流式概念 #
Flink 的 Table API 和 SQL 是流批统一的 API。 这意味着 Table API & SQL 在无论有限的批式输入还是无限的流式输入下,都具有相同的语义。 因为传统的关系代数以及 SQL 最开始都是为了批式处理而设计的, 关系型查询在流式场景下不如在批式场景下容易懂。
下面这些页面包含了概念、实际的限制,以及流式数据处理中的一些特定的配置。
状态管理 #
流模式下运行的表程序利用了 Flink 作为有状态流处理器的所有能力。
事实上,一个表程序(Table program)可以配置一个 state backend 和多个不同的 checkpoint 选项 以处理对不同状态大小和容错需求。这可以对正在运行的 Table API & SQL 管道(pipeline)生成 savepoint,并在这之后用其恢复应用程序的状态。
状态使用 #
由于 Table API & SQL 程序是声明式的,管道内的状态会在哪以及如何被使用并不明确。 Planner 会确认是否需要状态来得到正确的计算结果, 管道会被现有优化规则集优化成尽可能少地使用状态。
从概念上讲, 源表从来不会在状态中被完全保存。 实现者处理的是逻辑表(即动态表)。 它们的状态取决于用到的操作。
状态算子 #
包含诸如连接、聚合或去重 等操作的语句需要在 Flink 抽象的容错存储内保存中间结果。
例如对两个表进行 join 操作的普通 SQL 需要算子保存两个表的全部输入。基于正确的 SQL 语义,运行时假设两表会在任意时间点进行匹配。 Flink 提供了 优化窗口和时段 Join 聚合 以利用 watermarks 概念来让保持较小的状态规模。
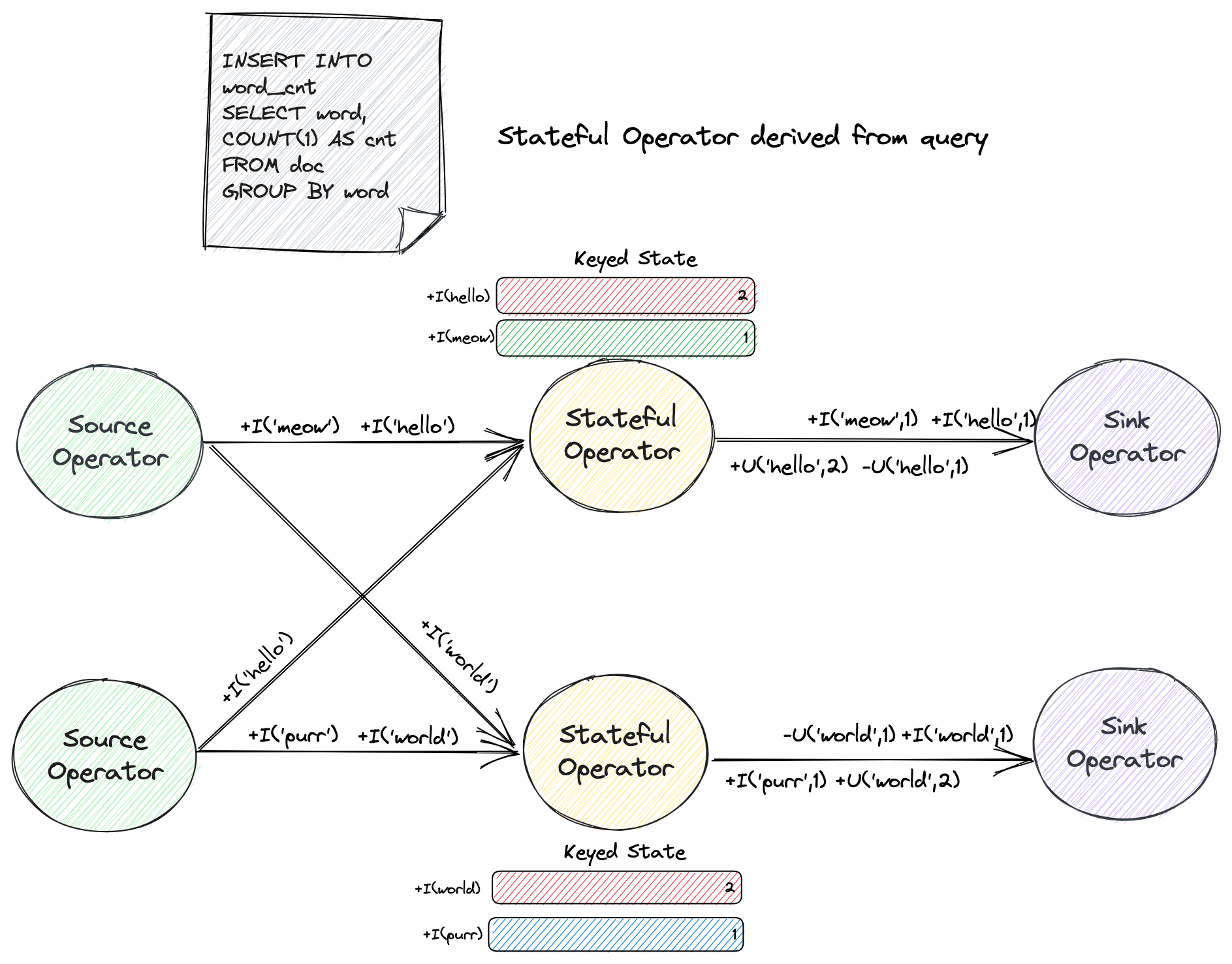
另一个计算词频的例子如下
CREATE TABLE doc (
word STRING
) WITH (
'connector' = '...'
);
CREATE TABLE word_cnt (
word STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
) WITH (
'connector' = '...'
);
INSERT INTO word_cnt
SELECT word, COUNT(1) AS cnt
FROM doc
GROUP BY word;
word 是用于分组的键,连续查询(Continuous Query)维护了每个观察到的 word 次数。
输入 word 的值随时间变化。由于这个查询一直持续,Flink 会为每个 word 维护一个中间状态来保存当前词频,因此总状态量会随着 word 的发现不断地增长。
形如 SELECT ... FROM ... WHERE 这种只包含字段映射或过滤器的查询语句通常是无状态的管道。
然而在某些情况下,根据输入数据的特征(比如输入表是不带 UPDATE_BEFORE 的更新流,参考
表到流的转换)或配置(参考 table-exec-source-cdc-events-duplicate),状态算子可能会被隐式地推导出来。
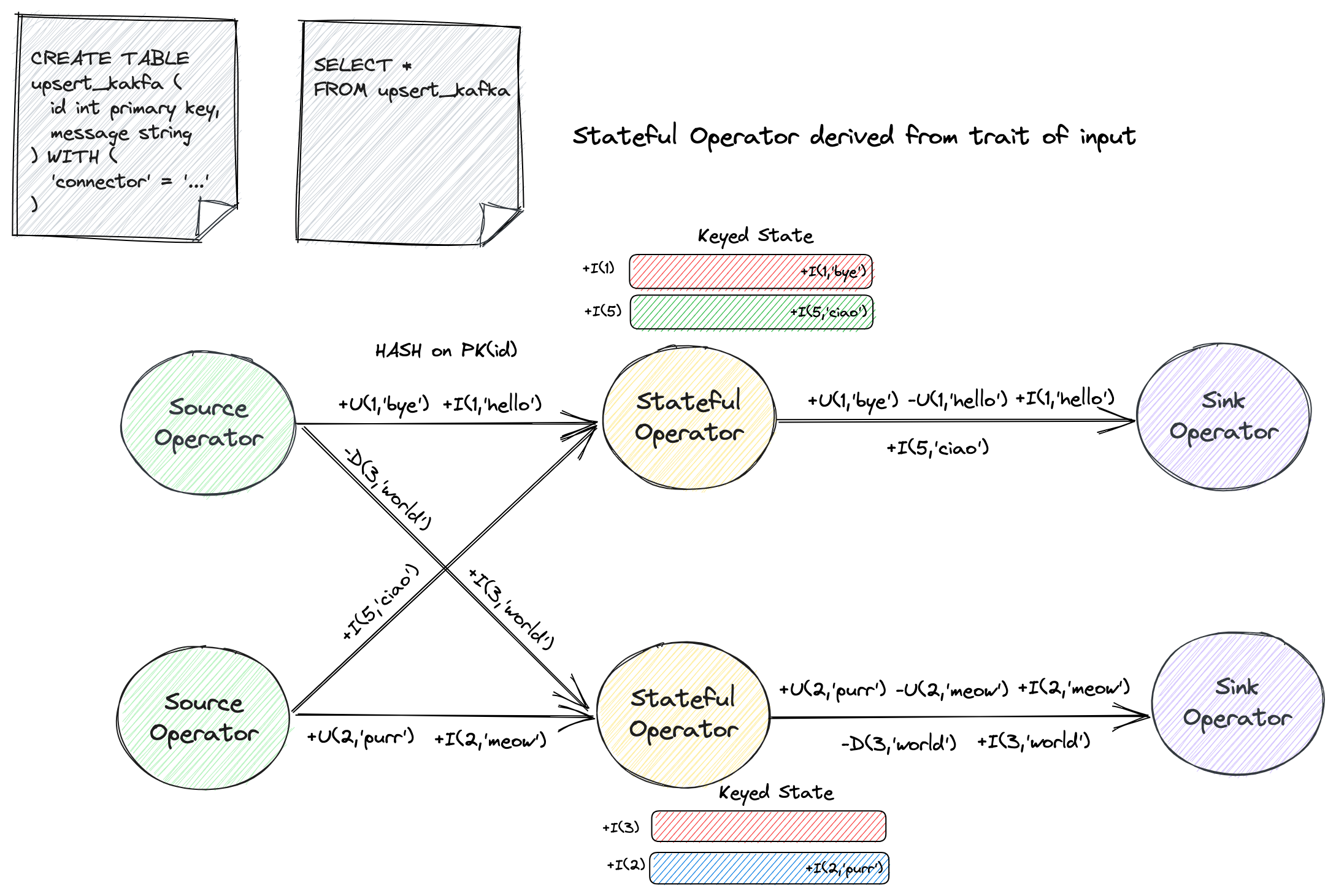
下面的例子展示了使用 SELECT ... FROM 语句查询 upsert kafka 源表。
CREATE TABLE upsert_kakfa (
id INT PRIMARY KEY NOT ENFORCED,
message STRING
) WITH (
'connector' = 'upsert-kafka',
...
);
SELECT * FROM upsert_kakfa;
源表的消息类型只包含 INSERT,UPDATE_AFTER 和 DELETE,然而下游要求完整的 changelog(包含 UPDATE_BEFORE)。
所以虽然查询本身没有包含状态计算,但是优化器依然隐式地推导出了一个 ChangelogNormalize 状态算子来生成完整的 changelog。
请参考独立的算子文档来获取更多关于状态需求量和限制潜在增长状态大小的信息。
空闲状态维持时间 #
空闲状态维持时间参数 table.exec.state.ttl
定义了状态的键在被更新后要保持多长时间才被移除。
在之前的查询例子中,word 的数目会在配置的时间内未更新时立刻被移除。
通过移除状态的键,连续查询会完全忘记它曾经见过这个键。如果一个状态带有曾被移除状态的键被处理了,这条记录将被认为是对应键的第一条记录。上述例子中意味着 cnt 会再次从 0 开始计数。
配置算子粒度的状态 TTL #
这是一个需要小心使用的高级特性。该特性仅适用于作业中使用了多个状态,并且每个状态需要使用不同的 TTL。
无状态的作业不需要参考下面的操作步骤。
如果作业中仅使用到一个状态,仅需设置作业级别的 TTL 参数 table.exec.state.ttl。
从 Flink v1.18 开始,Table API & SQL 支持配置细粒度的状态 TTL 来优化状态使用,可配置粒度为每个状态算子的入边数。具体而言,OneInputStreamOperator 可以配置一个状态的 TTL,而 TwoInputStreamOperator(例如双流 join)则可以分别为左状态和右状态配置 TTL。更一般地,对于具有 K 个输入的 MultipleInputStreamOperator,可以配置 K 个状态 TTL。
一些典型的使用场景如下
- 为 双流 Join 的左右流配置不同 TTL。
双流 Join 会生成拥有两条输入边的
TwoInputStreamOperator的状态算子,它用到了两个状态,分别来保存来自左流和右流的更新。 - 在同一个作业中为不同的状态计算设置不同 TTL。
举例来说,假设一个 ETL 作业使用
ROW_NUMBER进行去重操作后, 紧接着使用GROUP BY语句进行聚合操作。 该作业会分别生成两个拥有单条输入边的OneInputStreamOperator状态算子。您可以为去重算子和聚合算子的状态分别设置不同的 TTL。
由于基于窗口的操作(例如窗口连接、窗口聚合、窗口 Top-N 等)和 Interval Join 不依赖于 table.exec.state.ttl 来控制状态保留,因此它们的状态无法在算子级别进行配置。
生成 Compiled Plan
配置过程首先会使用 COMPILE PLAN 语句生成一个 JSON 文件,它表示了序列化后的执行计划。
COMPILE PLAN不支持查询语句SELECT... FROM...。
- 执行
COMPILE PLAN语句
TableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
tableEnv.executeSql(
"CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)");
tableEnv.executeSql(
"CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)");
tableEnv.executeSql(
"CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)");
// CompilePlan#writeToFile only supports a local file path, if you need to write to remote filesystem,
// please use tableEnv.executeSql("COMPILE PLAN 'hdfs://path/to/plan.json' FOR ...")
CompiledPlan compiledPlan =
tableEnv.compilePlanSql(
"INSERT INTO enriched_orders \n"
+ "SELECT a.order_id, a.order_line_id, b.order_status, ... \n"
+ "FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id");
compiledPlan.writeToFile("/path/to/plan.json");
val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode())
tableEnv.executeSql(
"CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)")
tableEnv.executeSql(
"CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)")
tableEnv.executeSql(
"CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)")
val compiledPlan =
tableEnv.compilePlanSql(
"""
|INSERT INTO enriched_orders
|SELECT a.order_id, a.order_line_id, b.order_status, ...
|FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id
|""".stripMargin)
// CompilePlan#writeToFile only supports a local file path, if you need to write to remote filesystem,
// please use tableEnv.executeSql("COMPILE PLAN 'hdfs://path/to/plan.json' FOR ...")
compiledPlan.writeToFile("/path/to/plan.json")
Flink SQL> CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...);
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...);
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...);
[INFO] Execute statement succeed.
Flink SQL> COMPILE PLAN 'file:///path/to/plan.json' FOR INSERT INTO enriched_orders
> SELECT a.order_id, a.order_line_id, b.order_status, ...
> FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id;
[INFO] Execute statement succeed.
-
SQL 语法
COMPILE PLAN [IF NOT EXISTS] <plan_file_path> FOR <insert_statement>|<statement_set>; statement_set: EXECUTE STATEMENT SET BEGIN insert_statement; ... insert_statement; END; insert_statement: <insert_from_select>|<insert_from_values>该语句会在指定位置
/path/to/plan.json生成一个 JSON 文件。
COMPILE PLAN语句支持写入hdfs://或s3://等 Flink 支持的文件系统。 请确保已为目标写入路径设置了写入权限。
修改 Compiled Plan
每个状态算子会显式地生成一个名为 “state” 的 JSON 数组,具有如下结构。 理论上一个拥有 k 路输入的状态算子拥有 k 个状态。
"state": [
{
"index": 0,
"ttl": "0 ms",
"name": "${1st input state name}"
},
{
"index": 1,
"ttl": "0 ms",
"name": "${2nd input state name}"
},
...
]
找到您需要修改的状态算子,将 TTL 的值设置为一个正整数,注意需要带上时间单位毫秒。举例来说,如果想将当前状态算子的 TTL 设置为 1 小时,您可以按照如下格式修改 JSON:
{
"index": 0,
"ttl": "3600000 ms",
"name": "${1st input state name}"
}
保存好文件,然后使用 EXECUTE PLAN 语句来提交作业。
理论上,下游状态算子的 TTL 不应小于上游状态算子的 TTL。
执行 Compiled Plan
EXECUTE PLAN 语句将会反序列化上述 JSON 文件,进一步生成 JobGraph 并提交作业。
通过 EXECUTE PLAN 语句提交的作业,其状态算子的 TTL 的值将会从文件中读取,配置项 table.exec.state.ttl 的值将会被忽略。
-
执行
EXECUTE PLAN语句TableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode()); tableEnv.executeSql( "CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)"); tableEnv.executeSql( "CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)"); tableEnv.executeSql( "CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)"); // PlanReference#fromFile only supports a local file path, if you need to read from remote filesystem, // please use tableEnv.executeSql("EXECUTE PLAN 'hdfs://path/to/plan.json'").await(); tableEnv.loadPlan(PlanReference.fromFile("/path/to/plan.json")).execute().await();val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode()) tableEnv.executeSql( "CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)") tableEnv.executeSql( "CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)") tableEnv.executeSql( "CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)") // PlanReference#fromFile only supports a local file path, if you need to read from remote filesystem, // please use tableEnv.executeSql("EXECUTE PLAN 'hdfs://path/to/plan.json'").await() tableEnv.loadPlan(PlanReference.fromFile("/path/to/plan.json")).execute().await()Flink SQL> CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...); [INFO] Execute statement succeed. Flink SQL> CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...); [INFO] Execute statement succeed. Flink SQL> CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...); [INFO] Execute statement succeed. Flink SQL> EXECUTE PLAN 'file:///path/to/plan.json'; [INFO] Submitting SQL update statement to the cluster... [INFO] SQL update statement has been successfully submitted to the cluster: Job ID: 79fbe3fa497e4689165dd81b1d225ea8 -
SQL 语法
EXECUTE PLAN [IF EXISTS] <plan_file_path>;该语句反序列化指定的 JSON 文件,并提交作业。
完整示例
下面的例子展示了一个通过双流 Join 计算订单明细的作业,并且如何为左右流设置不同的 TTL。
-
生成 compiled plan
-- left source table CREATE TABLE Orders ( `order_id` INT, `line_order_id` INT ) WITH ( 'connector'='...' ); -- right source table CREATE TABLE LineOrders ( `line_order_id` INT, `ship_mode` STRING ) WITH ( 'connector'='...' ); -- sink table CREATE TABLE OrdersShipInfo ( `order_id` INT, `line_order_id` INT, `ship_mode` STRING ) WITH ( 'connector' = '...' ); COMPILE PLAN '/path/to/plan.json' FOR INSERT INTO OrdersShipInfo SELECT a.order_id, a.line_order_id, b.ship_mode FROM Orders a JOIN LineOrders b ON a.line_order_id = b.line_order_id;生成的 JSON 文件内容如下:
{ "flinkVersion" : "1.18", "nodes" : [ { "id" : 1, "type" : "stream-exec-table-source-scan_1", "scanTableSource" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`Orders`", "resolvedTable" : { ... } } }, "outputType" : "ROW<`order_id` INT, `line_order_id` INT>", "description" : "TableSourceScan(table=[[default_catalog, default_database, Orders]], fields=[order_id, line_order_id])", "inputProperties" : [ ] }, { "id" : 2, "type" : "stream-exec-exchange_1", "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT>", "description" : "Exchange(distribution=[hash[line_order_id]])" }, { "id" : 3, "type" : "stream-exec-table-source-scan_1", "scanTableSource" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`LineOrders`", "resolvedTable" : {...} } }, "outputType" : "ROW<`line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "TableSourceScan(table=[[default_catalog, default_database, LineOrders]], fields=[line_order_id, ship_mode])", "inputProperties" : [ ] }, { "id" : 4, "type" : "stream-exec-exchange_1", "inputProperties" : [ ... ], "outputType" : "ROW<`line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Exchange(distribution=[hash[line_order_id]])" }, { "id" : 5, "type" : "stream-exec-join_1", "joinSpec" : { ... }, "state" : [ { "index" : 0, "ttl" : "0 ms", "name" : "leftState" }, { "index" : 1, "ttl" : "0 ms", "name" : "rightState" } ], "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `line_order_id0` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Join(joinType=[InnerJoin], where=[(line_order_id = line_order_id0)], select=[order_id, line_order_id, line_order_id0, ship_mode], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey])" }, { "id" : 6, "type" : "stream-exec-calc_1", "projection" : [ ... ], "condition" : null, "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Calc(select=[order_id, line_order_id, ship_mode])" }, { "id" : 7, "type" : "stream-exec-sink_1", "configuration" : { ... }, "dynamicTableSink" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`OrdersShipInfo`", "resolvedTable" : { ... } } }, "inputChangelogMode" : [ "INSERT" ], "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Sink(table=[default_catalog.default_database.OrdersShipInfo], fields=[order_id, line_order_id, ship_mode])" } ], "edges" : [ ... ] } -
修改和执行 compiled plan
如下 JSON 格式代表了 Join 算子的状态信息:
"state": [ { "index": 0, "ttl": "0 ms", "name": "leftState" }, { "index": 1, "ttl": "0 ms", "name": "rightState" } ]其中
"index"代表了当前状态属于算子的第几路输入,从 0 开始计数。 当前左右流的 TTL 值都是"0 ms",表示此时 TTL 并未开启。 现在将左流的 TTL 设置为"3000 ms",右流设置为"9000 ms"。修改后的 JSON 如下所示。"state": [ { "index": 0, "ttl": "3000 ms", "name": "leftState" }, { "index": 1, "ttl": "9000 ms", "name": "rightState" } ]保存修改,紧接着使用
EXECUTE PLAN语句提交作业,此时提交的作业中,Join 的左右流就使用了上述配置的不同 TTL。EXECUTE PLAN '/path/to/plan.json'
状态化更新与演化 #
表程序在流模式下执行将被视为标准查询,这意味着它们被定义一次后将被一直视为静态的端到端 (end-to-end) 管道
对于这种状态化的管道,对查询和Flink的Planner的改动都有可能导致完全不同的执行计划。这让表程序的状态化的升级和演化在目前而言 仍具有挑战,社区正致力于改进这一缺点。
例如为了添加过滤谓词,优化器可能决定重排 join 或改变内部算子的 schema。 这会阻碍从 savepoint 的恢复,因为其被改变的拓扑和 算子状态的列布局差异。
查询实现者需要确保改变在优化计划前后是兼容的,在 SQL 中使用 EXPLAIN 或在 Table API 中使用 table.explain()
可获取详情。
由于新的优化器规则正不断地被添加,算子变得更加高效和专用,升级到更新的Flink版本可能造成不兼容的计划。
当前框架无法保证状态可以从 savepoint 映射到新的算子拓扑上。
换言之: Savepoint 只在查询语句和版本保持恒定的情况下被支持。
由于社区拒绝在版本补丁(如 1.13.1 至 1.13.2)上对优化计划和算子拓扑进行修改的贡献,对一个 Table API & SQL 管道
升级到新的 bug fix 发行版应当是安全的。然而主次(major-minor)版本的更新(如 1.12 至 1.13)不被支持。
由于这两个缺点(即修改查询语句和修改Flink版本),我们推荐实现调查升级后的表程序是否可以在切换到实时数据前,被历史数据"暖机" (即被初始化)。Flink社区正致力于 混合源 来让切换变得尽可能方便。