This documentation is for an out-of-date version of Apache Flink. We recommend you use the latest stable version.
自定义函数
自定义函数 #
自定义函数(UDF)是一种扩展开发机制,可以用来在查询语句里调用难以用其他方式表达的频繁使用或自定义的逻辑。
自定义函数可以用 JVM 语言(例如 Java 或 Scala)或 Python 实现,实现者可以在 UDF 中使用任意第三方库,本文聚焦于使用 JVM 语言开发自定义函数。
概述 #
当前 Flink 有如下几种函数:
- 标量函数 将标量值转换成一个新标量值;
- 表值函数 将标量值转换成新的行数据;
- 聚合函数 将多行数据里的标量值转换成一个新标量值;
- 表值聚合函数 将多行数据里的标量值转换成新的行数据;
- 异步表值函数 是异步查询外部数据系统的特殊函数。
注意 标量和表值函数已经使用了新的基于数据类型的类型系统,聚合函数仍然使用基于 TypeInformation 的旧类型系统。
以下示例展示了如何创建一个基本的标量函数,以及如何在 Table API 和 SQL 里调用这个函数。
函数用于 SQL 查询前要先经过注册;而在用于 Table API 时,函数可以先注册后调用,也可以 内联 后直接使用。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// 定义函数逻辑
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
// define function logic
class SubstringFunction extends ScalarFunction {
def eval(s: String, begin: Integer, end: Integer): String = {
s.substring(begin, end)
}
}
val env = TableEnvironment.create(...)
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(classOf[SubstringFunction], $"myField", 5, 12))
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", classOf[SubstringFunction])
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("SubstringFunction", $"myField", 5, 12))
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable")
对于交互式会话,还可以在使用或注册函数之前对其进行参数化,这样可以把函数 实例 而不是函数 类 用作临时函数。
为确保函数实例可应用于集群环境,参数必须是可序列化的。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// 定义可参数化的函数逻辑
public static class SubstringFunction extends ScalarFunction {
private boolean endInclusive;
public SubstringFunction(boolean endInclusive) {
this.endInclusive = endInclusive;
}
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, endInclusive ? end + 1 : end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(new SubstringFunction(true), $("myField"), 5, 12));
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", new SubstringFunction(true));
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
// 定义可参数化的函数逻辑
class SubstringFunction(val endInclusive) extends ScalarFunction {
def eval(s: String, begin: Integer, end: Integer): String = {
s.substring(endInclusive ? end + 1 : end)
}
}
val env = TableEnvironment.create(...)
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(new SubstringFunction(true), $"myField", 5, 12))
// 注册函数
env.createTemporarySystemFunction("SubstringFunction", new SubstringFunction(true))
你可以在 Table API 中使用 * 表达式作为函数的一个参数,它将被扩展为该表所有的列作为函数对应位置的参数。
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class MyConcatFunction extends ScalarFunction {
public String eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object... fields) {
return Arrays.stream(fields)
.map(Object::toString)
.collect(Collectors.joining(","));
}
}
TableEnvironment env = TableEnvironment.create(...);
// 使用 $("*") 作为函数的参数,如果 MyTable 有 3 列 (a, b, c),
// 它们都将会被传给 MyConcatFunction。
env.from("MyTable").select(call(MyConcatFunction.class, $("*")));
// 它等价于显式地将所有列传给 MyConcatFunction。
env.from("MyTable").select(call(MyConcatFunction.class, $("a"), $("b"), $("c")));
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
import scala.annotation.varargs
class MyConcatFunction extends ScalarFunction {
@varargs
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) row: AnyRef*): String = {
row.map(f => f.toString).mkString(",")
}
}
val env = TableEnvironment.create(...)
// 使用 $"*" 作为函数的参数,如果 MyTable 有 3 个列 (a, b, c),
// 它们都将会被传给 MyConcatFunction。
env.from("MyTable").select(call(classOf[MyConcatFunction], $"*"));
// 它等价于显式地将所有列传给 MyConcatFunction。
env.from("MyTable").select(call(classOf[MyConcatFunction], $"a", $"b", $"c"));
开发指南 #
注意在聚合函数使用新的类型系统前,本节仅适用于标量和表值函数。
所有的自定义函数都遵循一些基本的实现原则。
函数类 #
实现类必须继承自合适的基类之一(例如 org.apache.flink.table.functions.ScalarFunction )。
该类必须声明为 public ,而不是 abstract ,并且可以被全局访问。不允许使用非静态内部类或匿名类。
为了将自定义函数存储在持久化的 catalog 中,该类必须具有默认构造器,且在运行时可实例化。
求值方法 #
基类提供了一组可以被重写的方法,例如 open()、 close() 或 isDeterministic() 。
但是,除了上述方法之外,作用于每条传入记录的主要逻辑还必须通过专门的 求值方法 来实现。
根据函数的种类,后台生成的运算符会在运行时调用诸如 eval()、accumulate() 或 retract() 之类的求值方法。
这些方法必须声明为 public ,并带有一组定义明确的参数。
常规的 JVM 方法调用语义是适用的。因此可以:
- 实现重载的方法,例如
eval(Integer)和eval(LocalDateTime); - 使用变长参数,例如
eval(Integer...); - 使用对象继承,例如
eval(Object)可接受LocalDateTime和Integer作为参数; - 也可组合使用,例如
eval(Object...)可接受所有类型的参数。
以下代码片段展示了一个重载函数的示例:
import org.apache.flink.table.functions.ScalarFunction;
// 有多个重载求值方法的函数
public static class SumFunction extends ScalarFunction {
public Integer eval(Integer a, Integer b) {
return a + b;
}
public Integer eval(String a, String b) {
return Integer.valueOf(a) + Integer.valueOf(b);
}
public Integer eval(Double... d) {
double result = 0;
for (double value : d)
result += value;
return (int) result;
}
}
import org.apache.flink.table.functions.ScalarFunction
import scala.annotation.varargs
// 有多个重载求值方法的函数
class SumFunction extends ScalarFunction {
def eval(a: Integer, b: Integer): Integer = {
a + b
}
def eval(a: String, b: String): Integer = {
Integer.valueOf(a) + Integer.valueOf(b)
}
@varargs // generate var-args like Java
def eval(d: Double*): Integer = {
d.sum.toInt
}
}
类型推导 #
Table(类似于 SQL 标准)是一种强类型的 API。因此,函数的参数和返回类型都必须映射到数据类型。
从逻辑角度看,Planner 需要知道数据类型、精度和小数位数;从 JVM 角度来看,Planner 在调用自定义函数时需要知道如何将内部数据结构表示为 JVM 对象。
术语 类型推导 概括了意在验证输入值、派生出参数/返回值数据类型的逻辑。
Flink 自定义函数实现了自动的类型推导提取,通过反射从函数的类及其求值方法中派生数据类型。如果这种隐式的反射提取方法不成功,则可以通过使用 @DataTypeHint 和 @FunctionHint 注解相关参数、类或方法来支持提取过程,下面展示了有关如何注解函数的例子。
如果需要更高级的类型推导逻辑,实现者可以在每个自定义函数中显式重写 getTypeInference() 方法。但是,建议使用注解方式,因为它可使自定义类型推导逻辑保持在受影响位置附近,而在其他位置则保持默认状态。
自动类型推导 #
自动类型推导会检查函数的类和求值方法,派生出函数参数和结果的数据类型, @DataTypeHint 和 @FunctionHint 注解支持自动类型推导。
有关可以隐式映射到数据类型的类的完整列表,请参阅数据类型。
@DataTypeHint
在许多情况下,需要支持以 内联 方式自动提取出函数参数、返回值的类型。
以下例子展示了如何使用 @DataTypeHint,详情可参考该注解类的文档。
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;
// 有多个重载求值方法的函数
public static class OverloadedFunction extends ScalarFunction {
// no hint required
public Long eval(long a, long b) {
return a + b;
}
// 定义 decimal 的精度和小数位
public @DataTypeHint("DECIMAL(12, 3)") BigDecimal eval(double a, double b) {
return BigDecimal.valueOf(a + b);
}
// 定义嵌套数据类型
@DataTypeHint("ROW<s STRING, t TIMESTAMP_LTZ(3)>")
public Row eval(int i) {
return Row.of(String.valueOf(i), Instant.ofEpochSecond(i));
}
// 允许任意类型的符入,并输出序列化定制后的值
@DataTypeHint(value = "RAW", bridgedTo = ByteBuffer.class)
public ByteBuffer eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return MyUtils.serializeToByteBuffer(o);
}
}
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.InputGroup
import org.apache.flink.table.functions.ScalarFunction
import org.apache.flink.types.Row
import scala.annotation.varargs
// function with overloaded evaluation methods
class OverloadedFunction extends ScalarFunction {
// no hint required
def eval(a: Long, b: Long): Long = {
a + b
}
// 定义 decimal 的精度和小数位
@DataTypeHint("DECIMAL(12, 3)")
def eval(double a, double b): BigDecimal = {
java.lang.BigDecimal.valueOf(a + b)
}
// 定义嵌套数据类型
@DataTypeHint("ROW<s STRING, t TIMESTAMP_LTZ(3)>")
def eval(Int i): Row = {
Row.of(java.lang.String.valueOf(i), java.time.Instant.ofEpochSecond(i))
}
// 允许任意类型的符入,并输出定制序列化后的值
@DataTypeHint(value = "RAW", bridgedTo = classOf[java.nio.ByteBuffer])
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o): java.nio.ByteBuffer = {
MyUtils.serializeToByteBuffer(o)
}
}
@FunctionHint
有时我们希望一种求值方法可以同时处理多种数据类型,有时又要求对重载的多个求值方法仅声明一次通用的结果类型。
@FunctionHint 注解可以提供从入参数据类型到结果数据类型的映射,它可以在整个函数类或求值方法上注解输入、累加器和结果的数据类型。可以在类顶部声明一个或多个注解,也可以为类的所有求值方法分别声明一个或多个注解。所有的 hint 参数都是可选的,如果未定义参数,则使用默认的基于反射的类型提取。在函数类顶部定义的 hint 参数被所有求值方法继承。
以下例子展示了如何使用 @FunctionHint,详情可参考该注解类的文档。
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
// 为函数类的所有求值方法指定同一个输出类型
@FunctionHint(output = @DataTypeHint("ROW<s STRING, i INT>"))
public static class OverloadedFunction extends TableFunction<Row> {
public void eval(int a, int b) {
collect(Row.of("Sum", a + b));
}
// overloading of arguments is still possible
public void eval() {
collect(Row.of("Empty args", -1));
}
}
// 解耦类型推导与求值方法,类型推导完全取决于 FunctionHint
@FunctionHint(
input = {@DataTypeHint("INT"), @DataTypeHint("INT")},
output = @DataTypeHint("INT")
)
@FunctionHint(
input = {@DataTypeHint("BIGINT"), @DataTypeHint("BIGINT")},
output = @DataTypeHint("BIGINT")
)
@FunctionHint(
input = {},
output = @DataTypeHint("BOOLEAN")
)
public static class OverloadedFunction extends TableFunction<Object> {
// an implementer just needs to make sure that a method exists
// that can be called by the JVM
public void eval(Object... o) {
if (o.length == 0) {
collect(false);
}
collect(o[0]);
}
}
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.FunctionHint
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
// 为函数类的所有求值方法指定同一个输出类型
@FunctionHint(output = new DataTypeHint("ROW<s STRING, i INT>"))
class OverloadedFunction extends TableFunction[Row] {
def eval(a: Int, b: Int): Unit = {
collect(Row.of("Sum", Int.box(a + b)))
}
// overloading of arguments is still possible
def eval(): Unit = {
collect(Row.of("Empty args", Int.box(-1)))
}
}
// 解耦类型推导与求值方法,类型推导完全取决于 @FunctionHint
@FunctionHint(
input = Array(new DataTypeHint("INT"), new DataTypeHint("INT")),
output = new DataTypeHint("INT")
)
@FunctionHint(
input = Array(new DataTypeHint("BIGINT"), new DataTypeHint("BIGINT")),
output = new DataTypeHint("BIGINT")
)
@FunctionHint(
input = Array(),
output = new DataTypeHint("BOOLEAN")
)
class OverloadedFunction extends TableFunction[AnyRef] {
// an implementer just needs to make sure that a method exists
// that can be called by the JVM
@varargs
def eval(o: AnyRef*) = {
if (o.length == 0) {
collect(Boolean.box(false))
}
collect(o(0))
}
}
定制类型推导 #
在大多数情况下,@DataTypeHint 和 @FunctionHint 足以构建自定义函数,然而通过重写 getTypeInference() 定制自动类型推导逻辑,实现者可以创建任意像系统内置函数那样有用的函数。
以下用 Java 实现的例子展示了定制类型推导的潜力,它根据字符串参数来确定函数的结果类型。该函数带有两个字符串参数:第一个参数表示要分析的字符串,第二个参数表示目标类型。
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.catalog.DataTypeFactory;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.types.inference.TypeInference;
import org.apache.flink.types.Row;
public static class LiteralFunction extends ScalarFunction {
public Object eval(String s, String type) {
switch (type) {
case "INT":
return Integer.valueOf(s);
case "DOUBLE":
return Double.valueOf(s);
case "STRING":
default:
return s;
}
}
// 禁用自动的反射式类型推导,使用如下逻辑进行类型推导
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
return TypeInference.newBuilder()
// 指定输入参数的类型,必要时参数会被隐式转换
.typedArguments(DataTypes.STRING(), DataTypes.STRING())
// specify a strategy for the result data type of the function
.outputTypeStrategy(callContext -> {
if (!callContext.isArgumentLiteral(1) || callContext.isArgumentNull(1)) {
throw callContext.newValidationError("Literal expected for second argument.");
}
// 基于字符串值返回数据类型
final String literal = callContext.getArgumentValue(1, String.class).orElse("STRING");
switch (literal) {
case "INT":
return Optional.of(DataTypes.INT().notNull());
case "DOUBLE":
return Optional.of(DataTypes.DOUBLE().notNull());
case "STRING":
default:
return Optional.of(DataTypes.STRING());
}
})
.build();
}
}
For more examples of custom type inference, see also the flink-examples-table module with
advanced function implementation
.
运行时集成 #
有时候自定义函数需要获取一些全局信息,或者在真正被调用之前做一些配置(setup)/清理(clean-up)的工作。自定义函数也提供了 open() 和 close() 方法,你可以重写这两个方法做到类似于 DataStream API 中 RichFunction 的功能。
open() 方法在求值方法被调用之前先调用。close() 方法在求值方法调用完之后被调用。
open() 方法提供了一个 FunctionContext,它包含了一些自定义函数被执行时的上下文信息,比如 metric group、分布式文件缓存,或者是全局的作业参数等。
下面的信息可以通过调用 FunctionContext 的对应的方法来获得:
| 方法 | 描述 |
|---|---|
getMetricGroup() |
执行该函数的 subtask 的 Metric Group。 |
getCachedFile(name) |
分布式文件缓存的本地临时文件副本。 |
getJobParameter(name, defaultValue) |
跟对应的 key 关联的全局参数值。 |
下面的例子展示了如何在一个标量函数中通过 FunctionContext 来获取一个全局的任务参数:
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public static class HashCodeFunction extends ScalarFunction {
private int factor = 0;
@Override
public void open(FunctionContext context) throws Exception {
// 获取参数 "hashcode_factor"
// 如果不存在,则使用默认值 "12"
factor = Integer.parseInt(context.getJobParameter("hashcode_factor", "12"));
}
public int eval(String s) {
return s.hashCode() * factor;
}
}
TableEnvironment env = TableEnvironment.create(...);
// 设置任务参数
env.getConfig().addJobParameter("hashcode_factor", "31");
// 注册函数
env.createTemporarySystemFunction("hashCode", HashCodeFunction.class);
// 调用函数
env.sqlQuery("SELECT myField, hashCode(myField) FROM MyTable");
import org.apache.flink.table.api._
import org.apache.flink.table.functions.FunctionContext
import org.apache.flink.table.functions.ScalarFunction
class HashCodeFunction extends ScalarFunction {
private var factor: Int = 0
override def open(context: FunctionContext): Unit = {
// 获取参数 "hashcode_factor"
// 如果不存在,则使用默认值 "12"
factor = context.getJobParameter("hashcode_factor", "12").toInt
}
def eval(s: String): Int = {
s.hashCode * factor
}
}
val env = TableEnvironment.create(...)
// 设置任务参数
env.getConfig.addJobParameter("hashcode_factor", "31")
// 注册函数
env.createTemporarySystemFunction("hashCode", classOf[HashCodeFunction])
// 调用函数
env.sqlQuery("SELECT myField, hashCode(myField) FROM MyTable")
标量函数 #
自定义标量函数可以把 0 到多个标量值映射成 1 个标量值,数据类型里列出的任何数据类型都可作为求值方法的参数和返回值类型。
想要实现自定义标量函数,你需要扩展 org.apache.flink.table.functions 里面的 ScalarFunction 并且实现一个或者多个求值方法。标量函数的行为取决于你写的求值方法。求值方法必须是 public 的,而且名字必须是 eval。
下面的例子展示了如何实现一个求哈希值的函数并在查询里调用它,详情可参考开发指南:
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class HashFunction extends ScalarFunction {
// 接受任意类型输入,返回 INT 型输出
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(HashFunction.class, $("myField")));
// 注册函数
env.createTemporarySystemFunction("HashFunction", HashFunction.class);
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("HashFunction", $("myField")));
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
import org.apache.flink.table.annotation.InputGroup
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
class HashFunction extends ScalarFunction {
// 接受任意类型输入,返回 INT 型输出
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) o: AnyRef): Int {
return o.hashCode();
}
}
val env = TableEnvironment.create(...)
// 在 Table API 里不经注册直接“内联”调用函数
env.from("MyTable").select(call(classOf[HashFunction], $"myField"))
// 注册函数
env.createTemporarySystemFunction("HashFunction", classOf[HashFunction])
// 在 Table API 里调用注册好的函数
env.from("MyTable").select(call("HashFunction", $"myField"))
// 在 SQL 里调用注册好的函数
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable")
如果你打算使用 Python 实现或调用标量函数,详情可参考 Python 标量函数。
表值函数 #
跟自定义标量函数一样,自定义表值函数的输入参数也可以是 0 到多个标量。但是跟标量函数只能返回一个值不同的是,它可以返回任意多行。返回的每一行可以包含 1 到多列,如果输出行只包含 1 列,会省略结构化信息并生成标量值,这个标量值在运行阶段会隐式地包装进行里。
要定义一个表值函数,你需要扩展 org.apache.flink.table.functions 下的 TableFunction,可以通过实现多个名为 eval 的方法对求值方法进行重载。像其他函数一样,输入和输出类型也可以通过反射自动提取出来。表值函数返回的表的类型取决于 TableFunction 类的泛型参数 T,不同于标量函数,表值函数的求值方法本身不包含返回类型,而是通过 collect(T) 方法来发送要输出的行。
在 Table API 中,表值函数是通过 .joinLateral(...) 或者 .leftOuterJoinLateral(...) 来使用的。joinLateral 算子会把外表(算子左侧的表)的每一行跟跟表值函数返回的所有行(位于算子右侧)进行 (cross)join。leftOuterJoinLateral 算子也是把外表(算子左侧的表)的每一行跟表值函数返回的所有行(位于算子右侧)进行(cross)join,并且如果表值函数返回 0 行也会保留外表的这一行。
在 SQL 里面用 JOIN 或者 以 ON TRUE 为条件的 LEFT JOIN 来配合 LATERAL TABLE(<TableFunction>) 的使用。
下面的例子展示了如何实现一个分隔函数并在查询里调用它,详情可参考开发指南:
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.*;
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public static class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// use collect(...) to emit a row
collect(Row.of(s, s.length()));
}
}
}
TableEnvironment env = TableEnvironment.create(...);
// 在 Table API 里不经注册直接“内联”调用函数
env
.from("MyTable")
.joinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
// 在 Table API 里重命名函数字段
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")).as("newWord", "newLength"))
.select($("myField"), $("newWord"), $("newLength"));
// 注册函数
env.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
// 在 Table API 里调用注册好的函数
env
.from("MyTable")
.joinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
// 在 SQL 里调用注册好的函数
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// 在 SQL 里重命名函数字段
env.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE");
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.FunctionHint
import org.apache.flink.table.api._
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
@FunctionHint(output = new DataTypeHint("ROW<word STRING, length INT>"))
class SplitFunction extends TableFunction[Row] {
def eval(str: String): Unit = {
// use collect(...) to emit a row
str.split(" ").foreach(s => collect(Row.of(s, Int.box(s.length))))
}
}
val env = TableEnvironment.create(...)
// 在 Table API 里不经注册直接“内联”调用函数
env
.from("MyTable")
.joinLateral(call(classOf[SplitFunction], $"myField")
.select($"myField", $"word", $"length")
env
.from("MyTable")
.leftOuterJoinLateral(call(classOf[SplitFunction], $"myField"))
.select($"myField", $"word", $"length")
// 在 Table API 里重命名函数字段
env
.from("MyTable")
.leftOuterJoinLateral(call(classOf[SplitFunction], $"myField").as("newWord", "newLength"))
.select($"myField", $"newWord", $"newLength")
// 注册函数
env.createTemporarySystemFunction("SplitFunction", classOf[SplitFunction])
// 在 Table API 里调用注册好的函数
env
.from("MyTable")
.joinLateral(call("SplitFunction", $"myField"))
.select($"myField", $"word", $"length")
env
.from("MyTable")
.leftOuterJoinLateral(call("SplitFunction", $"myField"))
.select($"myField", $"word", $"length")
// 在 SQL 里调用注册好的函数
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE")
// 在 SQL 里重命名函数字段
env.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE")
如果你打算使用 Scala,不要把表值函数声明为 Scala object,Scala object 是单例对象,将导致并发问题。
如果你打算使用 Python 实现或调用表值函数,详情可参考 Python 表值函数。
聚合函数 #
自定义聚合函数(UDAGG)是把一个表(一行或者多行,每行可以有一列或者多列)聚合成一个标量值。
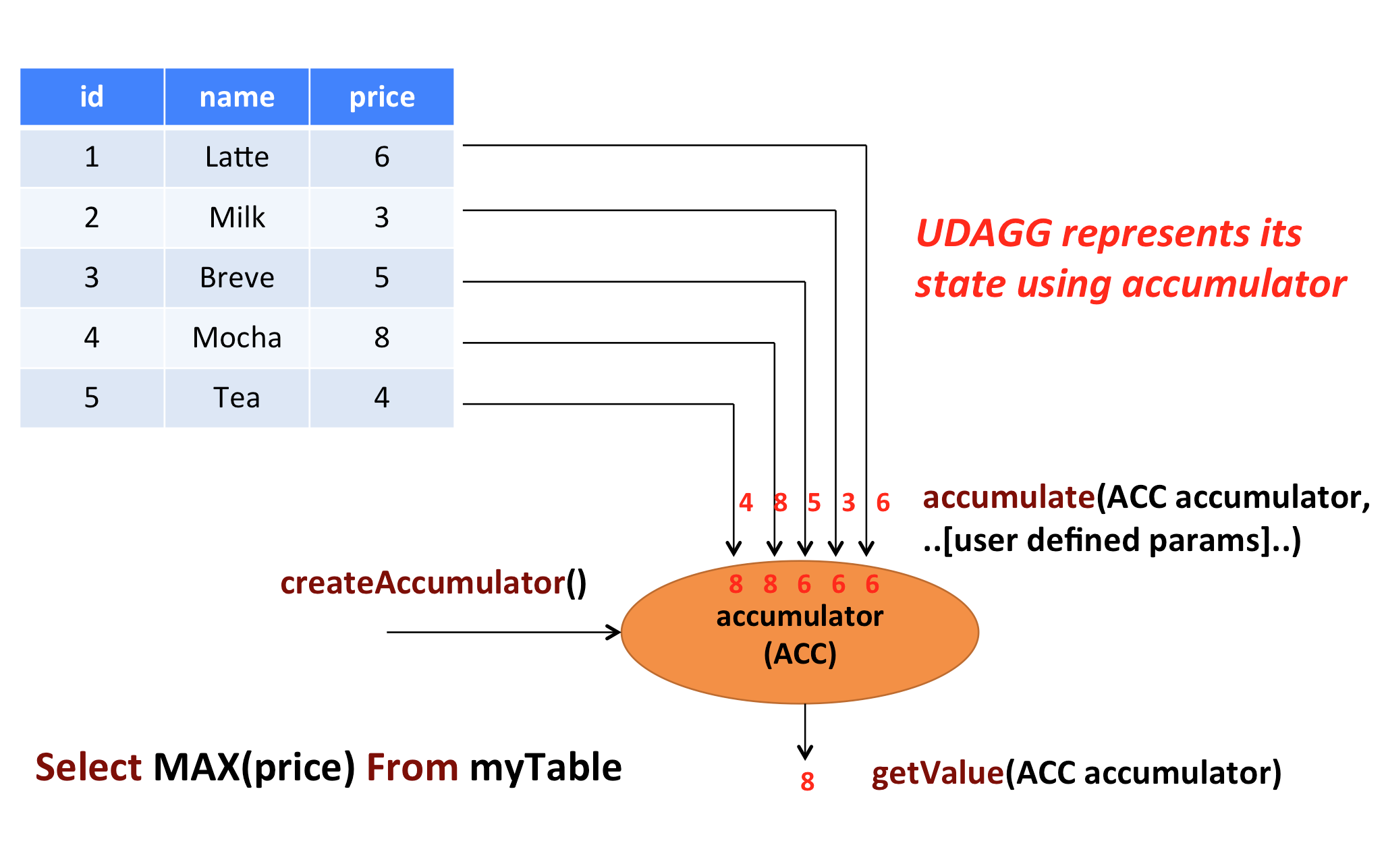
上面的图片展示了一个聚合的例子。假设你有一个关于饮料的表。表里面有三个字段,分别是 id、name、price,表里有 5 行数据。假设你需要找到所有饮料里最贵的饮料的价格,即执行一个 max() 聚合。你需要遍历所有 5 行数据,而结果就只有一个数值。
自定义聚合函数是通过扩展 AggregateFunction 来实现的。AggregateFunction 的工作过程如下。首先,它需要一个 accumulator,它是一个数据结构,存储了聚合的中间结果。通过调用 AggregateFunction 的 createAccumulator() 方法创建一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate() 方法来更新 accumulator。当所有的数据都处理完了之后,通过调用 getValue 方法来计算和返回最终的结果。
下面几个方法是每个 AggregateFunction 必须要实现的:
createAccumulator()accumulate()getValue()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复杂类型。所以跟 ScalarFunction 和 TableFunction 一样,AggregateFunction 也提供了 AggregateFunction#getResultType() 和 AggregateFunction#getAccumulatorType() 来分别指定返回值类型和 accumulator 的类型,两个函数的返回值类型也都是 TypeInformation。
除了上面的方法,还有几个方法可以选择实现。这些方法有些可以让查询更加高效,而有些是在某些特定场景下必须要实现的。例如,如果聚合函数用在会话窗口(当两个会话窗口合并的时候需要 merge 他们的 accumulator)的话,merge() 方法就是必须要实现的。
AggregateFunction 的以下方法在某些场景下是必须实现的:
retract()在 boundedOVER窗口中是必须实现的。merge()在许多批式聚合和会话以及滚动窗口聚合中是必须实现的。除此之外,这个方法对于优化也很多帮助。例如,两阶段聚合优化就需要所有的AggregateFunction都实现merge方法。resetAccumulator()在许多批式聚合中是必须实现的。
AggregateFunction 的所有方法都必须是 public 的,不能是 static 的,而且名字必须跟上面写的一样。createAccumulator、getValue、getResultType 以及 getAccumulatorType 这几个函数是在抽象类 AggregateFunction 中定义的,而其他函数都是约定的方法。如果要定义一个聚合函数,你需要扩展 org.apache.flink.table.functions.AggregateFunction,并且实现一个(或者多个)accumulate 方法。accumulate 方法可以重载,每个方法的参数类型不同,并且支持变长参数。
AggregateFunction 的所有方法的详细文档如下。
/**
* Base class for user-defined aggregates and table aggregates.
*
* @param <T> the type of the aggregation result.
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
public abstract class UserDefinedAggregateFunction<T, ACC> extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
public ACC createAccumulator(); // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
public TypeInformation<T> getResultType = null; // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
public TypeInformation<ACC> getAccumulatorType = null; // PRE-DEFINED
}
/**
* Base class for aggregation functions.
*
* @param <T> the type of the aggregation result
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* AggregateFunction represents its state using accumulator, thereby the state of the
* AggregateFunction must be put into the accumulator.
*/
public abstract class AggregateFunction<T, ACC> extends UserDefinedAggregateFunction<T, ACC> {
/** Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An AggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs]); // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs]); // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and bounded grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an {@link java.lang.Iterable} pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> its); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized.
* The returned value could be either an early and incomplete result
* (periodically emitted as data arrive) or the final result of the
* aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @return the aggregation result
*/
public T getValue(ACC accumulator); // MANDATORY
/**
* Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for
* bounded grouping aggregate.
*
* @param accumulator the accumulator which needs to be reset
*/
public void resetAccumulator(ACC accumulator); // OPTIONAL
/**
* Returns true if this AggregateFunction can only be applied in an OVER window.
*
* @return true if the AggregateFunction requires an OVER window, false otherwise.
*/
public Boolean requiresOver = false; // PRE-DEFINED
}
/**
* Base class for user-defined aggregates and table aggregates.
*
* @tparam T the type of the aggregation result.
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
abstract class UserDefinedAggregateFunction[T, ACC] extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
def createAccumulator(): ACC // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
def getResultType: TypeInformation[T] = null // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
def getAccumulatorType: TypeInformation[ACC] = null // PRE-DEFINED
}
/**
* Base class for aggregation functions.
*
* @tparam T the type of the aggregation result
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* AggregateFunction represents its state using accumulator, thereby the state of the
* AggregateFunction must be put into the accumulator.
*/
abstract class AggregateFunction[T, ACC] extends UserDefinedAggregateFunction[T, ACC] {
/**
* Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An AggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and bounded grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, its: java.lang.Iterable[ACC]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized.
* The returned value could be either an early and incomplete result
* (periodically emitted as data arrive) or the final result of the
* aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @return the aggregation result
*/
def getValue(accumulator: ACC): T // MANDATORY
/**
* Resets the accumulator for this [[AggregateFunction]]. This function must be implemented for
* bounded grouping aggregate.
*
* @param accumulator the accumulator which needs to be reset
*/
def resetAccumulator(accumulator: ACC): Unit // OPTIONAL
/**
* Returns true if this AggregateFunction can only be applied in an OVER window.
*
* @return true if the AggregateFunction requires an OVER window, false otherwise.
*/
def requiresOver: Boolean = false // PRE-DEFINED
}
下面的例子展示了如何:
- 定义一个聚合函数来计算某一列的加权平均,
- 在
TableEnvironment中注册函数, - 在查询中使用函数。
为了计算加权平均值,accumulator 需要存储加权总和以及数据的条数。在我们的例子里,我们定义了一个类 WeightedAvgAccum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,在失败时进行恢复,以此来保证精确一次的语义。
我们的 WeightedAvg(聚合函数)的 accumulate 方法有三个输入参数。第一个是 WeightedAvgAccum accumulator,另外两个是用户自定义的输入:输入的值 ivalue 和 输入的权重 iweight。尽管 retract()、merge()、resetAccumulator() 这几个方法在大多数聚合类型中都不是必须实现的,我们也在样例中提供了他们的实现。请注意我们在 Scala 样例中也是用的是 Java 的基础类型,并且定义了 getResultType() 和 getAccumulatorType(),因为 Flink 的类型推导对于 Scala 的类型推导做的不是很好。
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("wAvg", new WeightedAvg());
// 使用函数
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user");
import java.lang.{Long => JLong, Integer => JInteger}
import org.apache.flink.api.java.tuple.{Tuple1 => JTuple1}
import org.apache.flink.api.java.typeutils.TupleTypeInfo
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.AggregateFunction
/**
* Accumulator for WeightedAvg.
*/
class WeightedAvgAccum extends JTuple1[JLong, JInteger] {
sum = 0L
count = 0
}
/**
* Weighted Average user-defined aggregate function.
*/
class WeightedAvg extends AggregateFunction[JLong, CountAccumulator] {
override def createAccumulator(): WeightedAvgAccum = {
new WeightedAvgAccum
}
override def getValue(acc: WeightedAvgAccum): JLong = {
if (acc.count == 0) {
null
} else {
acc.sum / acc.count
}
}
def accumulate(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {
acc.sum += iValue * iWeight
acc.count += iWeight
}
def retract(acc: WeightedAvgAccum, iValue: JLong, iWeight: JInteger): Unit = {
acc.sum -= iValue * iWeight
acc.count -= iWeight
}
def merge(acc: WeightedAvgAccum, it: java.lang.Iterable[WeightedAvgAccum]): Unit = {
val iter = it.iterator()
while (iter.hasNext) {
val a = iter.next()
acc.count += a.count
acc.sum += a.sum
}
}
def resetAccumulator(acc: WeightedAvgAccum): Unit = {
acc.count = 0
acc.sum = 0L
}
override def getAccumulatorType: TypeInformation[WeightedAvgAccum] = {
new TupleTypeInfo(classOf[WeightedAvgAccum], Types.LONG, Types.INT)
}
override def getResultType: TypeInformation[JLong] = Types.LONG
}
// 注册函数
val tEnv: StreamTableEnvironment = ???
tEnv.registerFunction("wAvg", new WeightedAvg())
// 使用函数
tEnv.sqlQuery("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")
'''
Java code:
/**
* Accumulator for WeightedAvg.
*/
public static class WeightedAvgAccum {
public long sum = 0;
public int count = 0;
}
// The java class must have a public no-argument constructor and can be founded in current java classloader.
// Java 类必须有一个 public 的无参构造函数,并且可以在当前类加载器中加载到。
/**
* Weighted Average user-defined aggregate function.
*/
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccum> {
@Override
public WeightedAvgAccum createAccumulator() {
return new WeightedAvgAccum();
}
@Override
public Long getValue(WeightedAvgAccum acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccum acc, long iValue, int iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccum acc, Iterable<WeightedAvgAccum> it) {
Iterator<WeightedAvgAccum> iter = it.iterator();
while (iter.hasNext()) {
WeightedAvgAccum a = iter.next();
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccum acc) {
acc.count = 0;
acc.sum = 0L;
}
}
'''
# 注册函数
t_env = ... # type: StreamTableEnvironment
t_env.register_java_function("wAvg", "my.java.function.WeightedAvg")
# 使用函数
t_env.sql_query("SELECT user, wAvg(points, level) AS avgPoints FROM userScores GROUP BY user")
如果你打算使用 Python 实现或调用聚合函数,详情可参考 Python 聚合函数。
表值聚合函数 #
自定义表值聚合函数(UDTAGG)可以把一个表(一行或者多行,每行有一列或者多列)聚合成另一张表,结果中可以有多行多列。
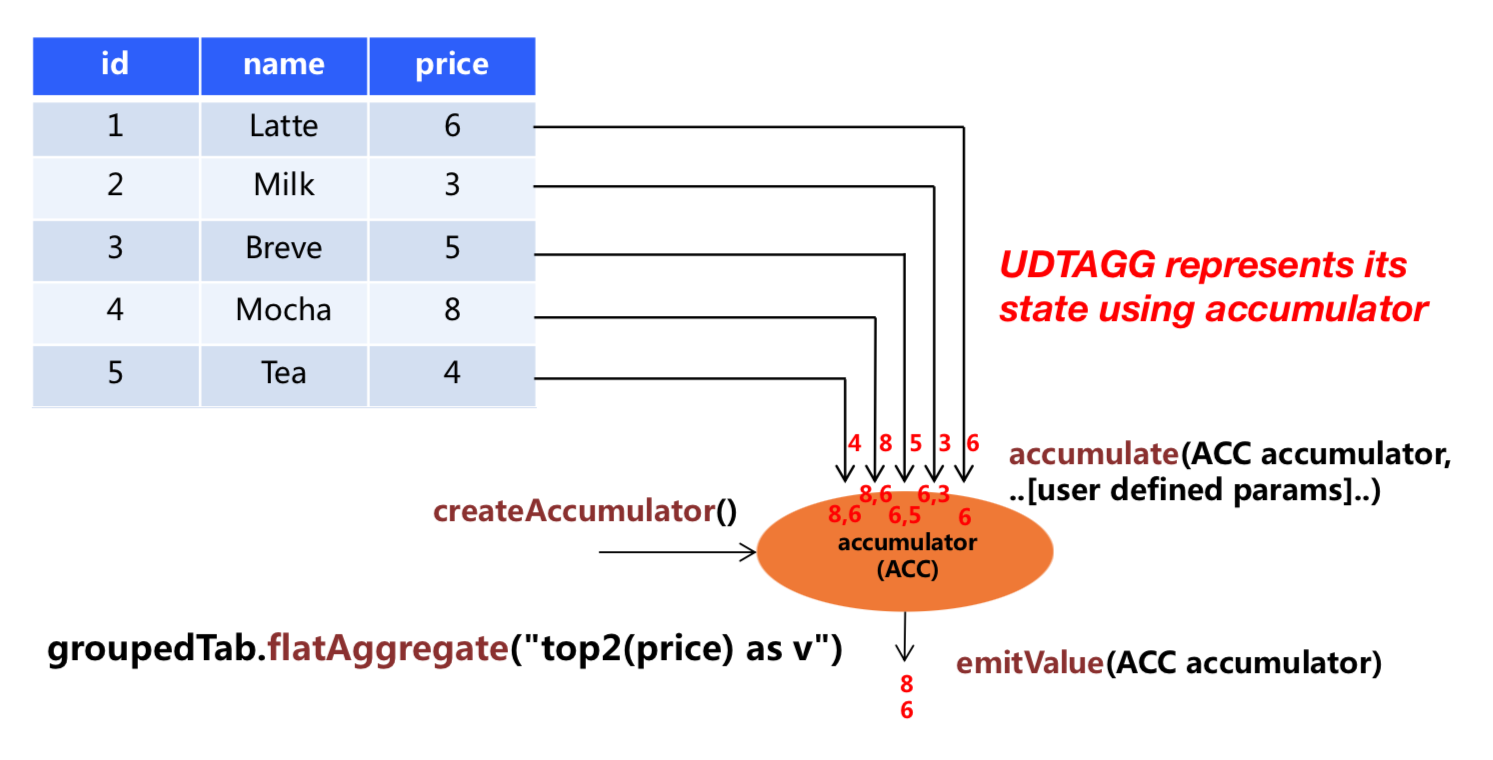
上图展示了一个表值聚合函数的例子。假设你有一个饮料的表,这个表有 3 列,分别是 id、name 和 price,一共有 5 行。假设你需要找到价格最高的两个饮料,类似于 top2() 表值聚合函数。你需要遍历所有 5 行数据,结果是有 2 行数据的一个表。
用户自定义表值聚合函数是通过扩展 TableAggregateFunction 类来实现的。一个 TableAggregateFunction 的工作过程如下。首先,它需要一个 accumulator,这个 accumulator 负责存储聚合的中间结果。 通过调用 TableAggregateFunction 的 createAccumulator 方法来构造一个空的 accumulator。接下来,对于每一行数据,会调用 accumulate 方法来更新 accumulator。当所有数据都处理完之后,调用 emitValue 方法来计算和返回最终的结果。
下面几个 TableAggregateFunction 的方法是必须要实现的:
createAccumulator()accumulate()
Flink 的类型推导在遇到复杂类型的时候可能会推导出错误的结果,比如那些非基本类型和普通的 POJO 类型的复杂类型。所以类似于 ScalarFunction 和 TableFunction,TableAggregateFunction 也提供了 TableAggregateFunction#getResultType() 和 TableAggregateFunction#getAccumulatorType() 方法来指定返回值类型和 accumulator 的类型,这两个方法都需要返回 TypeInformation。
除了上面的方法,还有几个其他的方法可以选择性的实现。有些方法可以让查询更加高效,而有些方法对于某些特定场景是必须要实现的。比如,在会话窗口(当两个会话窗口合并时会合并两个 accumulator)中使用聚合函数时,必须要实现merge() 方法。
下面几个 TableAggregateFunction 的方法在某些特定场景下是必须要实现的:
retract()在 boundedOVER窗口中的聚合函数必须要实现。merge()在许多批式聚合和以及流式会话和滑动窗口聚合中是必须要实现的。resetAccumulator()在许多批式聚合中是必须要实现的。emitValue()在批式聚合以及窗口聚合中是必须要实现的。
下面的 TableAggregateFunction 的方法可以提升流式任务的效率:
emitUpdateWithRetract()在 retract 模式下,该方法负责发送被更新的值。
emitValue 方法会发送所有 accumulator 给出的结果。拿 TopN 来说,emitValue 每次都会发送所有的最大的 n 个值。这在流式任务中可能会有一些性能问题。为了提升性能,用户可以实现 emitUpdateWithRetract 方法。这个方法在 retract 模式下会增量的输出结果,比如有数据更新了,我们必须要撤回老的数据,然后再发送新的数据。如果定义了 emitUpdateWithRetract 方法,那它会优先于 emitValue 方法被使用,因为一般认为 emitUpdateWithRetract 会更加高效,因为它的输出是增量的。
TableAggregateFunction 的所有方法都必须是 public 的、非 static 的,而且名字必须跟上面提到的一样。createAccumulator、getResultType 和 getAccumulatorType 这三个方法是在抽象父类 TableAggregateFunction 中定义的,而其他的方法都是约定的方法。要实现一个表值聚合函数,你必须扩展 org.apache.flink.table.functions.TableAggregateFunction,并且实现一个(或者多个)accumulate 方法。accumulate 方法可以有多个重载的方法,也可以支持变长参数。
TableAggregateFunction 的所有方法的详细文档如下。
/**
* Base class for user-defined aggregates and table aggregates.
*
* @param <T> the type of the aggregation result.
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
public abstract class UserDefinedAggregateFunction<T, ACC> extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
public ACC createAccumulator(); // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
public TypeInformation<T> getResultType = null; // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
public TypeInformation<ACC> getAccumulatorType = null; // PRE-DEFINED
}
/**
* Base class for table aggregation functions.
*
* @param <T> the type of the aggregation result
* @param <ACC> the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute a table aggregation result.
* TableAggregateFunction represents its state using accumulator, thereby the state of
* the TableAggregateFunction must be put into the accumulator.
*/
public abstract class TableAggregateFunction<T, ACC> extends UserDefinedAggregateFunction<T, ACC> {
/** Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. A TableAggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs]); // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs]); // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and bounded grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an {@link java.lang.Iterable} pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> its); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the collector used to output data
*/
public void emitValue(ACC accumulator, Collector<T> out); // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* Different from emitValue, emitUpdateWithRetract is used to emit values that have been updated.
* This method outputs data incrementally in retract mode, i.e., once there is an update, we
* have to retract old records before sending new updated ones. The emitUpdateWithRetract
* method will be used in preference to the emitValue method if both methods are defined in the
* table aggregate function, because the method is treated to be more efficient than emitValue
* as it can outputvalues incrementally.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the retractable collector used to output data. Use collect method
* to output(add) records and use retract method to retract(delete)
* records.
*/
public void emitUpdateWithRetract(ACC accumulator, RetractableCollector<T> out); // OPTIONAL
/**
* Collects a record and forwards it. The collector can output retract messages with the retract
* method. Note: only use it in {@code emitRetractValueIncrementally}.
*/
public interface RetractableCollector<T> extends Collector<T> {
/**
* Retract a record.
*
* @param record The record to retract.
*/
void retract(T record);
}
}
/**
* Base class for user-defined aggregates and table aggregates.
*
* @tparam T the type of the aggregation result.
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
*/
abstract class UserDefinedAggregateFunction[T, ACC] extends UserDefinedFunction {
/**
* Creates and init the Accumulator for this (table)aggregate function.
*
* @return the accumulator with the initial value
*/
def createAccumulator(): ACC // MANDATORY
/**
* Returns the TypeInformation of the (table)aggregate function's result.
*
* @return The TypeInformation of the (table)aggregate function's result or null if the result
* type should be automatically inferred.
*/
def getResultType: TypeInformation[T] = null // PRE-DEFINED
/**
* Returns the TypeInformation of the (table)aggregate function's accumulator.
*
* @return The TypeInformation of the (table)aggregate function's accumulator or null if the
* accumulator type should be automatically inferred.
*/
def getAccumulatorType: TypeInformation[ACC] = null // PRE-DEFINED
}
/**
* Base class for table aggregation functions.
*
* @tparam T the type of the aggregation result
* @tparam ACC the type of the aggregation accumulator. The accumulator is used to keep the
* aggregated values which are needed to compute an aggregation result.
* TableAggregateFunction represents its state using accumulator, thereby the state of
* the TableAggregateFunction must be put into the accumulator.
*/
abstract class TableAggregateFunction[T, ACC] extends UserDefinedAggregateFunction[T, ACC] {
/**
* Processes the input values and update the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. A TableAggregateFunction
* requires at least one accumulate() method.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit // MANDATORY
/**
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This function must be implemented for
* datastream bounded over aggregate.
*
* @param accumulator the accumulator which contains the current aggregated results
* @param [user defined inputs] the input value (usually obtained from a new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit // OPTIONAL
/**
* Merges a group of accumulator instances into one accumulator instance. This function must be
* implemented for datastream session window grouping aggregate and bounded grouping aggregate.
*
* @param accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* @param its an [[java.lang.Iterable]] pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, its: java.lang.Iterable[ACC]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the collector used to output data
*/
def emitValue(accumulator: ACC, out: Collector[T]): Unit // OPTIONAL
/**
* Called every time when an aggregation result should be materialized. The returned value
* could be either an early and incomplete result (periodically emitted as data arrive) or
* the final result of the aggregation.
*
* Different from emitValue, emitUpdateWithRetract is used to emit values that have been updated.
* This method outputs data incrementally in retract mode, i.e., once there is an update, we
* have to retract old records before sending new updated ones. The emitUpdateWithRetract
* method will be used in preference to the emitValue method if both methods are defined in the
* table aggregate function, because the method is treated to be more efficient than emitValue
* as it can outputvalues incrementally.
*
* @param accumulator the accumulator which contains the current
* aggregated results
* @param out the retractable collector used to output data. Use collect method
* to output(add) records and use retract method to retract(delete)
* records.
*/
def emitUpdateWithRetract(accumulator: ACC, out: RetractableCollector[T]): Unit // OPTIONAL
/**
* Collects a record and forwards it. The collector can output retract messages with the retract
* method. Note: only use it in `emitRetractValueIncrementally`.
*/
trait RetractableCollector[T] extends Collector[T] {
/**
* Retract a record.
*
* @param record The record to retract.
*/
def retract(record: T): Unit
}
}
下面的例子展示了如何
- 定义一个
TableAggregateFunction来计算给定列的最大的 2 个值, - 在
TableEnvironment中注册函数, - 在 Table API 查询中使用函数(当前只在 Table API 中支持 TableAggregateFunction)。
为了计算最大的 2 个值,accumulator 需要保存当前看到的最大的 2 个值。在我们的例子中,我们定义了类 Top2Accum 来作为 accumulator。Flink 的 checkpoint 机制会自动保存 accumulator,并且在失败时进行恢复,来保证精确一次的语义。
我们的 Top2 表值聚合函数(TableAggregateFunction)的 accumulate() 方法有两个输入,第一个是 Top2Accum accumulator,另一个是用户定义的输入:输入的值 v。尽管 merge() 方法在大多数聚合类型中不是必须的,我们也在样例中提供了它的实现。请注意,我们在 Scala 样例中也使用的是 Java 的基础类型,并且定义了 getResultType() 和 getAccumulatorType() 方法,因为 Flink 的类型推导对于 Scala 的类型推导支持的不是很好。
/**
* Accumulator for Top2.
*/
public class Top2Accum {
public Integer first;
public Integer second;
}
/**
* The top2 user-defined table aggregate function.
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {
for (Top2Accum otherAcc : iterable) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("top2", new Top2());
// 初始化表
Table tab = ...;
// 使用函数
tab.groupBy("key")
.flatAggregate("top2(a) as (v, rank)")
.select("key, v, rank");
import java.lang.{Integer => JInteger}
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.TableAggregateFunction
/**
* Accumulator for top2.
*/
class Top2Accum {
var first: JInteger = _
var second: JInteger = _
}
/**
* The top2 user-defined table aggregate function.
*/
class Top2 extends TableAggregateFunction[JTuple2[JInteger, JInteger], Top2Accum] {
override def createAccumulator(): Top2Accum = {
val acc = new Top2Accum
acc.first = Int.MinValue
acc.second = Int.MinValue
acc
}
def accumulate(acc: Top2Accum, v: Int) {
if (v > acc.first) {
acc.second = acc.first
acc.first = v
} else if (v > acc.second) {
acc.second = v
}
}
def merge(acc: Top2Accum, its: JIterable[Top2Accum]): Unit = {
val iter = its.iterator()
while (iter.hasNext) {
val top2 = iter.next()
accumulate(acc, top2.first)
accumulate(acc, top2.second)
}
}
def emitValue(acc: Top2Accum, out: Collector[JTuple2[JInteger, JInteger]]): Unit = {
// emit the value and rank
if (acc.first != Int.MinValue) {
out.collect(JTuple2.of(acc.first, 1))
}
if (acc.second != Int.MinValue) {
out.collect(JTuple2.of(acc.second, 2))
}
}
}
// 初始化表
val tab = ...
// 使用函数
tab
.groupBy('key)
.flatAggregate(top2('a) as ('v, 'rank))
.select('key, 'v, 'rank)
下面的例子展示了如何使用 emitUpdateWithRetract 方法来只发送更新的数据。为了只发送更新的结果,accumulator 保存了上一次的最大的2个值,也保存了当前最大的2个值。注意:如果 TopN 中的 n 非常大,这种既保存上次的结果,也保存当前的结果的方式不太高效。一种解决这种问题的方式是把输入数据直接存储到 accumulator 中,然后在调用 emitUpdateWithRetract 方法时再进行计算。
/**
* Accumulator for Top2.
*/
public class Top2Accum {
public Integer first;
public Integer second;
public Integer oldFirst;
public Integer oldSecond;
}
/**
* The top2 user-defined table aggregate function.
*/
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
acc.oldFirst = Integer.MIN_VALUE;
acc.oldSecond = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void emitUpdateWithRetract(Top2Accum acc, RetractableCollector<Tuple2<Integer, Integer>> out) {
if (!acc.first.equals(acc.oldFirst)) {
// if there is an update, retract old value then emit new value.
if (acc.oldFirst != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldFirst, 1));
}
out.collect(Tuple2.of(acc.first, 1));
acc.oldFirst = acc.first;
}
if (!acc.second.equals(acc.oldSecond)) {
// if there is an update, retract old value then emit new value.
if (acc.oldSecond != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldSecond, 2));
}
out.collect(Tuple2.of(acc.second, 2));
acc.oldSecond = acc.second;
}
}
}
// 注册函数
StreamTableEnvironment tEnv = ...
tEnv.registerFunction("top2", new Top2());
// 初始化表
Table tab = ...;
// 使用函数
tab.groupBy("key")
.flatAggregate("top2(a) as (v, rank)")
.select("key, v, rank");
import java.lang.{Integer => JInteger}
import org.apache.flink.table.api.Types
import org.apache.flink.table.functions.TableAggregateFunction
/**
* Accumulator for top2.
*/
class Top2Accum {
var first: JInteger = _
var second: JInteger = _
var oldFirst: JInteger = _
var oldSecond: JInteger = _
}
/**
* The top2 user-defined table aggregate function.
*/
class Top2 extends TableAggregateFunction[JTuple2[JInteger, JInteger], Top2Accum] {
override def createAccumulator(): Top2Accum = {
val acc = new Top2Accum
acc.first = Int.MinValue
acc.second = Int.MinValue
acc.oldFirst = Int.MinValue
acc.oldSecond = Int.MinValue
acc
}
def accumulate(acc: Top2Accum, v: Int) {
if (v > acc.first) {
acc.second = acc.first
acc.first = v
} else if (v > acc.second) {
acc.second = v
}
}
def emitUpdateWithRetract(
acc: Top2Accum,
out: RetractableCollector[JTuple2[JInteger, JInteger]])
: Unit = {
if (acc.first != acc.oldFirst) {
// if there is an update, retract old value then emit new value.
if (acc.oldFirst != Int.MinValue) {
out.retract(JTuple2.of(acc.oldFirst, 1))
}
out.collect(JTuple2.of(acc.first, 1))
acc.oldFirst = acc.first
}
if (acc.second != acc.oldSecond) {
// if there is an update, retract old value then emit new value.
if (acc.oldSecond != Int.MinValue) {
out.retract(JTuple2.of(acc.oldSecond, 2))
}
out.collect(JTuple2.of(acc.second, 2))
acc.oldSecond = acc.second
}
}
}
// 初始化表
val tab = ...
// 使用函数
tab
.groupBy('key)
.flatAggregate(top2('a) as ('v, 'rank))
.select('key, 'v, 'rank)