文件系统 #
连接器提供了 BATCH 模式和 STREAMING 模式统一的 Source 和 Sink。Flink FileSystem abstraction 支持连接器对文件系统进行(分区)文件读写。文件系统连接器为 BATCH 和 STREAMING 模式提供了相同的保证,而且对 STREAMING 模式执行提供了精确一次(exactly-once)语义保证。
连接器支持对任意(分布式的)文件系统(例如,POSIX、 S3、 HDFS)以某种数据格式 format (例如,Avro、 CSV、 Parquet) 对文件进行写入,或者读取后生成数据流或一组记录。
File Source #
File Source 是基于 Source API 同时支持批模式和流模式文件读取的统一 Source。
File Source 分为以下两个部分:SplitEnumerator 和 SourceReader。
SplitEnumerator负责发现和识别需要读取的文件,并将这些文件分配给SourceReader进行读取。SourceReader请求需要处理的文件,并从文件系统中读取该文件。
可能需要指定某种 format 与 File Source 联合进行解析 CSV、解码AVRO、或者读取 Parquet 列式文件。
有界流和无界流 #
有界的 File Source(通过 SplitEnumerator)列出所有文件(一个过滤出隐藏文件的递归目录列表)并读取。
无界的 File Source 由配置定期扫描文件的 enumerator 创建。
在无界的情况下,SplitEnumerator 将像有界的 File Source 一样列出所有文件,但是不同的是,经过一个时间间隔之后,重复上述操作。
对于每一次列举操作,SplitEnumerator 会过滤掉之前已经检测过的文件,将新扫描到的文件发送给 SourceReader。
使用方法 #
可以通过调用以下 API 建立一个 File Source:
// 从文件流中读取文件内容
FileSource.forRecordStreamFormat(StreamFormat,Path...);
// 从文件中一次读取一批记录
FileSource.forBulkFileFormat(BulkFormat,Path...);
# 从文件流中读取文件内容
FileSource.for_record_stream_format(stream_format, *path)
# 从文件中一次读取一批记录
FileSource.for_bulk_file_format(bulk_format, *path)
可以通过创建 FileSource.FileSourceBuilder 设置 File Source 的所有参数。
对于有界/批的使用场景,File Source 需要处理给定路径下的所有文件。 对于无界/流的使用场景,File Source 会定期检查路径下的新文件并读取。
当创建一个 File Source 时(通过上述任意方法创建的 FileSource.FileSourceBuilder),
默认情况下,Source 为有界/批的模式。可以调用 AbstractFileSource.AbstractFileSourceBuilder.monitorContinuously(Duration) 设置 Source 为持续的流模式。
final FileSource<String> source =
FileSource.forRecordStreamFormat(...)
.monitorContinuously(Duration.ofMillis(5))
.build();
source = FileSource.for_record_stream_format(...) \
.monitor_continously(Duration.of_millis(5)) \
.build()
Format Types #
通过 file formats 定义的文件 readers 读取每个文件。 其中定义了解析和读取文件内容的逻辑。Source 支持多个解析类。 这些接口是实现简单性和灵活性/效率之间的折衷。
-
StreamFormat从文件流中读取文件内容。它是最简单的格式实现, 并且提供了许多拆箱即用的特性(如 Checkpoint 逻辑),但是限制了可应用的优化(例如对象重用,批处理等等)。 -
BulkFormat从文件中一次读取一批记录。 它虽然是最 “底层” 的格式实现,但是提供了优化实现的最大灵活性。
TextLine Format #
使用 StreamFormat 格式化文件中的文本行。
Java 中内置的 InputStreamReader 对使用了支持各种字符集的字节流进行解码。
此格式不支持从 Checkpoint 进行恢复优化。在恢复时,将重新读取并放弃在最后一个 Checkpoint 之前处理的行数。
这是由于无法通过字符集解码器追踪文件中的行偏移量,及其内部缓冲输入流和字符集解码器的状态。
SimpleStreamFormat 抽象类 #
这是 StreamFormat 的简单版本,适用于不可拆分的格式。
可以通过实现 SimpleStreamFormat 接口自定义读取数组或文件:
private static final class ArrayReaderFormat extends SimpleStreamFormat<byte[]> {
private static final long serialVersionUID = 1L;
@Override
public Reader<byte[]> createReader(Configuration config, FSDataInputStream stream)
throws IOException {
return new ArrayReader(stream);
}
@Override
public TypeInformation<byte[]> getProducedType() {
return PrimitiveArrayTypeInfo.BYTE_PRIMITIVE_ARRAY_TYPE_INFO;
}
}
final FileSource<byte[]> source =
FileSource.forRecordStreamFormat(new ArrayReaderFormat(), path).build();
CsvReaderFormat 是一个实现 SimpleStreamFormat 接口的例子。类似这样进行初始化:
CsvReaderFormat<SomePojo> csvFormat = CsvReaderFormat.forPojo(SomePojo.class);
FileSource<SomePojo> source =
FileSource.forRecordStreamFormat(csvFormat, Path.fromLocalFile(...)).build();
对于 CSV Format 的解析,在这个例子中,是根据使用 Jackson 库的 SomePojo 的字段自动生成的。(注意:可能需要添加 @JsonPropertyOrder({field1, field2, ...}) 这个注释到自定义的类上,并且字段顺序与 CSV 文件列的顺序完全匹配)。
如果需要对 CSV 模式或解析选项进行更细粒度的控制,可以使用 CsvReaderFormat 的更底层的 forSchema 静态工厂方法:
CsvReaderFormat<T> forSchema(Supplier<CsvMapper> mapperFactory,
Function<CsvMapper, CsvSchema> schemaGenerator,
TypeInformation<T> typeInformation)
Bulk Format #
BulkFormat 一次读取并解析一批记录。BulkFormat 的实现包括 ORC Format或 Parquet Format等。
外部的 BulkFormat 类主要充当 reader 的配置持有者和工厂角色。BulkFormat.Reader 是在 BulkFormat#createReader(Configuration, FileSourceSplit) 方法中创建的,然后完成读取操作。如果在流的 checkpoint 执行期间基于 checkpoint 创建 Bulk reader,那么 reader 是在 BulkFormat#restoreReader(Configuration, FileSourceSplit) 方法中重新创建的。
可以通过将 SimpleStreamFormat 包装在 StreamFormatAdapter 中转换为 BulkFormat:
BulkFormat<SomePojo, FileSourceSplit> bulkFormat =
new StreamFormatAdapter<>(CsvReaderFormat.forPojo(SomePojo.class));
自定义文件枚举类 #
/**
* 针对 Hive 数据源的 FileEnumerator 实现类,基于 HiveTablePartition 生成拆分文件
*/
public class HiveSourceFileEnumerator implements FileEnumerator {
// 构造方法
public HiveSourceFileEnumerator(...) {
...
}
/***
* 拆分给定路径下的所有相关文件。{@code
* minDesiredSplits} 是一个可选项,代表需要多少次拆分才能正确利用并行度
*/
@Override
public Collection<FileSourceSplit> enumerateSplits(Path[] paths, int minDesiredSplits)
throws IOException {
// createInputSplits:splitting files into fragmented collections
return new ArrayList<>(createInputSplits(...));
}
...
/***
* 创建 HiveSourceFileEnumerator 的工厂
*/
public static class Provider implements FileEnumerator.Provider {
...
@Override
public FileEnumerator create() {
return new HiveSourceFileEnumerator(...);
}
}
}
// 使用自定义文件枚举类
new HiveSource<>(
...,
new HiveSourceFileEnumerator.Provider(
partitions != null ? partitions : Collections.emptyList(),
new JobConfWrapper(jobConf)),
...);
当前限制 #
对于大量积压的文件,Watermark 效果不佳。这是因为 Watermark 急于在一个文件中推进,而下一个文件可能包含比 Watermark 更晚的数据。
对于无界 File Sources,枚举器会会将当前所有已处理文件的路径记录到 state 中,在某些情况下,这可能会导致状态变得相当大。 未来计划将引入一种压缩的方式来跟踪已经处理的文件(例如,将修改时间戳保持在边界以下)。
后记 #
如果对新设计的 Source API 中的 File Sources 是如何工作的感兴趣,可以阅读本部分作为参考。关于新的 Source API 的更多细节,请参考 documentation on data sources 和在 FLIP-27 中获取更加具体的讨论详情。
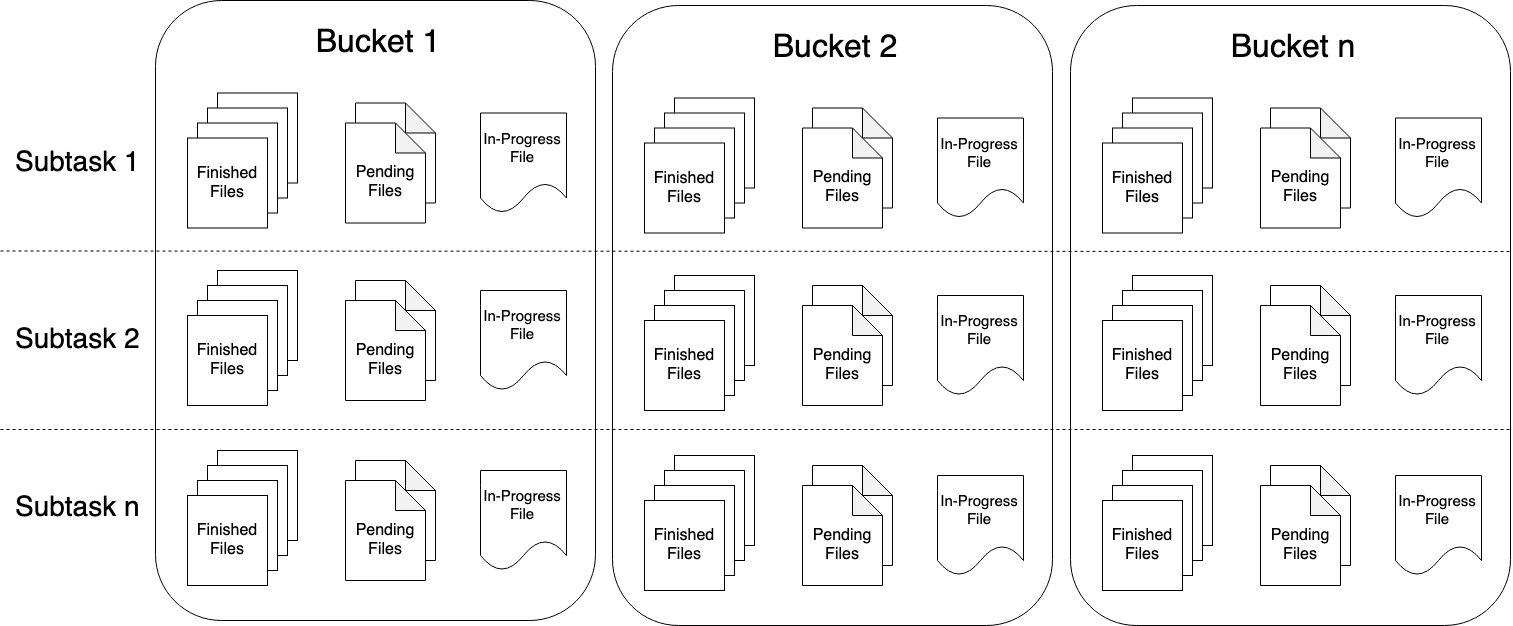
File Sink #
File Sink 将传入的数据写入存储桶中。考虑到输入流可以是无界的,每个桶中的数据被组织成有限大小的 Part 文件。 完全可以配置为基于时间的方式往桶中写入数据,比如可以设置每个小时的数据写入一个新桶中。这意味着桶中将包含一个小时间隔内接收到的记录。
桶目录中的数据被拆分成多个 Part 文件。对于相应的接收数据的桶的 Sink 的每个 Subtask,每个桶将至少包含一个 Part 文件。将根据配置的滚动策略来创建其他 Part 文件。
对于 Row-encoded Formats(参考 Format Types)默认的策略是根据 Part 文件大小进行滚动,需要指定文件打开状态最长时间的超时以及文件关闭后的非活动状态的超时时间。
对于 Bulk-encoded Formats 在每次创建 Checkpoint 时进行滚动,并且用户也可以添加基于大小或者时间等的其他条件。
重要: 在STREAMING模式下使用FileSink需要开启 Checkpoint 功能。 文件只在 Checkpoint 成功时生成。如果没有开启 Checkpoint 功能,文件将永远停留在in-progress或者pending的状态,并且下游系统将不能安全读取该文件数据。
Format Types #
FileSink 不仅支持 Row-encoded 也支持 Bulk-encoded,例如 Apache Parquet。
这两种格式可以通过如下的静态方法进行构造:
- Row-encoded sink:
FileSink.forRowFormat(basePath, rowEncoder) - Bulk-encoded sink:
FileSink.forBulkFormat(basePath, bulkWriterFactory)
不论创建 Row-encoded Format 或者 Bulk-encoded Format 的 Sink 时,都必须指定桶的路径以及对数据进行编码的逻辑。
请参考 JavaDoc 文档 FileSink 来获取所有的配置选项以及更多的不同数据格式实现的详细信息。
Row-encoded Formats #
Row-encoded Format 需要指定一个 Encoder,在输出数据到文件过程中被用来将单个行数据序列化为 OutputStream。
除了 bucket assigner,RowFormatBuilder 还允许用户指定以下属性:
- Custom RollingPolicy :自定义滚动策略覆盖 DefaultRollingPolicy
- bucketCheckInterval (默认值 = 1 min) :基于滚动策略设置的检查时间间隔
写入字符串的基本用法如下:
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.core.fs.Path;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
DataStream<String> input = ...;
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(15))
.withInactivityInterval(Duration.ofMinutes(5))
.withMaxPartSize(MemorySize.ofMebiBytes(1024))
.build())
.build();
input.sinkTo(sink);
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.configuration.MemorySize
import org.apache.flink.connector.file.sink.FileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import java.time.Duration
val input: DataStream[String] = ...
val sink: FileSink[String] = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(15))
.withInactivityInterval(Duration.ofMinutes(5))
.withMaxPartSize(MemorySize.ofMebiBytes(1024))
.build())
.build()
input.sinkTo(sink)
data_stream = ...
sink = FileSink \
.for_row_format(OUTPUT_PATH, Encoder.simple_string_encoder("UTF-8")) \
.with_rolling_policy(RollingPolicy.default_rolling_policy(
part_size=1024 ** 3, rollover_interval=15 * 60 * 1000, inactivity_interval=5 * 60 * 1000)) \
.build()
data_stream.sink_to(sink)
这个例子中创建了一个简单的 Sink,默认的将记录分配给小时桶。 例子中还指定了滚动策略,当满足以下三个条件的任何一个时都会将 In-progress 状态文件进行滚动:
- 包含了至少15分钟的数据量
- 从没接收延时5分钟之外的新纪录
- 文件大小已经达到 1GB(写入最后一条记录之后)
Bulk-encoded Formats #
Bulk-encoded 的 Sink 的创建和 Row-encoded 的相似,但不需要指定 Encoder,而是需要指定 BulkWriter.Factory,请参考文档
BulkWriter.Factory
。
BulkWriter 定义了如何添加和刷新新数据以及如何最终确定一批记录使用哪种编码字符集的逻辑。
Flink 内置了5种 BulkWriter 工厂类:
- ParquetWriterFactory
- AvroWriterFactory
- SequenceFileWriterFactory
- CompressWriterFactory
- OrcBulkWriterFactory
重要 Bulk-encoded Format 仅支持一种继承了 CheckpointRollingPolicy 类的滚动策略。
在每个 Checkpoint 都会滚动。另外也可以根据大小或处理时间进行滚动。
Parquet Format #
Flink 内置了为 Avro Format 数据创建 Parquet 写入工厂的快捷方法。在 AvroParquetWriters 类中可以发现那些方法以及相关的使用说明。
为了让 Parquet Format 数据写入更加通用,用户需要创建 ParquetWriterFactory 并且自定义实现 ParquetBuilder 接口。
如果在程序中使用 Parquet 的 Bulk-encoded Format,需要添加如下依赖到项目中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>1.18.1</version>
</dependency>为了在 PyFlink 作业中使用 Parquet format ,需要添加下列依赖:
| PyFlink JAR |
|---|
| Download |
类似这样使用 FileSink 写入 Parquet Format 的 Avro 数据:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.avro.AvroParquetWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> input = ...;
final FileSink<GenericRecord> sink = FileSink
.forBulkFormat(outputBasePath, AvroParquetWriters.forGenericRecord(schema))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.avro.AvroParquetWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: FileSink[GenericRecord] = FileSink
.forBulkFormat(outputBasePath, AvroParquetWriters.forGenericRecord(schema))
.build()
input.sinkTo(sink)
schema = AvroSchema.parse_string(JSON_SCHEMA)
# data_stream 的数据类型可以为符合 schema 的原生 Python 数据结构,其类型为默认的 Types.PICKLED_BYTE_ARRAY()
data_stream = ...
avro_type_info = GenericRecordAvroTypeInfo(schema)
sink = FileSink \
.for_bulk_format(OUTPUT_BASE_PATH, AvroParquetWriters.for_generic_record(schema)) \
.build()
# 必须通过 map 操作来指定其 Avro 类型信息,用于数据的序列化
data_stream.map(lambda e: e, output_type=avro_type_info).sink_to(sink)
类似这样使用 FileSink 写入 Parquet Format 的 Protobuf 数据:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.protobuf.ParquetProtoWriters;
// ProtoRecord 是一个生成 protobuf 的类
DataStream<ProtoRecord> input = ...;
final FileSink<ProtoRecord> sink = FileSink
.forBulkFormat(outputBasePath, ParquetProtoWriters.forType(ProtoRecord.class))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.parquet.protobuf.ParquetProtoWriters
// ProtoRecord 是一个生成 protobuf 的类
val input: DataStream[ProtoRecord] = ...
val sink: FileSink[ProtoRecord] = FileSink
.forBulkFormat(outputBasePath, ParquetProtoWriters.forType(classOf[ProtoRecord]))
.build()
input.sinkTo(sink)
PyFlink 用户可以使用 ParquetBulkWriters 来创建一个将 Row 数据写入 Parquet 文件的 BulkWriterFactory 。
row_type = DataTypes.ROW([
DataTypes.FIELD('string', DataTypes.STRING()),
DataTypes.FIELD('int_array', DataTypes.ARRAY(DataTypes.INT()))
])
sink = FileSink.for_bulk_format(
OUTPUT_DIR, ParquetBulkWriters.for_row_type(
row_type,
hadoop_config=Configuration(),
utc_timestamp=True,
)
).build()
ds.sink_to(sink)
Avro Format #
Flink 也支持写入数据到 Avro Format 文件。在 AvroWriters 类中可以发现一系列创建 Avro writer 工厂的便利方法及其相关说明。
如果在程序中使用 AvroWriters,需要添加如下依赖到项目中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>1.18.1</version>
</dependency>为了在 PyFlink 作业中使用 Avro format ,需要添加下列依赖:
| PyFlink JAR |
|---|
| Download |
类似这样使用 FileSink 写入数据到 Avro Format 文件中:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.avro.AvroWriters;
import org.apache.avro.Schema;
Schema schema = ...;
DataStream<GenericRecord> input = ...;
final FileSink<GenericRecord> sink = FileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.formats.avro.AvroWriters
import org.apache.avro.Schema
val schema: Schema = ...
val input: DataStream[GenericRecord] = ...
val sink: FileSink[GenericRecord] = FileSink
.forBulkFormat(outputBasePath, AvroWriters.forGenericRecord(schema))
.build()
input.sinkTo(sink)
schema = AvroSchema.parse_string(JSON_SCHEMA)
# data_stream 的数据类型可以为符合 schema 的原生 Python 数据结构,其类型为默认的 Types.PICKLED_BYTE_ARRAY()
data_stream = ...
avro_type_info = GenericRecordAvroTypeInfo(schema)
sink = FileSink \
.for_bulk_format(OUTPUT_BASE_PATH, AvroBulkWriters.for_generic_record(schema)) \
.build()
# 必须通过 map 操作来指定其 Avro 类型信息,用于数据的序列化
data_stream.map(lambda e: e, output_type=avro_type_info).sink_to(sink)
对于自定义创建的 Avro writers,例如,支持压缩功能,用户需要创建 AvroWriterFactory 并且自定义实现 AvroBuilder 接口:
AvroWriterFactory<?> factory = new AvroWriterFactory<>((AvroBuilder<Address>) out -> {
Schema schema = ReflectData.get().getSchema(Address.class);
DatumWriter<Address> datumWriter = new ReflectDatumWriter<>(schema);
DataFileWriter<Address> dataFileWriter = new DataFileWriter<>(datumWriter);
dataFileWriter.setCodec(CodecFactory.snappyCodec());
dataFileWriter.create(schema, out);
return dataFileWriter;
});
DataStream<Address> stream = ...
stream.sinkTo(FileSink.forBulkFormat(
outputBasePath,
factory).build());
val factory = new AvroWriterFactory[Address](new AvroBuilder[Address]() {
override def createWriter(out: OutputStream): DataFileWriter[Address] = {
val schema = ReflectData.get.getSchema(classOf[Address])
val datumWriter = new ReflectDatumWriter[Address](schema)
val dataFileWriter = new DataFileWriter[Address](datumWriter)
dataFileWriter.setCodec(CodecFactory.snappyCodec)
dataFileWriter.create(schema, out)
dataFileWriter
}
})
val stream: DataStream[Address] = ...
stream.sinkTo(FileSink.forBulkFormat(
outputBasePath,
factory).build());
ORC Format #
ORC Format 的数据采用 Bulk-encoded Format,Flink 提供了 Vectorizer 接口的具体实现类 OrcBulkWriterFactory。
像其他列格式一样也是采用 Bulk-encoded Format,Flink 中 OrcBulkWriter 是使用 ORC 的 VectorizedRowBatch 实现批的方式输出数据的。
由于输入数据已经被转换成了 VectorizedRowBatch,所以用户必须继承抽象类 Vectorizer 并且覆写类中 vectorize(T element, VectorizedRowBatch batch) 这个方法。正如看到的那样,此方法中提供了用户直接使用的 VectorizedRowBatch 类的实例,因此,用户不得不编写从输入 element 到 ColumnVectors 的转换逻辑,然后设置在 VectorizedRowBatch 实例中。
例如,如果是 Person 类型的输入元素,如下所示:
class Person {
private final String name;
private final int age;
...
}
然后,转换 Person 类型元素的实现并在 VectorizedRowBatch 中设置,如下所示:
import org.apache.hadoop.hive.ql.exec.vector.BytesColumnVector;
import org.apache.hadoop.hive.ql.exec.vector.LongColumnVector;
import java.io.IOException;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
public PersonVectorizer(String schema) {
super(schema);
}
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
BytesColumnVector nameColVector = (BytesColumnVector) batch.cols[0];
LongColumnVector ageColVector = (LongColumnVector) batch.cols[1];
int row = batch.size++;
nameColVector.setVal(row, element.getName().getBytes(StandardCharsets.UTF_8));
ageColVector.vector[row] = element.getAge();
}
}
import java.nio.charset.StandardCharsets
import org.apache.hadoop.hive.ql.exec.vector.{BytesColumnVector, LongColumnVector}
class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
val nameColVector = batch.cols(0).asInstanceOf[BytesColumnVector]
val ageColVector = batch.cols(1).asInstanceOf[LongColumnVector]
nameColVector.setVal(batch.size + 1, element.getName.getBytes(StandardCharsets.UTF_8))
ageColVector.vector(batch.size + 1) = element.getAge
}
}
如果在程序中使用 ORC 的 Bulk-encoded Format,需要添加如下依赖到项目中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc</artifactId>
<version>1.18.1</version>
</dependency>然后,类似这样使用 FileSink 以 ORC Format 输出数据:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.orc.writer.OrcBulkWriterFactory;
String schema = "struct<_col0:string,_col1:int>";
DataStream<Person> input = ...;
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(new PersonVectorizer(schema));
final FileSink<Person> sink = FileSink
.forBulkFormat(outputBasePath, writerFactory)
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.orc.writer.OrcBulkWriterFactory
val schema: String = "struct<_col0:string,_col1:int>"
val input: DataStream[Person] = ...
val writerFactory = new OrcBulkWriterFactory(new PersonVectorizer(schema));
val sink: FileSink[Person] = FileSink
.forBulkFormat(outputBasePath, writerFactory)
.build()
input.sinkTo(sink)
OrcBulkWriterFactory 还可以采用 Hadoop 的 Configuration 和 Properties,这样就可以提供自定义的 Hadoop 配置 和 ORC 输出属性。
String schema = ...;
Configuration conf = ...;
Properties writerProperties = new Properties();
writerProperties.setProperty("orc.compress", "LZ4");
// 其他 ORC 属性也可以使用类似方式进行设置
final OrcBulkWriterFactory<Person> writerFactory = new OrcBulkWriterFactory<>(
new PersonVectorizer(schema), writerProperties, conf);
val schema: String = ...
val conf: Configuration = ...
val writerProperties: Properties = new Properties()
writerProperties.setProperty("orc.compress", "LZ4")
// 其他 ORC 属性也可以使用类似方式进行设置
val writerFactory = new OrcBulkWriterFactory(
new PersonVectorizer(schema), writerProperties, conf)
完整的 ORC 输出属性列表可以参考 此文档 。
用户在重写 vectorize(...) 方法时可以调用 addUserMetadata(...) 方法来添加自己的元数据到 ORC 文件中。
public class PersonVectorizer extends Vectorizer<Person> implements Serializable {
@Override
public void vectorize(Person element, VectorizedRowBatch batch) throws IOException {
...
String metadataKey = ...;
ByteBuffer metadataValue = ...;
this.addUserMetadata(metadataKey, metadataValue);
}
}
class PersonVectorizer(schema: String) extends Vectorizer[Person](schema) {
override def vectorize(element: Person, batch: VectorizedRowBatch): Unit = {
...
val metadataKey: String = ...
val metadataValue: ByteBuffer = ...
addUserMetadata(metadataKey, metadataValue)
}
}
PyFlink 用户可以使用 OrcBulkWriters 来创建将数据写入 Orc 文件的 BulkWriterFactory 。
为了在 PyFlink 作业中使用 ORC format ,需要添加下列依赖:
| PyFlink JAR |
|---|
| Download |
row_type = DataTypes.ROW([
DataTypes.FIELD('name', DataTypes.STRING()),
DataTypes.FIELD('age', DataTypes.INT()),
])
sink = FileSink.for_bulk_format(
OUTPUT_DIR,
OrcBulkWriters.for_row_type(
row_type=row_type,
writer_properties=Configuration(),
hadoop_config=Configuration(),
)
).build()
ds.sink_to(sink)
Hadoop SequenceFile Format #
如果在程序中使用 SequenceFile 的 Bulk-encoded Format,需要添加如下依赖到项目中:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sequence-file</artifactId>
<version>1.18.1</version>
</dependency>类似这样创建一个简单的 SequenceFile:
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.configuration.GlobalConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
DataStream<Tuple2<LongWritable, Text>> input = ...;
Configuration hadoopConf = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration());
final FileSink<Tuple2<LongWritable, Text>> sink = FileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory<>(hadoopConf, LongWritable.class, Text.class))
.build();
input.sinkTo(sink);
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.configuration.GlobalConfiguration
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.SequenceFile
import org.apache.hadoop.io.Text;
val input: DataStream[(LongWritable, Text)] = ...
val hadoopConf: Configuration = HadoopUtils.getHadoopConfiguration(GlobalConfiguration.loadConfiguration())
val sink: FileSink[(LongWritable, Text)] = FileSink
.forBulkFormat(
outputBasePath,
new SequenceFileWriterFactory(hadoopConf, LongWritable.class, Text.class))
.build()
input.sinkTo(sink)
SequenceFileWriterFactory 提供额外的构造参数设置是否开启压缩功能。
桶分配 #
桶的逻辑定义了如何将数据分配到基本输出目录内的子目录中。
Row-encoded Format 和 Bulk-encoded Format (参考 Format Types) 使用了 DateTimeBucketAssigner 作为默认的分配器。
默认的分配器 DateTimeBucketAssigner 会基于使用了格式为 yyyy-MM-dd--HH 的系统默认时区来创建小时桶。日期格式( 即 桶大小)和时区都可以手动配置。
还可以在格式化构造器中通过调用 .withBucketAssigner(assigner) 方法指定自定义的 BucketAssigner。
Flink 内置了两种 BucketAssigners:
DateTimeBucketAssigner:默认的基于时间的分配器BasePathBucketAssigner:分配所有文件存储在基础路径上(单个全局桶)
PyFlink 只支持DateTimeBucketAssigner和BasePathBucketAssigner。
滚动策略 #
RollingPolicy 定义了何时关闭给定的 In-progress Part 文件,并将其转换为 Pending 状态,然后在转换为 Finished 状态。
Finished 状态的文件,可供查看并且可以保证数据的有效性,在出现故障时不会恢复。
在 STREAMING 模式下,滚动策略结合 Checkpoint 间隔(到下一个 Checkpoint 成功时,文件的 Pending 状态才转换为 Finished 状态)共同控制 Part 文件对下游 readers 是否可见以及这些文件的大小和数量。在 BATCH 模式下,Part 文件在 Job 最后对下游才变得可见,滚动策略只控制最大的 Part 文件大小。
Flink 内置了两种 RollingPolicies:
DefaultRollingPolicyOnCheckpointRollingPolicy
PyFlink 只支持DefaultRollingPolicy和OnCheckpointRollingPolicy。
Part 文件生命周期 #
为了在下游使用 FileSink 作为输出,需要了解生成的输出文件的命名和生命周期。
Part 文件可以处于以下三种状态中的任意一种:
- In-progress :当前正在写入的 Part 文件处于 in-progress 状态
- Pending :由于指定的滚动策略)关闭 in-progress 状态文件,并且等待提交
- Finished :流模式(
STREAMING)下的成功的 Checkpoint 或者批模式(BATCH)下输入结束,文件的 Pending 状态转换为 Finished 状态
只有 Finished 状态下的文件才能被下游安全读取,并且保证不会被修改。
对于每个活动的桶,在任何给定时间每个写入 Subtask 中都有一个 In-progress 状态的 Part 文件,但可能有多个 Pending 状态和 Finished 状态的文件。
Part 文件示例
为了更好的了解这些文件的生命周期,让我们看一个只有 2 个 Sink Subtask 的简单例子:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
└── part-81fc4980-a6af-41c8-9937-9939408a734b-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
当这个 Part 文件 part-81fc4980-a6af-41c8-9937-9939408a734b-0 滚动时(比如说此文件变的很大时),此文件将进入 Pending 状态并且不能重命名。Sink 就会打开一个新的 Part 文件: part-81fc4980-a6af-41c8-9937-9939408a734b-1:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0.inprogress.ea65a428-a1d0-4a0b-bbc5-7a436a75e575
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
part-81fc4980-a6af-41c8-9937-9939408a734b-0 现在是 Pending 状态,并且在下一个 Checkpoint 成功过后,立即成为 Finished 状态:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
根据桶策略创建新桶时,不会影响当前 In-progress 状态的文件:
└── 2019-08-25--12
├── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── part-81fc4980-a6af-41c8-9937-9939408a734b-0
└── part-81fc4980-a6af-41c8-9937-9939408a734b-1.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
└── 2019-08-25--13
└── part-4005733d-a830-4323-8291-8866de98b582-0.inprogress.2b475fec-1482-4dea-9946-eb4353b475f1
旧桶仍然可以接收新记录,因为桶策略是在每条记录上进行评估的。
Part 文件配置 #
Finished 状态与 In-progress 状态的文件只能通过命名来区分。
默认的,文件命名策略如下:
- In-progress / Pending:
part-<uid>-<partFileIndex>.inprogress.uid - Finished:
part-<uid>-<partFileIndex>当 Sink Subtask 实例化时,这的uid是一个分配给 Subtask 的随机 ID 值。这个uid不具有容错机制,所以当 Subtask 从故障恢复时,uid会重新生成。
Flink 允许用户给 Part 文件名添加一个前缀和/或后缀。
使用 OutputFileConfig 来完成上述功能。
例如,Sink 将在创建文件的文件名上添加前缀 “prefix” 和后缀 “.ext”,如下所示:
└── 2019-08-25--12
├── prefix-4005733d-a830-4323-8291-8866de98b582-0.ext
├── prefix-4005733d-a830-4323-8291-8866de98b582-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-81fc4980-a6af-41c8-9937-9939408a734b-0.ext
└── prefix-81fc4980-a6af-41c8-9937-9939408a734b-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
用户也可以使用 OutputFileConfig 采用如下方式添加前缀和后缀:
OutputFileConfig config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build();
FileSink<Tuple2<Integer, Integer>> sink = FileSink
.forRowFormat((new Path(outputPath), new SimpleStringEncoder<>("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build();
val config = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".ext")
.build()
val sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder[String]("UTF-8"))
.withBucketAssigner(new KeyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(config)
.build()
config = OutputFileConfig \
.builder() \
.with_part_prefix("prefix") \
.with_part_suffix(".ext") \
.build()
sink = FileSink \
.for_row_format(OUTPUT_PATH, Encoder.simple_string_encoder("UTF-8")) \
.with_bucket_assigner(BucketAssigner.base_path_bucket_assigner()) \
.with_rolling_policy(RollingPolicy.on_checkpoint_rolling_policy()) \
.with_output_file_config(config) \
.build()
文件合并 #
从 1.15 版本开始 FileSink 开始支持已经提交 pending 文件的合并,从而允许应用设置一个较小的时间周期并且避免生成大量的小文件。
尤其是当用户使用 bulk 格式 的时候:
这种格式要求用户必须在 checkpoint 的时候切换文件。
文件合并功能可以通过以下代码打开:
FileSink<Integer> fileSink=
FileSink.forRowFormat(new Path(path),new SimpleStringEncoder<Integer>())
.enableCompact(
FileCompactStrategy.Builder.newBuilder()
.setNumCompactThreads(1024)
.enableCompactionOnCheckpoint(5)
.build(),
new RecordWiseFileCompactor<>(
new DecoderBasedReader.Factory<>(SimpleStringDecoder::new)))
.build();
val fileSink: FileSink[Integer] =
FileSink.forRowFormat(new Path(path), new SimpleStringEncoder[Integer]())
.enableCompact(
FileCompactStrategy.Builder.newBuilder()
.setNumCompactThreads(1024)
.enableCompactionOnCheckpoint(5)
.build(),
new RecordWiseFileCompactor(
new DecoderBasedReader.Factory(() => new SimpleStringDecoder)))
.build()
file_sink = FileSink \
.for_row_format(PATH, Encoder.simple_string_encoder()) \
.enable_compact(
FileCompactStrategy.builder()
.set_size_threshold(1024)
.enable_compaction_on_checkpoint(5)
.build(),
FileCompactor.concat_file_compactor()) \
.build()
这一功能开启后,在文件转为 pending 状态与文件最终提交之间会进行文件合并。这些 pending 状态的文件将首先被提交为一个以 . 开头的
临时文件。这些文件随后将会按照用户指定的策略和合并方式进行合并并生成合并后的 pending 状态的文件。
然后这些文件将被发送给 Committer 并提交为正式文件,在这之后,原始的临时文件也会被删除掉。
当开启文件合并功能时,用户需要指定 FileCompactStrategy 与 FileCompactor 。
FileCompactStrategy
指定何时以及哪些文件将被合并。
目前有两个并行的条件:目标文件大小与间隔的 Checkpoint 数量。当目前缓存的文件的总大小达到指定的阈值,或自上次合并后经过的 Checkpoint 次数已经达到指定次数时,
FileSink 将创建一个异步任务来合并当前缓存的文件。
FileCompactor 指定如何将给定的路径列表对应的文件进行合并将结果写入到文件中。 根据如何写文件,它可以分为两类:
-
OutputStreamBasedFileCompactor
:
用户将合并后的结果写入一个输出流中。通常在用户不希望或者无法从输入文件中读取记录时使用。这种类型的
CompactingFileWriter的一个例子是 ConcatFileCompactor ,它直接将给定的文件进行合并并将结果写到输出流中。 -
RecordWiseFileCompactor
:
这种类型的
CompactingFileWriter会逐条读出输入文件的记录用户,然后和FileWriter一样写入输出文件中。CompactingFileWriter的一个例子是 RecordWiseFileCompactor ,它从给定的文件中读出记录并写出到CompactingFileWriter中。用户需要指定如何从原始文件中读出记录。
注意事项1 一旦启用了文件合并功能,此后若需要再关闭,必须在构建
FileSink时显式调用disableCompact方法。注意事项2 如果启用了文件合并功能,文件可见的时间会被延长。
PyFlink 只支持ConcatFileCompactor和IdenticalFileCompactor。
重要注意事项 #
通用注意事项 #
注意事项 1:当使用的 Hadoop 版本 < 2.7 时,
当每次 Checkpoint 时请使用 OnCheckpointRollingPolicy 滚动 Part 文件。原因是:如果 Part 文件 “穿越” 了 Checkpoint 的时间间隔,
然后,从失败中恢复过来时,FileSink 可能会使用文件系统的 truncate() 方法丢弃处于 In-progress 状态文件中的未提交数据。
这个方法在 Hadoop 2.7 版本之前是不支持的,Flink 将抛出异常。
注意事项 2:鉴于 Flink 的 Sink 和 UDF 通常不会区分正常作业终止(例如 有限输入流)和 由于故障而终止, 在 Job 正常终止时,最后一个 In-progress 状态文件不会转换为 “Finished” 状态。
注意事项 3:Flink 和 FileSink 永远不会覆盖已提交数据。
鉴于此,假定一个 In-progress 状态文件被后续成功的 Checkpoint 提交了,当尝试从这个旧的 Checkpoint / Savepoint 进行恢复时,FileSink 将拒绝继续执行并将抛出异常,因为程序无法找到 In-progress 状态的文件。
注意事项 4:目前,FileSink 仅支持以下 5 种文件系统:HDFS、 S3、OSS、ABFS 和 Local。如果在运行时使用了不支持的文件系统,Flink 将抛出异常。
BATCH 注意事项 #
注意事项 1:虽然 Writer 是以用户指定的 parallelism 执行的,然而 Committer 是以 parallelism = 1 执行的。
注意事项 2:Pending 状态文件被提交并且所有输入数据被处理完后,才转换为 Finished 状态。
注意事项 3:当系统处于高可用状态下,并且正当 Committers 进行提交时如果 JobManager 发生了故障,那么可能会有副本。这种情况将会在 Flink 的未来版本中进行修复。(可以参考 FLIP-147 ) 。
S3 注意事项 #
注意事项 1:对于 S3,FileSink 仅支持基于 Hadoop-based 文件系统的实现,而不支持基于 Presto 的实现。
如果 Job 中使用 FileSink 写入 S3,但是希望使用基于 Presto 的 Sink 做 Checkpoint,建议明确使用 “s3a://” (对于 Hadoop)作为 Sink 目标路径格式并且使用 “s3p://” 作为 Checkpoint 的目标路径格式(对于 Presto)。
对于 Sink 和 Checkpoint 同时使用 “s3://” 可能导致不可控的行为,由于两者的实现 “监听” 同一格式路径。
注意事项 2:在保证高效的同时还要保证 exactly-once 语义,FileSink 使用了 S3 的 Multi-part Upload 功能(MPU 功能开箱即用)。
此功能允许以独立的块上传文件(因此称为 “multi-part”),当 MPU 的所有块都上传成功时,这些块就可以合并生成原始文件。
对于非活动的 MPU,S3 支持桶生命周期规则,用户可以使用该规则终止在启动后指定天数内未完成的多块上传操作。
这意味着,如果设置了这个规则,并在某些文件未完全上传的情况下执行 Savepoint,则其关联的 MPU 可能会在 Job 重启前超时。
这将导致 Job 无法从该 Savepoint 恢复,因为 Pending 状态的 Part 文件已不存在,那么 Flink Job 将失败并抛出异常,因为程序试图获取那些不存在的文件导致了失败。