trait RetractableCollector[T] extends Collector[T] {
/**
* Retract a record.
*
* @param record The record to retract.
*/
def retract(record: T): Unit
}
}The following example shows how to
- define a
TableAggregateFunctionthat calculates the top 2 values on a given column, - register the function in the
TableEnvironment, and - use the function in a Table API query(TableAggregateFunction is only supported by Table API).
To calculate the top 2 values, the accumulator needs to store the biggest 2 values of all the data that has been accumulated. In our example we define a class Top2Accum to be the accumulator. Accumulators are automatically backup-ed by Flink’s checkpointing mechanism and restored in case of a failure to ensure exactly-once semantics.
The accumulate() method of our Top2 TableAggregateFunction has two inputs. The first one is the Top2Accum accumulator, the other one is the user-defined input: input value v. Although the merge() method is not mandatory for most table aggregation types, we provide it below as examples. Please note that we used Java primitive types and defined getResultType() and getAccumulatorType() methods in the Scala example because Flink type extraction does not work very well for Scala types.
/**
* Accumulator for Top2.
*/
public class Top2Accum {
public Integer first;
public Integer second;
}
/**
* The top2 user-defined table aggregate function.
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {
for (Top2Accum otherAcc : iterable) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
// register function
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("top2", new Top2());
// init table
Table tab = ...;
// use function
tab.groupBy("key")
.flatAggregate("top2(a) as (v, rank)")
.select("key, v, rank");import java.lang.{Integer => JInteger}
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.TableAggregateFunction
/**
* Accumulator for top2.
*/
class Top2Accum {
var first: JInteger = _
var second: JInteger = _
}
/**
* The top2 user-defined table aggregate function.
*/
class Top2 extends TableAggregateFunction[JTuple2[JInteger, JInteger], Top2Accum] {
override def createAccumulator(): Top2Accum = {
val acc = new Top2Accum
acc.first = Int.MinValue
acc.second = Int.MinValue
acc
}
def accumulate(acc: Top2Accum, v: Int) {
if (v > acc.first) {
acc.second = acc.first
acc.first = v
} else if (v > acc.second) {
acc.second = v
}
}
def merge(acc: Top2Accum, its: JIterable[Top2Accum]): Unit = {
val iter = its.iterator()
while (iter.hasNext) {
val top2 = iter.next()
accumulate(acc, top2.first)
accumulate(acc, top2.second)
}
}
def emitValue(acc: Top2Accum, out: Collector[JTuple2[JInteger, JInteger]]): Unit = {
// emit the value and rank
if (acc.first != Int.MinValue) {
out.collect(JTuple2.of(acc.first, 1))
}
if (acc.second != Int.MinValue) {
out.collect(JTuple2.of(acc.second, 2))
}
}
}
// init table
val tab = ...
// use function
tab
.groupBy('key)
.flatAggregate(top2('a) as ('v, 'rank))
.select('key, 'v, 'rank)The following example shows how to use emitUpdateWithRetract method to emit only updates. To emit only updates, in our example, the accumulator keeps both old and new top 2 values. Note: if the N of topN is big, it may inefficient to keep both old and new values. One way to solve this case is to store the input record into the accumulator in accumulate method and then perform calculation in emitUpdateWithRetract.
/**
* Accumulator for Top2.
*/
public class Top2Accum {
public Integer first;
public Integer second;
public Integer oldFirst;
public Integer oldSecond;
}
/**
* The top2 user-defined table aggregate function.
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
acc.oldFirst = Integer.MIN_VALUE;
acc.oldSecond = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void emitUpdateWithRetract(Top2Accum acc, RetractableCollector<Tuple2<Integer, Integer>> out) {
if (!acc.first.equals(acc.oldFirst)) {
// if there is an update, retract old value then emit new value.
if (acc.oldFirst != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldFirst, 1));
}
out.collect(Tuple2.of(acc.first, 1));
acc.oldFirst = acc.first;
}
if (!acc.second.equals(acc.oldSecond)) {
// if there is an update, retract old value then emit new value.
if (acc.oldSecond != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldSecond, 2));
}
out.collect(Tuple2.of(acc.second, 2));
acc.oldSecond = acc.second;
}
}
}
// register function
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("top2", new Top2());
// init table
Table tab = ...;
// use function
tab.groupBy("key")
.flatAggregate("top2(a) as (v, rank)")
.select("key, v, rank");import java.lang.{Integer => JInteger}
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.TableAggregateFunction
/**
* Accumulator for top2.
*/
class Top2Accum {
var first: JInteger = _
var second: JInteger = _
var oldFirst: JInteger = _
var oldSecond: JInteger = _
}
/**
* The top2 user-defined table aggregate function.
*/
class Top2 extends TableAggregateFunction[JTuple2[JInteger, JInteger], Top2Accum] {
override def createAccumulator(): Top2Accum = {
val acc = new Top2Accum
acc.first = Int.MinValue
acc.second = Int.MinValue
acc.oldFirst = Int.MinValue
acc.oldSecond = Int.MinValue
acc
}
def accumulate(acc: Top2Accum, v: Int) {
if (v > acc.first) {
acc.second = acc.first
acc.first = v
} else if (v > acc.second) {
acc.second = v
}
}
def emitUpdateWithRetract(
acc: Top2Accum,
out: RetractableCollector[JTuple2[JInteger, JInteger]])
: Unit = {
if (acc.first != acc.oldFirst) {
// if there is an update, retract old value then emit new value.
if (acc.oldFirst != Int.MinValue) {
out.retract(JTuple2.of(acc.oldFirst, 1))
}
out.collect(JTuple2.of(acc.first, 1))
acc.oldFirst = acc.first
}
if (acc.second != acc.oldSecond) {
// if there is an update, retract old value then emit new value.
if (acc.oldSecond != Int.MinValue) {
out.retract(JTuple2.of(acc.oldSecond, 2))
}
out.collect(JTuple2.of(acc.second, 2))
acc.oldSecond = acc.second
}
}
}
// init table
val tab = ...
// use function
tab
.groupBy('key)
.flatAggregate(top2('a) as ('v, 'rank))
.select('key, 'v, 'rank)Best Practices for Implementing UDFs
The Table API and SQL code generation internally tries to work with primitive values as much as possible. A user-defined function can introduce much overhead through object creation, casting, and (un)boxing. Therefore, it is highly recommended to declare parameters and result types as primitive types instead of their boxed classes. Types.DATE and Types.TIME can also be represented as int. Types.TIMESTAMP can be represented as long.
We recommended that user-defined functions should be written by Java instead of Scala as Scala types pose a challenge for Flink’s type extractor.
Integrating UDFs with the Runtime
Sometimes it might be necessary for a user-defined function to get global runtime information or do some setup/clean-up work before the actual work. User-defined functions provide open() and close() methods that can be overridden and provide similar functionality as the methods in RichFunction of DataSet or DataStream API.
The open() method is called once before the evaluation method. The close() method after the last call to the evaluation method.
The open() method provides a FunctionContext that contains information about the context in which user-defined functions are executed, such as the metric group, the distributed cache files, or the global job parameters.
The following information can be obtained by calling the corresponding methods of FunctionContext:
| Method | Description |
|---|---|
getMetricGroup() |
Metric group for this parallel subtask. |
getCachedFile(name) |
Local temporary file copy of a distributed cache file. |
getJobParameter(name, defaultValue) |
Global job parameter value associated with given key. |
The following example snippet shows how to use FunctionContext in a scalar function for accessing a global job parameter:
public class HashCode extends ScalarFunction {
private int factor = 0;
@Override
public void open(FunctionContext context) throws Exception {
// access "hashcode_factor" parameter
// "12" would be the default value if parameter does not exist
factor = Integer.valueOf(context.getJobParameter("hashcode_factor", "12"));
}
public int eval(String s) {
return s.hashCode() * factor;
}
}
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
// set job parameter
Configuration conf = new Configuration();
conf.setString("hashcode_factor", "31");
env.getConfig().setGlobalJobParameters(conf);
// register the function
tableEnv.registerFunction("hashCode", new HashCode());
// use the function in Java Table API
myTable.select("string, string.hashCode(), hashCode(string)");
// use the function in SQL
tableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable");object hashCode extends ScalarFunction {
var hashcode_factor = 12
override def open(context: FunctionContext): Unit = {
// access "hashcode_factor" parameter
// "12" would be the default value if parameter does not exist
hashcode_factor = context.getJobParameter("hashcode_factor", "12").toInt
}
def eval(s: String): Int = {
s.hashCode() * hashcode_factor
}
}
val tableEnv = BatchTableEnvironment.create(env)
// use the function in Scala Table API
myTable.select('string, hashCode('string))
// register and use the function in SQL
tableEnv.registerFunction("hashCode", hashCode)
tableEnv.sqlQuery("SELECT string, HASHCODE(string) FROM MyTable")