This documentation is for an out-of-date version of Apache Flink. We recommend you use the latest stable version.
FileSystem
FileSystem #
This connector provides a unified Source and Sink for BATCH and STREAMING that reads or writes (partitioned) files to file systems
supported by the Flink FileSystem abstraction. This filesystem
connector provides the same guarantees for both BATCH and STREAMING and is designed to provide exactly-once semantics for STREAMING execution.
The connector supports reading and writing a set of files from any (distributed) file system (e.g. POSIX, S3, HDFS) with a format (e.g., Avro, CSV, Parquet), and produces a stream or records.
File Source #
The File Source is based on the Source API,
a unified data source that reads files - both in batch and in streaming mode.
It is divided into the following two parts: SplitEnumerator and SourceReader.
SplitEnumeratoris responsible for discovering and identifying the files to read and assigns them to theSourceReader.SourceReaderrequests the files it needs to process and reads the file from the filesystem.
You will need to combine the File Source with a format, which allows you to parse CSV, decode AVRO, or read Parquet columnar files.
Bounded and Unbounded Streams #
A bounded File Source lists all files (via SplitEnumerator - a recursive directory list with filtered-out hidden files) and reads them all.
An unbounded File Source is created when configuring the enumerator for periodic file discovery.
In this case, the SplitEnumerator will enumerate like the bounded case but, after a certain interval, repeats the enumeration.
For any repeated enumeration, the SplitEnumerator filters out previously detected files and only sends new ones to the SourceReader.
Usage #
You can start building a File Source via one of the following API calls:
// reads the contents of a file from a file stream.
FileSource.forRecordStreamFormat(StreamFormat,Path...)
// reads batches of records from a file at a time
FileSource.forBulkFileFormat(BulkFormat,Path...)
This creates a FileSource.FileSourceBuilder on which you can configure all the properties of the File Source.
For the bounded/batch case, the File Source processes all files under the given path(s). For the continuous/streaming case, the source periodically checks the paths for new files and will start reading those.
When you start creating a File Source (via the FileSource.FileSourceBuilder created through one of the above-mentioned methods),
the source is in bounded/batch mode by default. You can call AbstractFileSource.AbstractFileSourceBuilder.monitorContinuously(Duration)
to put the source into continuous streaming mode.
final FileSource<String> source =
FileSource.forRecordStreamFormat(...)
.monitorContinuously(Duration.ofMillis(5))
.build();
Format Types #
The reading of each file happens through file readers defined by file formats. These define the parsing logic for the contents of the file. There are multiple classes that the source supports. The interfaces are a tradeoff between simplicity of implementation and flexibility/efficiency.
-
A
StreamFormatreads the contents of a file from a file stream. It is the simplest format to implement, and provides many features out-of-the-box (like checkpointing logic) but is limited in the optimizations it can apply (such as object reuse, batching, etc.). -
A
BulkFormatreads batches of records from a file at a time. It is the most “low level” format to implement, but offers the greatest flexibility to optimize the implementation.
TextLine Format #
A StreamFormat reader formats text lines from a file.
The reader uses Java’s built-in InputStreamReader to decode the byte stream using
various supported charset encodings.
This format does not support optimized recovery from checkpoints. On recovery, it will re-read
and discard the number of lines that were processed before the last checkpoint. This is due to
the fact that the offsets of lines in the file cannot be tracked through the charset decoders
with their internal buffering of stream input and charset decoder state.
SimpleStreamFormat Abstract Class #
This is a simple version of StreamFormat for formats that are not splittable.
Custom reads of Array or File can be done by implementing SimpleStreamFormat:
private static final class ArrayReaderFormat extends SimpleStreamFormat<byte[]> {
private static final long serialVersionUID = 1L;
@Override
public Reader<byte[]> createReader(Configuration config, FSDataInputStream stream)
throws IOException {
return new ArrayReader(stream);
}
@Override
public TypeInformation<byte[]> getProducedType() {
return PrimitiveArrayTypeInfo.BYTE_PRIMITIVE_ARRAY_TYPE_INFO;
}
}
final FileSource<byte[]> source =
FileSource.forRecordStreamFormat(new ArrayReaderFormat(), path).build();
An example of a SimpleStreamFormat is CsvReaderFormat. It can be initialized like this:
CsvReaderFormat<SomePojo> csvFormat = CsvReaderFormat.forPojo(SomePojo.class);
FileSource<SomePojo> source =
FileSource.forRecordStreamFormat(csvFormat, Path.fromLocalFile(...)).build();
The schema for CSV parsing, in this case, is automatically derived based on the fields of the SomePojo class using the Jackson library. (Note: you might need to add @JsonPropertyOrder({field1, field2, ...}) annotation to your class definition with the fields order exactly matching those of the CSV file columns).
If you need more fine-grained control over the CSV schema or the parsing options, use the more low-level forSchema static factory method of CsvReaderFormat:
CsvReaderFormat<T> forSchema(CsvMapper mapper,
CsvSchema schema,
TypeInformation<T> typeInformation)
Bulk Format #
The BulkFormat reads and decodes batches of records at a time. Examples of bulk formats
are formats like ORC or Parquet.
The outer BulkFormat class acts mainly as a configuration holder and factory for the
reader. The actual reading is done by the BulkFormat.Reader, which is created in the
BulkFormat#createReader(Configuration, FileSourceSplit) method. If a bulk reader is
created based on a checkpoint during checkpointed streaming execution, then the reader is
re-created in the BulkFormat#restoreReader(Configuration, FileSourceSplit) method.
A SimpleStreamFormat can be turned into a BulkFormat by wrapping it in a StreamFormatAdapter:
BulkFormat<SomePojo, FileSourceSplit> bulkFormat =
new StreamFormatAdapter<>(CsvReaderFormat.forPojo(SomePojo.class));
Customizing File Enumeration #
/**
* A FileEnumerator implementation for hive source, which generates splits based on
* HiveTablePartition.
*/
public class HiveSourceFileEnumerator implements FileEnumerator {
// reference constructor
public HiveSourceFileEnumerator(...) {
...
}
/***
* Generates all file splits for the relevant files under the given paths. The {@code
* minDesiredSplits} is an optional hint indicating how many splits would be necessary to
* exploit parallelism properly.
*/
@Override
public Collection<FileSourceSplit> enumerateSplits(Path[] paths, int minDesiredSplits)
throws IOException {
// createInputSplits:splitting files into fragmented collections
return new ArrayList<>(createInputSplits(...));
}
...
/***
* A factory to create HiveSourceFileEnumerator.
*/
public static class Provider implements FileEnumerator.Provider {
...
@Override
public FileEnumerator create() {
return new HiveSourceFileEnumerator(...);
}
}
}
// use the customizing file enumeration
new HiveSource<>(
...,
new HiveSourceFileEnumerator.Provider(
partitions != null ? partitions : Collections.emptyList(),
new JobConfWrapper(jobConf)),
...);
Current Limitations #
Watermarking does not work very well for large backlogs of files. This is because watermarks eagerly advance within a file, and the next file might contain data later than the watermark.
For Unbounded File Sources, the enumerator currently remembers paths of all already processed files, which is a state that can, in some cases, grow rather large. There are plans to add a compressed form of tracking already processed files in the future (for example, by keeping modification timestamps below boundaries).
Behind the Scenes #
If you are interested in how File Source works through the new data source API design, you may want to read this part as a reference. For details about the new data source API, check out the documentation on data sources and FLIP-27 for more descriptive discussions.
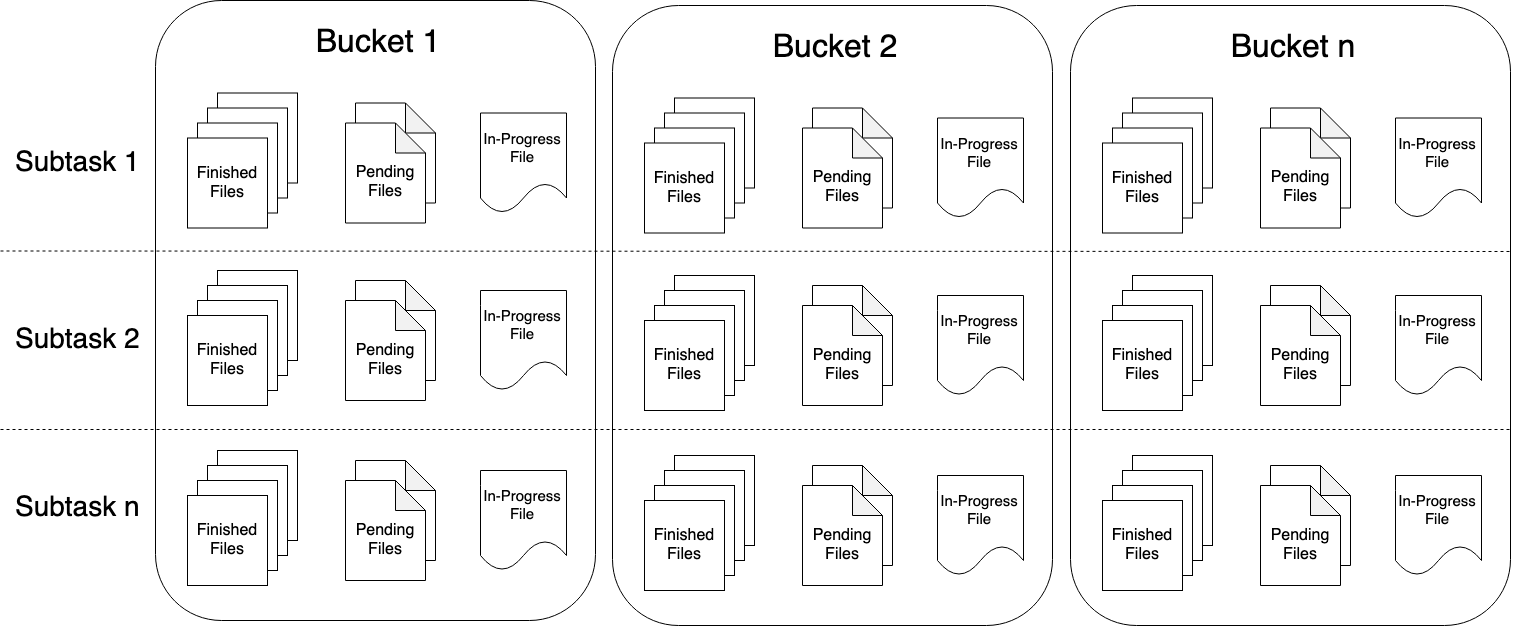
File Sink #
The file sink writes incoming data into buckets. Given that the incoming streams can be unbounded, data in each bucket is organized into part files of finite size. The bucketing behaviour is fully configurable with a default time-based bucketing where we start writing a new bucket every hour. This means that each resulting bucket will contain files with records received during 1 hour intervals from the stream.
Data within the bucket directories is split into part files. Each bucket will contain at least one part file for
each subtask of the sink that has received data for that bucket. Additional part files will be created according to the configurable
rolling policy. For Row-encoded Formats (see File Formats) the default policy rolls part files based
on size, a timeout that specifies the maximum duration for which a file can be open, and a maximum inactivity
timeout after which the file is closed. For Bulk-encoded Formats we roll on every checkpoint and the user can
specify additional conditions based on size or time.
IMPORTANT: Checkpointing needs to be enabled when using theFileSinkinSTREAMINGmode. Part files can only be finalized on successful checkpoints. If checkpointing is disabled, part files will forever stay in thein-progressor thependingstate, and cannot be safely read by downstream systems.
Format Types #
The FileSink supports both row-wise and bulk encoding formats, such as Apache Parquet.
These two variants come with their respective builders that can be created with the following static methods:
- Row-encoded sink:
FileSink.forRowFormat(basePath, rowEncoder) - Bulk-encoded sink:
FileSink.forBulkFormat(basePath, bulkWriterFactory)
When creating either a row or a bulk encoded sink we have to specify the base path where the buckets will be stored and the encoding logic for our data.
Please check out the JavaDoc for FileSink for all the configuration options and more documentation about the implementation of the different data formats.
Row-encoded Formats #
Row-encoded formats need to specify an Encoder
that is used for serializing individual rows to the OutputStream of the in-progress part files.
In addition to the bucket assigner, the RowFormatBuilder allows the user to specify:
- Custom RollingPolicy : Rolling policy to override the DefaultRollingPolicy
- bucketCheckInterval (default = 1 min) : Millisecond interval for checking time based rolling policies
Basic usage for writing String elements thus looks like this:
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
DataStream<String> input = ...;
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build();
input.sinkTo(sink);
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.connector.file.sink.FileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
val input: DataStream[String] = ...
val sink: FileSink[String] = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15))
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5))
.withMaxPartSize(1024 * 1024 * 1024)
.build())
.build()
input.sinkTo(sink)
This example creates a simple sink that assigns records to the default one hour time buckets. It also specifies a rolling policy that rolls the in-progress part file on any of the following 3 conditions:
- It contains at least 15 minutes worth of data
- It hasn’t received new records for the last 5 minutes
- The file size has reached 1 GB (after writing the last record)
Bulk-encoded Formats #
Bulk-encoded sinks are created similarly to the row-encoded ones, but instead of
specifying an Encoder, we have to specify a
BulkWriter.Factory
.
The BulkWriter logic defines how new elements are added and flushed, and how a batch of records
is finalized for further encoding purposes.
Flink comes with four built-in BulkWriter factories:
- ParquetWriterFactory
- AvroWriterFactory
- SequenceFileWriterFactory
- CompressWriterFactory
- OrcBulkWriterFactory
Important Bulk Formats can only have a rolling policy that extends the CheckpointRollingPolicy.
The latter rolls on every checkpoint. A policy can roll additionally based on size or processing time.
Parquet format #
Flink contains built in convenience methods for creating Parquet writer factories for Avro data. These methods and their associated documentation can be found in the ParquetAvroWriters class.
For writing to other Parquet compatible data formats, users need to create the ParquetWriterFactory with a custom implementation of the ParquetBuilder interface.
To use the Parquet bulk encoder in your application you need to add the following dependency:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.11</artifactId>
<version>1.14.4</version>
</dependency>A FileSink that writes Avro data to Parquet format can be created like this:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> input = ...;
final FileSink<GenericRecord> sink = FileSink
.forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: FileSink[GenericRecord] = FileSink
.forBulkFormat(outputBasePath, ParquetAvroWriters.forGenericRecord(schema))
.build()
input.sinkTo(sink)
Similarly, a FileSink that writes Protobuf data to Parquet format can be created like this:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.protobuf.ParquetProtoWriters;
// ProtoRecord is a generated protobuf Message class.
DataStream<ProtoRecord> input = ...;
final FileSink<ProtoRecord> sink = FileSink
.forBulkFormat(outputBasePath, ParquetProtoWriters.forType(ProtoRecord.class))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.protobuf.ParquetProtoWriters
// ProtoRecord is a generated protobuf Message class.
val input: DataStream[ProtoRecord] = ...
val sink: FileSink[ProtoRecord] = FileSink
.forBulkFormat(outputBasePath, ParquetProtoWriters.forType(classOf[ProtoRecord]))
.build()
input.sinkTo(sink)
Avro format #
Flink also provides built-in support for writing data into Avro files. A list of convenience methods to create Avro writer factories and their associated documentation can be found in the AvroWriters class.
To use the Avro writers in your application you need to add the following dependency:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.14.4</version>
</dependency>A FileSink that writes data to Avro files can be created like this:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.avro.AvroWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> input = ...;
final FileSink<GenericRecord> sink = FileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.avro.AvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: FileSink[GenericRecord] = FileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build()
input.sinkTo(sink)
For creating customized Avro writers, e.g. enabling compression, users need to create the AvroWriterFactory
with a custom implementation of the AvroBuilder interface:
AvroWriterFactory<?> factory = new AvroWriterFactory<>((AvroBuilder<Address>) out -> {
Schema schema = ReflectData.get().getSchema(Address.class);
DatumWriter<Address> datumWriter = new ReflectDatumWriter<>(schema);
DataFileWriter<Address> dataFileWriter = new DataFileWriter<>(datumWriter);
dataFileWriter.setCodec(CodecFactory.snappyCodec());
dataFileWriter.create(schema, out);
return dataFileWriter;
});
DataStream<Address> stream = ...
stream.sinkTo(FileSink.forBulkFormat(
outputBasePath,
factory).build());
val factory = new AvroWriterFactory[Address](new AvroBuilder[Address]() {
override def createWriter(out: OutputStream): DataFileWriter[Address] = {
val schema = ReflectData.get.getSchema(classOf[Address])
val datumWriter = new ReflectDatumWriter[Address](schema)
val dataFileWriter = new DataFileWriter[Address](datumWriter)
dataFileWriter.setCodec(CodecFactory.snappyCodec)
dataFileWriter.create(schema, out)
dataFileWriter
}
})
val stream: DataStream[Address] = ...
stream.sinkTo(FileSink.forBulkFormat(
outputBasePath,
factory).build());
ORC Format #
To enable the data to be bulk encoded in ORC format, Flink offers OrcBulkWriterFactory
which takes a concrete implementation of Vectorizer.
Like any other columnar format that encodes data in bulk fashion, Flink’s OrcBulkWriter writes the input elements in batches. It uses
ORC’s VectorizedRowBatch to achieve this.
Since the input element has to be transformed to a VectorizedRowBatch, users have to extend the abstract Vectorizer
class and override the vectorize(T element, VectorizedRowBatch batch) method. As you can see, the method provides an
instance of VectorizedRowBatch to be used directly by the users so users just have to write the logic to transform the
input element to ColumnVectors and set them in the provided VectorizedRowBatch instance.
For example, if the input element is of type Person which looks like:
class Person {
private final String name;
private final int age;
...
}
Then a child implementation to convert the element of type Person and set them in the VectorizedRowBatch can be like:
import org.apache.hadoop.hive.ql.exec.vector.BytesColumnVector;
import org.apache.hadoop.hive.ql.exec.vector.LongColumnVector;
import java.io.IOException;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
public PersonVectorizer(String schema) {
super(schema);
}
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
BytesColumnVector nameColVector = (BytesColumnVector) batch.cols[0];
LongColumnVector ageColVector = (LongColumnVector) batch.cols[1];
int row = batch.size++;
nameColVector.setVal(row, element.getName().getBytes(StandardCharsets.UTF_8));
ageColVector.vector[row] = element.getAge();
}
}
import java.nio.charset.StandardCharsets
import org.apache.hadoop.hive.ql.exec.vector.{BytesColumnVector, LongColumnVector}
class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
val nameColVector = batch.cols(0).asInstanceOf[BytesColumnVector]
val ageColVector = batch.cols(1).asInstanceOf[LongColumnVector]
nameColVector.setVal(batch.size + 1, element.getName.getBytes(StandardCharsets.UTF_8))
ageColVector.vector(batch.size + 1) = element.getAge
}
}
To use the ORC bulk encoder in an application, users need to add the following dependency:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc_2.11</artifactId>
<version>1.14.4</version>
</dependency>And then a FileSink that writes data in ORC format can be created like this:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.orc.writer.OrcBulkWriterFactory;
String schema = "struct<_col0:string,_col1:int>";
DataStream<Person> input = ...;
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(new PersonVectorizer(schema));
final FileSink<Person> sink = FileSink
.forBulkFormat(outputBasePath, writerFactory)
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.orc.writer.OrcBulkWriterFactory
val schema: String = "struct<_col0:string,_col1:int>"
val input: DataStream[Person] = ...
val writerFactory = new OrcBulkWriterFactory(new PersonVectorizer(schema));
val sink: FileSink[Person] = FileSink
.forBulkFormat(outputBasePath, writerFactory)
.build()
input.sinkTo(sink)
OrcBulkWriterFactory can also take Hadoop Configuration and Properties so that a custom Hadoop configuration and ORC
writer properties can be provided.
String schema = ...;
Configuration conf = ...;
Properties writerProperties = new Properties();
writerProperties.setProperty("orc.compress", "LZ4");
// Other ORC supported properties can also be set similarly.
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(
new PersonVectorizer(schema), writerProperties, conf);
val schema: String = ...
val conf: Configuration = ...
val writerProperties: Properties = new Properties()
writerProperties.setProperty("orc.compress", "LZ4")
// Other ORC supported properties can also be set similarly.
val writerFactory = new OrcBulkWriterFactory(
new PersonVectorizer(schema), writerProperties, conf)
The complete list of ORC writer properties can be found here.
Users who want to add user metadata to the ORC files can do so by calling addUserMetadata(...) inside the overriding
vectorize(...) method.
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
...
String metadataKey = ...;
ByteBuffer metadataValue = ...;
this.addUserMetadata(metadataKey, metadataValue);
}
}
class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
...
val metadataKey: String = ...
val metadataValue: ByteBuffer = ...
addUserMetadata(metadataKey, metadataValue)
}
}
Hadoop SequenceFile format #
To use the SequenceFile bulk encoder in your application you need to add the following dependency:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sequence-file</artifactId>
<version>1.14.4</version>
</dependency>A simple SequenceFile writer can be created like this:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.configuration.GlobalConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
DataStream<Tuple2<LongWritable, Text>> input = ...;
Configuration hadoopConf = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration());
final FileSink<Tuple2<LongWritable, Text>> sink = FileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory<>(hadoopConf, LongWritable.class, Text.class))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.configuration.GlobalConfiguration
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.SequenceFile
import org.apache.hadoop.io.Text;
val input: DataStream[(LongWritable, Text)] = ...
val hadoopConf: Configuration = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration())
val sink: FileSink[(LongWritable, Text)] = FileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory(hadoopConf, LongWritable.class, Text.class))
.build()
input.sinkTo(sink)
The SequenceFileWriterFactory supports additional constructor parameters to specify compression settings.
Bucket Assignment #
The bucketing logic defines how the data will be structured into subdirectories inside the base output directory.
Both row and bulk formats (see File Formats) use the DateTimeBucketAssigner as the default assigner.
By default the DateTimeBucketAssigner creates hourly buckets based on the system default timezone
with the following format: yyyy-MM-dd--HH. Both the date format (i.e. bucket size) and timezone can be
configured manually.
We can specify a custom BucketAssigner by calling .withBucketAssigner(assigner) on the format builders.
Flink comes with two built-in BucketAssigners:
DateTimeBucketAssigner: Default time based assignerBasePathBucketAssigner: Assigner that stores all part files in the base path (single global bucket)
Rolling Policy #
The RollingPolicy defines when a given in-progress part file will be closed and moved to the pending and later to finished state.
Part files in the “finished” state are the ones that are ready for viewing and are guaranteed to contain valid data that will not be reverted in case of failure.
In STREAMING mode, the Rolling Policy in combination with the checkpointing interval (pending files become finished on the next checkpoint) control how quickly
part files become available for downstream readers and also the size and number of these parts. In BATCH mode, part-files become visible at the end of the job but
the rolling policy can control their maximum size.
Flink comes with two built-in RollingPolicies:
DefaultRollingPolicyOnCheckpointRollingPolicy
Part file lifecycle #
In order to use the output of the FileSink in downstream systems, we need to understand the naming and lifecycle of the output files produced.
Part files can be in one of three states:
- In-progress : The part file that is currently being written to is in-progress
- Pending : Closed (due to the specified rolling policy) in-progress files that are waiting to be committed
- Finished : On successful checkpoints (
STREAMING) or at the end of input (BATCH) pending files transition to “Finished”
Only finished files are safe to read by downstream systems as those are guaranteed to not be modified later.
Each writer subtask will have a single in-progress part file at any given time for every active bucket, but there can be several pending and finished files.
Part file example
To better understand the lifecycle of these files let’s look at a simple example with 2 sink subtasks:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
└── part-81fc4980-a6af-41c8-9937-9939408a734b-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
When the part file part-81fc4980-a6af-41c8-9937-9939408a734b-0 is rolled (let’s say it becomes too large), it becomes pending but it is not renamed. The sink then opens a new part file: part-81fc4980-a6af-41c8-9937-9939408a734b-1:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
As part-81fc4980-a6af-41c8-9937-9939408a734b-0 is now pending completion, after the next successful checkpoint, it is finalized:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
New buckets are created as dictated by the bucketing policy, and this doesn’t affect currently in-progress files:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
└── 2019-08-25--13
└── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.2b475fec-1482-4dea-9946-eb4353b475f1
Old buckets can still receive new records as the bucketing policy is evaluated on a per-record basis.
Part file configuration #
Finished files can be distinguished from the in-progress ones by their naming scheme only.
By default, the file naming strategy is as follows:
- In-progress / Pending:
part-<uid>-<partFileIndex>.inprogress.uid - Finished:
part-<uid>-<partFileIndex>whereuidis a random id assigned to a subtask of the sink when the subtask is instantiated. Thisuidis not fault-tolerant so it is regenerated when the subtask recovers from a failure.
Flink allows the user to specify a prefix and/or a suffix for his/her part files.
This can be done using an OutputFileConfig.
For example for a prefix “prefix” and a suffix “.ext” the sink will create the following files:
└── 2019-08-25--12
├── prefix-4005733d-a830-4323-8291-8866de98b582-0.ext
├── prefix-4005733d-a830-4323-8291-8866de98b582-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-81fc4980-a6af-41c8-9937-9939408a734b-0.ext
└── prefix-81fc4980-a6af-41c8-9937-9939408a734b-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
The user can specify an OutputFileConfig in the following way:
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build();
FileSink<Tuple2<Integer, Integer>> sink = FileSink
.forRowFormat((new Path(outputPath), new SimpleStringEncoder<>("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build();
val config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
val sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()
Important Considerations #
General #
Important Note 1: When using Hadoop < 2.7, please use
the OnCheckpointRollingPolicy which rolls part files on every checkpoint. The reason is that if part files “traverse”
the checkpoint interval, then, upon recovery from a failure the FileSink may use the truncate() method of the
filesystem to discard uncommitted data from the in-progress file. This method is not supported by pre-2.7 Hadoop versions
and Flink will throw an exception.
Important Note 2: Given that Flink sinks and UDFs in general do not differentiate between normal job termination (e.g. finite input stream) and termination due to failure, upon normal termination of a job, the last in-progress files will not be transitioned to the “finished” state.
Important Note 3: Flink and the FileSink never overwrites committed data.
Given this, when trying to restore from an old checkpoint/savepoint which assumes an in-progress file which was committed
by subsequent successful checkpoints, the FileSink will refuse to resume and will throw an exception as it cannot locate the
in-progress file.
Important Note 4: Currently, the FileSink only supports three filesystems:
HDFS, S3, and Local. Flink will throw an exception when using an unsupported filesystem at runtime.
BATCH-specific #
Important Note 1: Although the Writer is executed with the user-specified
parallelism, the Committer is executed with parallelism equal to 1.
Important Note 2: Pending files are committed, i.e. transition to Finished
state, after the whole input has been processed.
Important Note 3: When High-Availability is activated, if a JobManager
failure happens while the Committers are committing, then we may have duplicates. This is going to be fixed in
future Flink versions
(see progress in FLIP-147).
S3-specific #
Important Note 1: For S3, the FileSink
supports only the Hadoop-based FileSystem implementation, not
the implementation based on Presto. In case your job uses the
FileSink to write to S3 but you want to use the Presto-based one for checkpointing,
it is advised to use explicitly “s3a://" (for Hadoop) as the scheme for the target path of
the sink and “s3p://" for checkpointing (for Presto). Using “s3://" for both the sink
and checkpointing may lead to unpredictable behavior, as both implementations “listen” to that scheme.
Important Note 2: To guarantee exactly-once semantics while
being efficient, the FileSink uses the Multi-part Upload
feature of S3 (MPU from now on). This feature allows to upload files in independent chunks (thus the “multi-part”)
which can be combined into the original file when all the parts of the MPU are successfully uploaded.
For inactive MPUs, S3 supports a bucket lifecycle rule that the user can use to abort multipart uploads
that don’t complete within a specified number of days after being initiated. This implies that if you set this rule
aggressively and take a savepoint with some part-files being not fully uploaded, their associated MPUs may time-out
before the job is restarted. This will result in your job not being able to restore from that savepoint as the
pending part-files are no longer there and Flink will fail with an exception as it tries to fetch them and fails.