Flink 操作场景
Apache Flink 可以以多种方式在不同的环境中部署,抛开这种多样性而言,Flink 集群的基本构建方式和操作原则仍然是相同的。
在这篇文章里,你将会学习如何管理和运行 Flink 任务,了解如何部署和监控应用程序、Flink 如何从失败作业中进行恢复,同时你还会学习如何执行一些日常操作任务,如升级和扩容。
场景说明
这篇文章中的所有操作都是基于如下两个集群进行的: Flink Session Cluster 以及一个 Kafka 集群, 我们会在下文带领大家一起搭建这两个集群。
一个 Flink 集群总是包含一个 JobManager 以及一个或多个 Flink TaskManager。JobManager 负责处理 Job 提交、 Job 监控以及资源管理。Flink TaskManager 运行 worker 进程, 负责实际任务 Tasks 的执行,而这些任务共同组成了一个 Flink Job。 在这篇文章中, 我们会先运行一个 TaskManager,接下来会扩容到多个 TaskManager。 另外,这里我们会专门使用一个 client 容器来提交 Flink Job, 后续还会使用该容器执行一些操作任务。需要注意的是,Flink 集群的运行并不需要依赖 client 容器, 我们这里引入只是为了使用方便。
这里的 Kafka 集群由一个 Zookeeper 服务端和一个 Kafka Broker 组成。

一开始,我们会往 JobManager 提交一个名为 Flink 事件计数 的 Job,此外,我们还创建了两个 Kafka Topic:input 和 output。

该 Job 负责从 input topic 消费点击事件 ClickEvent,每个点击事件都包含一个 timestamp 和一个 page 属性。
这些事件将按照 page 属性进行分组,然后按照每 15s 窗口 windows 进行统计,
最终结果输出到 output topic 中。
总共有 6 种不同的 page 属性,针对特定 page,我们会按照每 15s 产生 1000 个点击事件的速率生成数据。 因此,针对特定 page,该 Flink job 应该能在每个窗口中输出 1000 个该 page 的点击数据。
环境搭建
环境搭建只需要几步就可以完成,我们将会带你过一遍必要的操作命令, 并说明如何验证我们正在操作的一切都是运行正常的。
你需要在自己的主机上提前安装好 docker (1.12+) 和 docker-compose (2.1+)。
我们所使用的配置文件位于 flink-playgrounds 仓库中, 检出该仓库并启动 docker 环境:
git clone --branch release-1.12 https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker-compose build
docker-compose up -d接下来可以执行如下命令来查看 Docker 容器:
docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------------------------------------------------------------
operations-playground_clickevent-generator_1 /docker-entrypoint.sh java ... Up 6123/tcp, 8081/tcp
operations-playground_client_1 /docker-entrypoint.sh flin ... Exit 0
operations-playground_jobmanager_1 /docker-entrypoint.sh jobm ... Up 6123/tcp, 0.0.0.0:8081->8081/tcp
operations-playground_kafka_1 start-kafka.sh Up 0.0.0.0:9094->9094/tcp
operations-playground_taskmanager_1 /docker-entrypoint.sh task ... Up 6123/tcp, 8081/tcp
operations-playground_zookeeper_1 /bin/sh -c /usr/sbin/sshd ... Up 2181/tcp, 22/tcp, 2888/tcp, 3888/tcp从上面的信息可以看出 client 容器已成功提交了 Flink Job (Exit 0),
同时包含数据生成器在内的所有集群组件都处于运行中状态 (Up)。
你可以执行如下命令停止 docker 环境:
docker-compose down -v环境讲解
在这个搭建好的环境中你可以尝试和验证很多事情,在下面的两个部分中我们将向你展示如何与 Flink 集群进行交互以及演示并讲解 Flink 的一些核心特性。
Flink WebUI 界面
观察Flink集群首先想到的就是 Flink WebUI 界面:打开浏览器并访问 http://localhost:8081,如果一切正常,你将会在界面上看到一个 TaskManager 和一个处于 “RUNNING” 状态的名为 Click Event Count 的 Job。
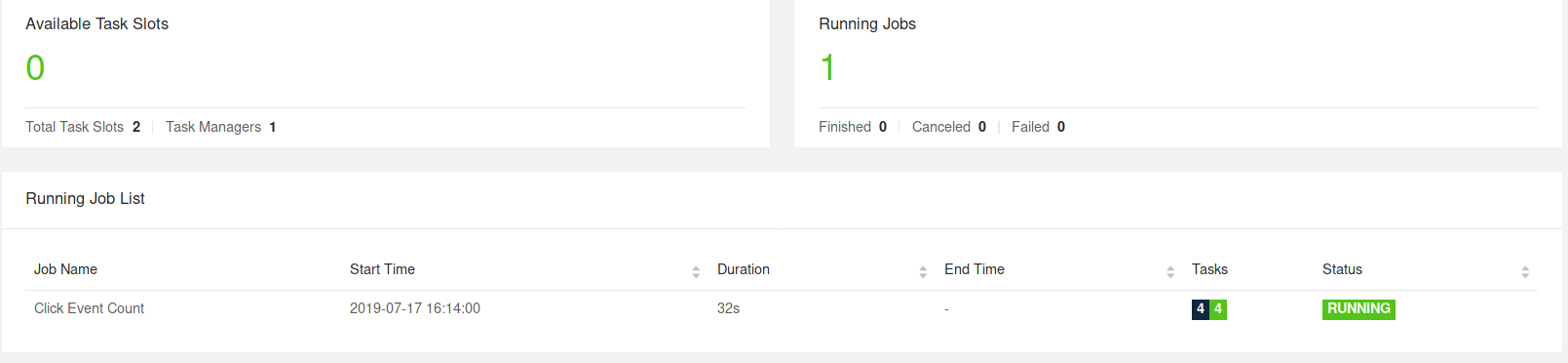
Flink WebUI 界面包含许多关于 Flink 集群以及运行在其上的 Jobs 的有用信息,比如:JobGraph、Metrics、Checkpointing Statistics、TaskManager Status 等等。
日志
JobManager
JobManager 日志可以通过 docker-compose 命令进行查看。
docker-compose logs -f jobmanagerJobManager 刚启动完成之时,你会看到很多关于 checkpoint completion (检查点完成)的日志。
TaskManager
TaskManager 日志也可以通过同样的方式进行查看。
docker-compose logs -f taskmanagerTaskManager 刚启动完成之时,你同样会看到很多关于 checkpoint completion (检查点完成)的日志。
Flink CLI
Flink CLI 相关命令可以在 client 容器内进行使用。
比如,想查看 Flink CLI 的 help 命令,可以通过如下方式进行查看:
docker-compose run --no-deps client flink --helpFlink REST API
Flink REST API 可以通过本机的
localhost:8081 进行访问,也可以在 client 容器中通过 jobmanager:8081 进行访问。
比如,通过如下命令可以获取所有正在运行中的 Job:
curl localhost:8081/jobsKafka Topics
可以运行如下命令查看 Kafka Topics 中的记录:
//input topic (1000 records/s)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
//output topic (24 records/min)
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output核心特性探索
到目前为止,你已经学习了如何与 Flink 以及 Docker 容器进行交互,现在让我们看一些常用的操作命令。 本节中的各部分命令不需要按任何特定的顺序执行,这些命令大部分都可以通过 CLI 或 RESTAPI 执行。
获取所有运行中的 Job
命令
docker-compose run --no-deps client flink list预期输出
Waiting for response...
------------------ Running/Restarting Jobs -------------------
16.07.2019 16:37:55 : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------
No scheduled jobs.请求
curl localhost:8081/jobs预期响应 (结果已格式化)
{
"jobs": [
{
"id": "<job-id>",
"status": "RUNNING"
}
]
}一旦 Job 提交,Flink 会默认为其生成一个 JobID,后续对该 Job 的 所有操作(无论是通过 CLI 还是 REST API)都需要带上 JobID。
Job 失败与恢复
在 Job (部分)失败的情况下,Flink 对事件处理依然能够提供精确一次的保障, 在本节中你将会观察到并能够在某种程度上验证这种行为。
Step 1: 观察输出
如前文所述,事件以特定速率生成,刚好使得每个统计窗口都包含确切的 1000 条记录。 因此,你可以实时查看 output topic 的输出,确定失败恢复后所有的窗口依然输出正确的统计数字, 以此来验证 Flink 在 TaskManager 失败时能够成功恢复,而且不丢失数据、不产生数据重复。
为此,通过控制台命令消费 output topic,保持消费直到 Job 从失败中恢复 (Step 3)。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic outputStep 2: 模拟失败
为了模拟部分失败故障,你可以 kill 掉一个 TaskManager,这种失败行为在生产环境中就相当于 TaskManager 进程挂掉、TaskManager 机器宕机或者从框架或用户代码中抛出的一个临时异常(例如,由于外部资源暂时不可用)而导致的失败。
docker-compose kill taskmanager几秒钟后,JobManager 就会感知到 TaskManager 已失联,接下来它会
取消 Job 运行并且立即重新提交该 Job 以进行恢复。
当 Job 重启后,所有的任务都会处于 SCHEDULED 状态,如以下截图中紫色方格所示:
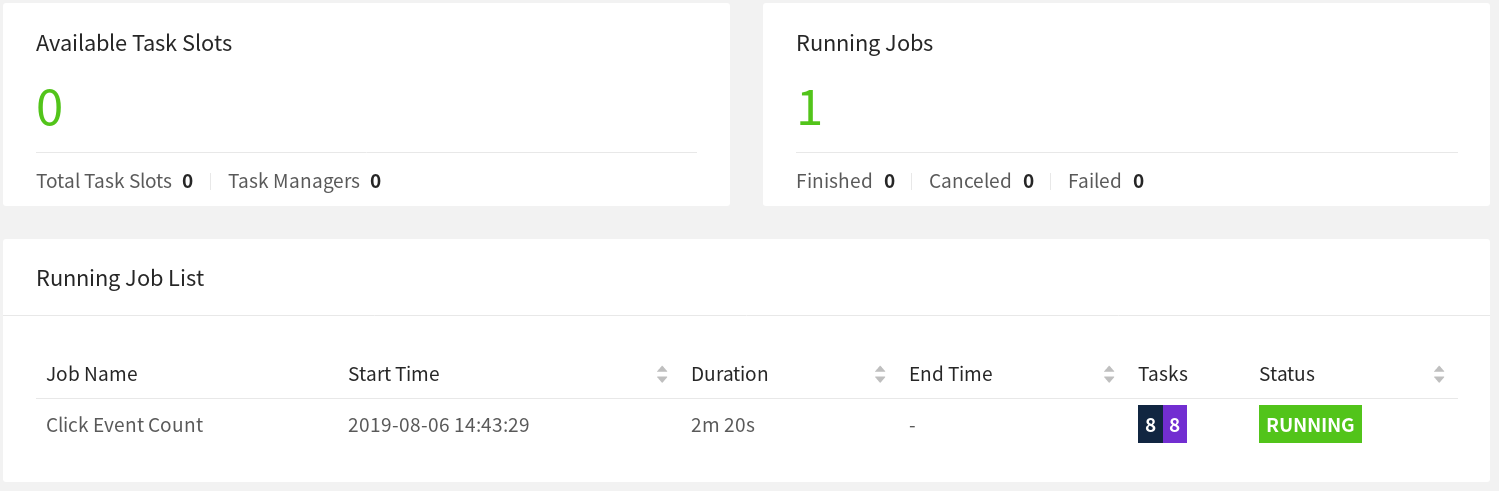
注意:虽然 Job 的所有任务都处于 SCHEDULED 状态,但整个 Job 的状态却显示为 RUNNING。
此时,由于 TaskManager 提供的 TaskSlots 资源不够用,Job 的所有任务都不能成功转为
RUNNING 状态,直到有新的 TaskManager 可用。在此之前,该 Job 将经历一个取消和重新提交
不断循环的过程。
与此同时,数据生成器 (data generator) 一直不断地往 input topic 中生成 ClickEvent 事件,在生产环境中也经常出现这种 Job 挂掉但源头还在不断产生数据的情况。
Step 3: 失败恢复
一旦 TaskManager 重启成功,它将会重新连接到 JobManager。
docker-compose up -d taskmanager当 TaskManager 注册成功后,JobManager 就会将处于 SCHEDULED 状态的所有任务调度到该 TaskManager
的可用 TaskSlots 中运行,此时所有的任务将会从失败前最近一次成功的
checkpoint 进行恢复,
一旦恢复成功,它们的状态将转变为 RUNNING。
接下来该 Job 将快速处理 Kafka input 事件的全部积压(在 Job 中断期间累积的数据),
并以更快的速度(>24 条记录/分钟)产生输出,直到它追上 kafka 的 lag 延迟为止。
此时观察 output topic 输出,
你会看到在每一个时间窗口中都有按 page 进行分组的记录,而且计数刚好是 1000。
由于我们使用的是 FlinkKafkaProducer “至少一次”模式,因此你可能会看到一些记录重复输出多次。
注意:在大部分生产环境中都需要一个资源管理器 (Kubernetes、Yarn,、Mesos)对 失败的 Job 进行自动重启。
Job 升级与扩容
升级 Flink 作业一般都需要两步:第一,使用 Savepoint 优雅地停止 Flink Job。 Savepoint 是整个应用程序状态的一次快照(类似于 checkpoint ),该快照是在一个明确定义的、全局一致的时间点生成的。第二,从 Savepoint 恢复启动待升级的 Flink Job。 在此,“升级”包含如下几种含义:
- 配置升级(比如 Job 并行度修改)
- Job 拓扑升级(比如添加或者删除算子)
- Job 的用户自定义函数升级
在开始升级之前,你可能需要实时查看 Output topic 输出, 以便观察在升级过程中没有数据丢失或损坏。
docker-compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic outputStep 1: 停止 Job
要优雅停止 Job,需要使用 JobID 通过 CLI 或 REST API 调用 “stop” 命令。 JobID 可以通过获取所有运行中的 Job 接口或 Flink WebUI 界面获取,拿到 JobID 后就可以继续停止作业了:
命令
docker-compose run --no-deps client flink stop <job-id>预期输出
Suspending job "<job-id>" with a savepoint.
Suspended job "<job-id>" with a savepoint.Savepoint 已保存在 state.savepoint.dir 指定的路径中,该配置在 flink-conf.yaml
中定义,flink-conf.yaml 挂载在本机的 /tmp/flink-savepoints-directory/ 目录下。
在下一步操作中我们会用到这个 Savepoint 路径,如果我们是通过 REST API 操作的,
那么 Savepoint 路径会随着响应结果一起返回,我们可以直接查看文件系统来确认 Savepoint 保存情况。
命令
ls -lia /tmp/flink-savepoints-directory预期输出
total 0
17 drwxr-xr-x 3 root root 60 17 jul 17:05 .
2 drwxrwxrwt 135 root root 3420 17 jul 17:09 ..
1002 drwxr-xr-x 2 root root 140 17 jul 17:05 savepoint-<short-job-id>-<uuid>请求
# 停止 Job
curl -X POST localhost:8081/jobs/<job-id>/stop -d '{"drain": false}'预期响应 (结果已格式化)
{
"request-id": "<trigger-id>"
}请求
# 检查停止结果并获取 savepoint 路径
curl localhost:8081/jobs/<job-id>/savepoints/<trigger-id>预期响应 (结果已格式化)
{
"status": {
"id": "COMPLETED"
},
"operation": {
"location": "<savepoint-path>"
}Step 2a: 重启 Job (不作任何变更)
现在你可以从这个 Savepoint 重新启动待升级的 Job,为了简单起见,不对该 Job 作任何变更就直接重启。
命令
docker-compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time预期输出
Starting execution of program
Job has been submitted with JobID <job-id>请求
# 从客户端容器上传 JAR
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload预期响应 (结果已格式化)
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}请求
# 提交 Job
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'预期响应 (结果已格式化)
{
"jobid": "<job-id>"
}一旦该 Job 再次处于 RUNNING 状态,你将从 output Topic 中看到数据在快速输出,
因为刚启动的 Job 正在处理停止期间积压的大量数据。另外,你还会看到在升级期间
没有产生任何数据丢失:所有窗口都在输出 1000。
Step 2b: 重启 Job (修改并行度)
在从 Savepoint 重启 Job 之前,你还可以通过修改并行度来达到扩容 Job 的目的。
命令
docker-compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time预期输出
Starting execution of program
Job has been submitted with JobID <job-id>请求
# Uploading the JAR from the Client container
docker-compose run --no-deps client curl -X POST -H "Expect:" \
-F "jarfile=@/opt/ClickCountJob.jar" http://jobmanager:8081/jars/upload预期响应 (结果已格式化)
{
"filename": "/tmp/flink-web-<uuid>/flink-web-upload/<jar-id>",
"status": "success"
}请求
# 提交 Job
curl -X POST http://localhost:8081/jars/<jar-id>/run \
-d '{"parallelism": 3, "programArgs": "--bootstrap.servers kafka:9092 --checkpointing --event-time", "savepointPath": "<savepoint-path>"}'预期响应 (结果已格式化)
{
"jobid": "<job-id>"
}现在 Job 已重新提交,但由于我们提高了并行度所以导致 TaskSlots 不够用(1 个 TaskSlot 可用,总共需要 3 个),最终 Job 会重启失败。通过如下命令:
docker-compose scale taskmanager=2你可以向 Flink 集群添加第二个 TaskManager(为 Flink 集群提供 2 个 TaskSlots 资源), 它会自动向 JobManager 注册,TaskManager 注册完成后,Job 会再次处于 “RUNNING” 状态。
一旦 Job 再次运行起来,从 output Topic 的输出中你会看到在扩容期间数据依然没有丢失: 所有窗口的计数都正好是 1000。
查询 Job 指标
可以通过 JobManager 提供的 REST API 来获取系统和用户指标
具体请求方式取决于我们想查询哪类指标,Job 相关的指标分类可通过 jobs/<job-id>/metrics
获得,而要想查询某类指标的具体值则可以在请求地址后跟上 get 参数。
请求
curl "localhost:8081/jobs/<jod-id>/metrics?get=lastCheckpointSize"预期响应 (结果已格式化且去除了占位符)
[
{
"id": "lastCheckpointSize",
"value": "9378"
}
]REST API 不仅可以用于查询指标,还可以用于获取正在运行中的 Job 详细信息。
请求
# 可以从结果中获取感兴趣的 vertex-id
curl localhost:8081/jobs/<jod-id>预期响应 (结果已格式化)
{
"jid": "<job-id>",
"name": "Click Event Count",
"isStoppable": false,
"state": "RUNNING",
"start-time": 1564467066026,
"end-time": -1,
"duration": 374793,
"now": 1564467440819,
"timestamps": {
"CREATED": 1564467066026,
"FINISHED": 0,
"SUSPENDED": 0,
"FAILING": 0,
"CANCELLING": 0,
"CANCELED": 0,
"RECONCILING": 0,
"RUNNING": 1564467066126,
"FAILED": 0,
"RESTARTING": 0
},
"vertices": [
{
"id": "<vertex-id>",
"name": "ClickEvent Source",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066423,
"end-time": -1,
"duration": 374396,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 0,
"read-bytes-complete": true,
"write-bytes": 5033461,
"write-bytes-complete": true,
"read-records": 0,
"read-records-complete": true,
"write-records": 166351,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "Timestamps/Watermarks",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066441,
"end-time": -1,
"duration": 374378,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5066280,
"read-bytes-complete": true,
"write-bytes": 5033496,
"write-bytes-complete": true,
"read-records": 166349,
"read-records-complete": true,
"write-records": 166349,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEvent Counter",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066469,
"end-time": -1,
"duration": 374350,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 5085332,
"read-bytes-complete": true,
"write-bytes": 316,
"write-bytes-complete": true,
"read-records": 166305,
"read-records-complete": true,
"write-records": 6,
"write-records-complete": true
}
},
{
"id": "<vertex-id>",
"name": "ClickEventStatistics Sink",
"parallelism": 2,
"status": "RUNNING",
"start-time": 1564467066476,
"end-time": -1,
"duration": 374343,
"tasks": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 2,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"metrics": {
"read-bytes": 20668,
"read-bytes-complete": true,
"write-bytes": 0,
"write-bytes-complete": true,
"read-records": 6,
"read-records-complete": true,
"write-records": 0,
"write-records-complete": true
}
}
],
"status-counts": {
"CREATED": 0,
"FINISHED": 0,
"DEPLOYING": 0,
"RUNNING": 4,
"CANCELING": 0,
"FAILED": 0,
"CANCELED": 0,
"RECONCILING": 0,
"SCHEDULED": 0
},
"plan": {
"jid": "<job-id>",
"name": "Click Event Count",
"nodes": [
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEventStatistics Sink",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Counter",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "HASH",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "Timestamps/Watermarks",
"inputs": [
{
"num": 0,
"id": "<vertex-id>",
"ship_strategy": "FORWARD",
"exchange": "pipelined_bounded"
}
],
"optimizer_properties": {}
},
{
"id": "<vertex-id>",
"parallelism": 2,
"operator": "",
"operator_strategy": "",
"description": "ClickEvent Source",
"optimizer_properties": {}
}
]
}
}请查阅 REST API 参考,该参考上有完整的指标查询接口信息,包括如何查询不同种类的指标(例如 TaskManager 指标)。
延伸拓展
你可能已经注意到了,Click Event Count 这个 Job 在启动时总是会带上 --checkpointing 和 --event-time 两个参数,
如果我们去除这两个参数,那么 Job 的行为也会随之改变。
-
--checkpointing参数开启了 checkpoint 配置,checkpoint 是 Flink 容错机制的重要保证。 如果你没有开启 checkpoint,那么在 Job 失败与恢复这一节中,你将会看到数据丢失现象发生。 -
--event-time参数开启了 Job 的 事件时间 机制,该机制会使用ClickEvent自带的时间戳进行统计。 如果不指定该参数,Flink 将结合当前机器时间使用事件处理时间进行统计。如此一来,每个窗口计数将不再是准确的 1000 了。
Click Event Count 这个 Job 还有另外一个选项,该选项默认是关闭的,你可以在 client 容器的 docker-compose.yaml 文件中添加该选项从而观察该 Job 在反压下的表现,该选项描述如下: