General User-defined Functions
User-defined functions are important features, because they significantly extend the expressiveness of Python Table API programs.
NOTE: Python UDF execution requires Python version (3.5, 3.6, 3.7 or 3.8) with PyFlink installed. It’s required on both the client side and the cluster side.
Scalar Functions
It supports to use Python scalar functions in Python Table API programs. In order to define a Python scalar function,
one can extend the base class ScalarFunction in pyflink.table.udf and implement an evaluation method.
The behavior of a Python scalar function is defined by the evaluation method which is named eval.
The evaluation method can support variable arguments, such as eval(*args).
The following example shows how to define your own Python hash code function, register it in the TableEnvironment, and call it in a query. Note that you can configure your scalar function via a constructor before it is registered:
from pyflink.table.expressions import call
class HashCode(ScalarFunction):
def __init__(self):
self.factor = 12
def eval(self, s):
return hash(s) * self.factor
table_env = BatchTableEnvironment.create(env)
hash_code = udf(HashCode(), result_type=DataTypes.BIGINT())
# use the Python function in Python Table API
my_table.select(my_table.string, my_table.bigint, hash_code(my_table.bigint), call(hash_code, my_table.bigint))
# use the Python function in SQL API
table_env.create_temporary_function("hash_code", udf(HashCode(), result_type=DataTypes.BIGINT()))
table_env.sql_query("SELECT string, bigint, hash_code(bigint) FROM MyTable")It also supports to use Java/Scala scalar functions in Python Table API programs.
'''
Java code:
// The Java class must have a public no-argument constructor and can be founded in current Java classloader.
public class HashCode extends ScalarFunction {
private int factor = 12;
public int eval(String s) {
return s.hashCode() * factor;
}
}
'''
from pyflink.table.expressions import call
table_env = BatchTableEnvironment.create(env)
# register the Java function
table_env.create_java_temporary_function("hash_code", "my.java.function.HashCode")
# use the Java function in Python Table API
my_table.select(call('hash_code', my_table.string))
# use the Java function in SQL API
table_env.sql_query("SELECT string, bigint, hash_code(string) FROM MyTable")There are many ways to define a Python scalar function besides extending the base class ScalarFunction.
The following examples show the different ways to define a Python scalar function which takes two columns of
bigint as the input parameters and returns the sum of them as the result.
# option 1: extending the base class `ScalarFunction`
class Add(ScalarFunction):
def eval(self, i, j):
return i + j
add = udf(Add(), result_type=DataTypes.BIGINT())
# option 2: Python function
@udf(result_type=DataTypes.BIGINT())
def add(i, j):
return i + j
# option 3: lambda function
add = udf(lambda i, j: i + j, result_type=DataTypes.BIGINT())
# option 4: callable function
class CallableAdd(object):
def __call__(self, i, j):
return i + j
add = udf(CallableAdd(), result_type=DataTypes.BIGINT())
# option 5: partial function
def partial_add(i, j, k):
return i + j + k
add = udf(functools.partial(partial_add, k=1), result_type=DataTypes.BIGINT())
# register the Python function
table_env.create_temporary_function("add", add)
# use the function in Python Table API
my_table.select("add(a, b)")
# You can also use the Python function in Python Table API directly
my_table.select(add(my_table.a, my_table.b))Table Functions
Similar to a Python user-defined scalar function, a user-defined table function takes zero, one, or multiple scalar values as input parameters. However in contrast to a scalar function, it can return an arbitrary number of rows as output instead of a single value. The return type of a Python UDTF could be of types Iterable, Iterator or generator.
The following example shows how to define your own Python multi emit function, register it in the TableEnvironment, and call it in a query.
class Split(TableFunction):
def eval(self, string):
for s in string.split(" "):
yield s, len(s)
env = StreamExecutionEnvironment.get_execution_environment()
table_env = StreamTableEnvironment.create(env)
my_table = ... # type: Table, table schema: [a: String]
# register the Python Table Function
split = udtf(Split(), result_types=[DataTypes.STRING(), DataTypes.INT()])
# use the Python Table Function in Python Table API
my_table.join_lateral(split(my_table.a).alias("word, length"))
my_table.left_outer_join_lateral(split(my_table.a).alias("word, length"))
# use the Python Table function in SQL API
table_env.create_temporary_function("split", udtf(Split(), result_types=[DataTypes.STRING(), DataTypes.INT()]))
table_env.sql_query("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
table_env.sql_query("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")It also supports to use Java/Scala table functions in Python Table API programs.
'''
Java code:
// The generic type "Tuple2<String, Integer>" determines the schema of the returned table as (String, Integer).
// The java class must have a public no-argument constructor and can be founded in current java classloader.
public class Split extends TableFunction<Tuple2<String, Integer>> {
private String separator = " ";
public void eval(String str) {
for (String s : str.split(separator)) {
// use collect(...) to emit a row
collect(new Tuple2<String, Integer>(s, s.length()));
}
}
}
'''
from pyflink.table.expressions import call
env = StreamExecutionEnvironment.get_execution_environment()
table_env = StreamTableEnvironment.create(env)
my_table = ... # type: Table, table schema: [a: String]
# Register the java function.
table_env.create_java_temporary_function("split", "my.java.function.Split")
# Use the table function in the Python Table API. "alias" specifies the field names of the table.
my_table.join_lateral(call('split', my_table.a).alias("word, length")).select(my_table.a, col('word'), col('length'))
my_table.left_outer_join_lateral(call('split', my_table.a).alias("word, length")).select(my_table.a, col('word'), col('length'))
# Register the python function.
# Use the table function in SQL with LATERAL and TABLE keywords.
# CROSS JOIN a table function (equivalent to "join" in Table API).
table_env.sql_query("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
# LEFT JOIN a table function (equivalent to "left_outer_join" in Table API).
table_env.sql_query("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")Like Python scalar functions, you can use the above five ways to define Python TableFunctions.
Note The only difference is that the return type of Python Table Functions needs to be an iterable, iterator or generator.
# option 1: generator function
@udtf(result_types=DataTypes.BIGINT())
def generator_func(x):
yield 1
yield 2
# option 2: return iterator
@udtf(result_types=DataTypes.BIGINT())
def iterator_func(x):
return range(5)
# option 3: return iterable
@udtf(result_types=DataTypes.BIGINT())
def iterable_func(x):
result = [1, 2, 3]
return resultAggregate Functions
A user-defined aggregate function (UDAGG) maps scalar values of multiple rows to a new scalar value.
NOTE: Currently the general user-defined aggregate function is only supported in the GroupBy aggregation of the blink planner in streaming mode. For batch mode or windowed aggregation, it’s currently not supported and it is recommended to use the Vectorized Aggregate Functions.
The behavior of an aggregate function is centered around the concept of an accumulator. The accumulator is an intermediate data structure that stores the aggregated values until a final aggregation result is computed.
For each set of rows that need to be aggregated, the runtime will create an empty accumulator by calling
create_accumulator(). Subsequently, the accumulate(...) method of the aggregate function will be called for each input
row to update the accumulator. Currently after each row has been processed, the get_value(...) method of the
aggregate function will be called to compute the aggregated result.
The following example illustrates the aggregation process:
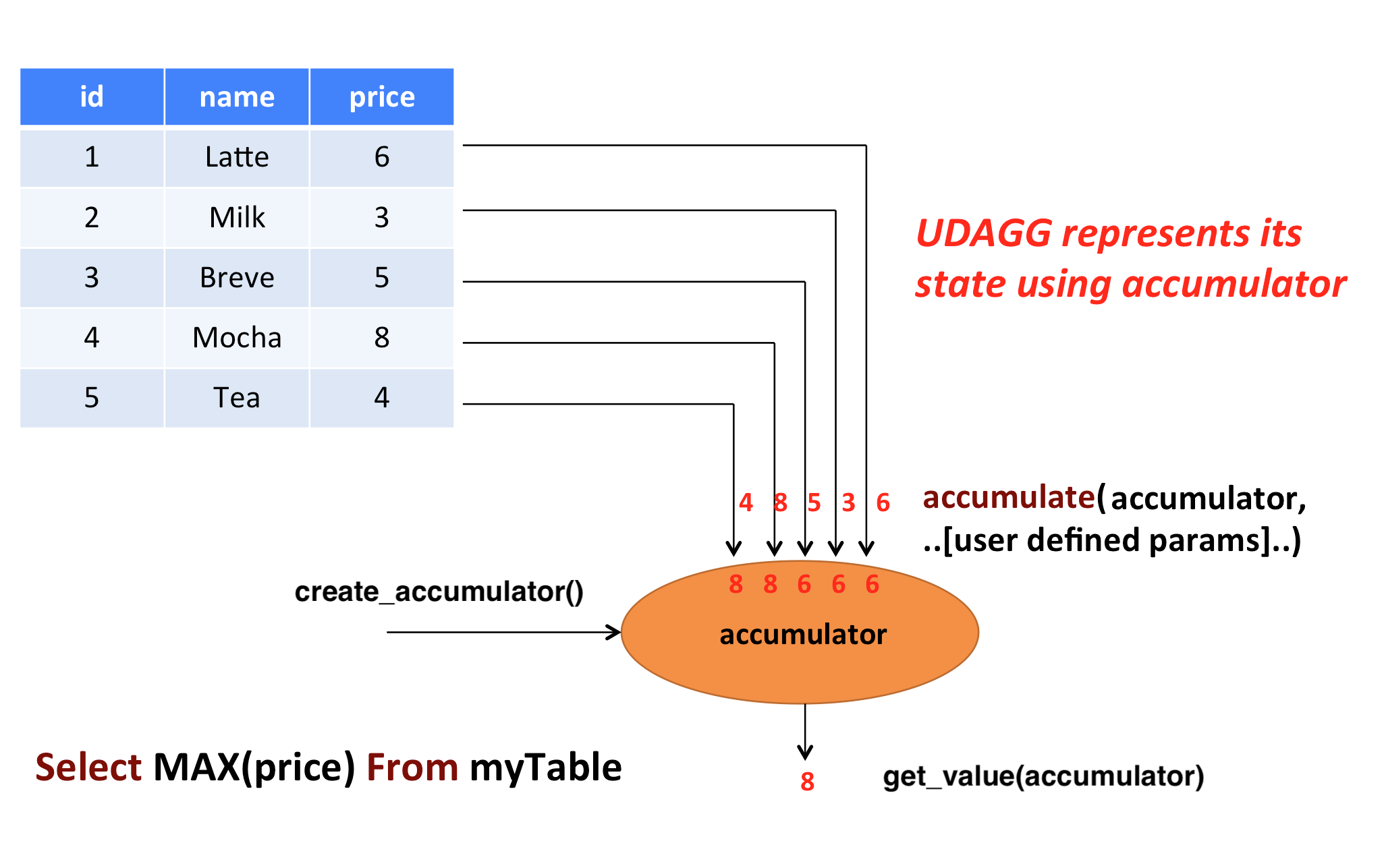
In the above example, we assume a table that contains data about beverages. The table consists of three columns (id, name,
and price) and 5 rows. We would like to find the highest price of all beverages in the table, i.e., perform
a max() aggregation.
In order to define an aggregate function, one has to extend the base class AggregateFunction in
pyflink.table and implement the evaluation method named accumulate(...).
The result type and accumulator type of the aggregate function can be specified by one of the following two approaches:
- Implement the method named
get_result_type()andget_accumulator_type(). - Wrap the function instance with the decorator
udafinpyflink.table.udfand specify the parametersresult_typeandaccumulator_type.
The following example shows how to define your own aggregate function and call it in a query.
from pyflink.common import Row
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import AggregateFunction, DataTypes, StreamTableEnvironment
from pyflink.table.expressions import call
from pyflink.table.udf import udaf
class WeightedAvg(AggregateFunction):
def create_accumulator(self):
# Row(sum, count)
return Row(0, 0)
def get_value(self, accumulator):
if accumulator[1] == 0:
return None
else:
return accumulator[0] / accumulator[1]
def accumulate(self, accumulator, value, weight):
accumulator[0] += value * weight
accumulator[1] += weight
def retract(self, accumulator, value, weight):
accumulator[0] -= value * weight
accumulator[1] -= weight
def get_result_type(self):
return DataTypes.BIGINT()
def get_accumulator_type(self):
return DataTypes.ROW([
DataTypes.FIELD("f0", DataTypes.BIGINT()),
DataTypes.FIELD("f1", DataTypes.BIGINT())])
env = StreamExecutionEnvironment.get_execution_environment()
table_env = StreamTableEnvironment.create(env)
# the result type and accumulator type can also be specified in the udaf decorator:
# weighted_avg = udaf(WeightedAvg(), result_type=DataTypes.BIGINT(), accumulator_type=...)
weighted_avg = udaf(WeightedAvg())
t = table_env.from_elements([(1, 2, "Lee"),
(3, 4, "Jay"),
(5, 6, "Jay"),
(7, 8, "Lee")]).alias("value", "count", "name")
# call function "inline" without registration in Table API
result = t.group_by(t.name).select(weighted_avg(t.value, t.count).alias("avg")).to_pandas()
print(result)
# register function
table_env.create_temporary_function("weighted_avg", WeightedAvg())
# call registered function in Table API
result = t.group_by(t.name).select(call("weighted_avg", t.value, t.count).alias("avg")).to_pandas()
print(result)
# register table
table_env.create_temporary_view("source", t)
# call registered function in SQL
result = table_env.sql_query(
"SELECT weighted_avg(`value`, `count`) AS avg FROM source GROUP BY name").to_pandas()
print(result)The accumulate(...) method of our WeightedAvg class takes three input arguments. The first one is the accumulator
and the other two are user-defined inputs. In order to calculate a weighted average value, the accumulator
needs to store the weighted sum and count of all the data that have already been accumulated. In our example, we
use a Row object as the accumulator. Accumulators will be managed
by Flink’s checkpointing mechanism and are restored in case of failover to ensure exactly-once semantics.
Mandatory and Optional Methods
The following methods are mandatory for each AggregateFunction:
create_accumulator()accumulate(...)get_value(...)
The following methods of AggregateFunction are required depending on the use case:
retract(...)is required when there are operations that could generate retraction messages before the current aggregation operation, e.g. group aggregate, outer join.
This method is optional, but it is strongly recommended to be implemented to ensure the UDAF can be used in any use case.get_result_type()andget_accumulator_type()is required if the result type and accumulator type would not be specified in theudafdecorator.
ListView and MapView
If an accumulator needs to store large amounts of data, pyflink.table.ListView and pyflink.table.MapView
could be used instead of list and dict. These two data structures provide the similar functionalities as list and dict,
however usually having better performance by leveraging Flink’s state backend to eliminate unnecessary state access.
You can use them by declaring DataTypes.LIST_VIEW(...) and DataTypes.MAP_VIEW(...) in the accumulator type, e.g.:
from pyflink.table import ListView
class ListViewConcatAggregateFunction(AggregateFunction):
def get_value(self, accumulator):
# the ListView is iterable
return accumulator[1].join(accumulator[0])
def create_accumulator(self):
return Row(ListView(), '')
def accumulate(self, accumulator, *args):
accumulator[1] = args[1]
# the ListView support add, clear and iterate operations.
accumulator[0].add(args[0])
def get_accumulator_type(self):
return DataTypes.ROW([
# declare the first column of the accumulator as a string ListView.
DataTypes.FIELD("f0", DataTypes.LIST_VIEW(DataTypes.STRING())),
DataTypes.FIELD("f1", DataTypes.BIGINT())])
def get_result_type(self):
return DataTypes.STRING()Currently there are 2 limitations to use the ListView and MapView:
- The accumulator must be a
Row. - The
ListViewandMapViewmust be the first level children of theRowaccumulator.
Please refer to the documentation of the corresponding classes for more information about this advanced feature.
NOTE: For reducing the data transmission cost between Python UDF worker and Java process caused by accessing the data in Flink states(e.g. accumulators and data views),
there is a cached layer between the raw state handler and the Python state backend. You can adjust the values of these configuration options to change the behavior of the cache layer for best performance:
python.state.cache-size, python.map-state.read-cache-size, python.map-state.write-cache-size, python.map-state.iterate-response-batch-size.
For more details please refer to the Python Configuration Documentation.