窗口表值函数(Windowing TVFs) #
Batch Streaming
窗口是处理无限流的核心。窗口把流分割为有限大小的 “桶”,这样就可以在其之上进行计算。本文档聚焦于窗口在 Flink SQL 中是如何工作的,编程人员如何最大化地利用好它。
Apache Flink 提供了如下 窗口表值函数(table-valued function, 缩写TVF)把表的数据划分到窗口中:
注意:逻辑上,每个元素可以应用于一个或多个窗口,这取决于所使用的 窗口表值函数。例如:滑动窗口可以把单个元素分配给多个窗口。
窗口表值函数 是 Flink 定义的多态表函数(Polymorphic Table Function,缩写PTF),PTF 是 SQL 2016 标准中的一种特殊的表函数,它可以把表作为一个参数。PTF 在对表的重塑上很强大。因为它们的调用出现在 SELECT 的 FROM 从句里。
窗口表值函数 是 分组窗口函数 (已经过时)的替代方案。窗口表值函数 更符合 SQL 标准,在支持基于窗口的复杂计算上也更强大。例如:窗口 TopN、窗口 Join。而分组窗口函数只支持窗口聚合。
更多基于 窗口表值函数 的进阶用法:
窗口函数 #
Apache Flink 提供3个内置的窗口表值函数:TUMBLE,HOP 和 CUMULATE。窗口表值函数 的返回值包括原生列和附加的三个指定窗口的列,分别是:“window_start”,“window_end”,“window_time”。
在流计算模式,window_time 是 TIMESTAMP 或者 TIMESTAMP_LTZ 类型(具体哪种类型取决于输入的时间字段类型)的字段。
window_time 字段用于后续基于时间的操作,例如:其他的窗口表值函数,或者interval joins,over aggregations。
它的值总是等于 window_end - 1ms。
滚动窗口(TUMBLE) #
TUMBLE 函数指定每个元素到一个指定大小的窗口中。滚动窗口的大小固定且不重复。例如:假设指定了一个 5 分钟的滚动窗口。Flink 将每 5 分钟生成一个新的窗口,如下图所示:

TUMBLE 函数通过时间属性字段为每行数据分配一个窗口。
在流计算模式,时间属性字段必须被指定为 事件或处理时间属性。
在批计算模式,窗口表函数的时间属性字段必须是 TIMESTAMP 或 TIMESTAMP_LTZ 的类型。
TUMBLE 的返回值包括原始表的所有列和附加的三个用于指定窗口的列,分别是:“window_start”,“window_end”,“window_time”。函数运行后,原有的时间属性 “timecol” 将转换为一个常规的 timestamp 列。
TUMBLE 函数有三个必传参数,一个可选参数:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data:拥有时间属性列的表。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。size:窗口的大小(时长)。offset:窗口的偏移量 [非必填]。
下面是 Bid 表的调用示例:
-- tables must have time attribute, e.g. `bidtime` in this table
Flink SQL> desc Bid;
+-------------+------------------------+------+-----+--------+---------------------------------+
| name | type | null | key | extras | watermark |
+-------------+------------------------+------+-----+--------+---------------------------------+
| bidtime | TIMESTAMP(3) *ROWTIME* | true | | | `bidtime` - INTERVAL '1' SECOND |
| price | DECIMAL(10, 2) | true | | | |
| item | STRING | true | | | |
+-------------+------------------------+------+-----+--------+---------------------------------+
Flink SQL> SELECT * FROM Bid;
+------------------+-------+------+
| bidtime | price | item |
+------------------+-------+------+
| 2020-04-15 08:05 | 4.00 | C |
| 2020-04-15 08:07 | 2.00 | A |
| 2020-04-15 08:09 | 5.00 | D |
| 2020-04-15 08:11 | 3.00 | B |
| 2020-04-15 08:13 | 1.00 | E |
| 2020-04-15 08:17 | 6.00 | F |
+------------------+-------+------+
Flink SQL> SELECT * FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(
TUMBLE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the tumbling windowed table
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
注意:为了更好地理解窗口行为,这里把 timestamp 值得后面的 0 去掉了。例如:在 Flink SQL Client 中,如果类型是 TIMESTAMP(3),2020-04-15 08:05 应该显示成 2020-04-15 08:05:00.000
滑动窗口(HOP) #
滑动窗口函数指定元素到一个定长的窗口中。和滚动窗口很像,有窗口大小参数,另外增加了一个窗口滑动步长参数。如果滑动步长小于窗口大小,就能产生数据重叠的效果。在这个例子里,数据可以被分配在多个窗口。
例如:可以定义一个每5分钟滑动一次。大小为10分钟的窗口。每5分钟获得最近10分钟到达的数据的窗口,如下图所示:

HOP 函数通过时间属性字段为每一行数据分配了一个窗口。
在流计算模式,这个时间属性字段必须被指定为 事件或处理时间属性。
在批计算模式,这个窗口表函数的时间属性字段必须是 TIMESTAMP 或 TIMESTAMP_LTZ 的类型。
HOP 的返回值包括原始表的所有列和附加的三个用于指定窗口的列,分别是:“window_start”,“window_end”,“window_time”。函数运行后,原有的时间属性 “timecol” 将转换为一个常规的 timestamp 列。
HOP 有四个必填参数和一个可选参数:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:拥有时间属性列的表。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。slide:窗口的滑动步长。size:窗口的大小(时长)。offset:窗口的偏移量 [非必填]。
下面是 Bid 表的调用示例:
> SELECT * FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
HOP(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SLIDE => INTERVAL '5' MINUTES,
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:05 | 2020-04-15 08:15 | 2020-04-15 08:14:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:15 | 2020-04-15 08:25 | 2020-04-15 08:24:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the hopping windowed table
> SELECT window_start, window_end, SUM(price)
FROM TABLE(
HOP(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '5' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:05 | 2020-04-15 08:15 | 15.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
| 2020-04-15 08:15 | 2020-04-15 08:25 | 6.00 |
+------------------+------------------+-------+
累积窗口(CUMULATE) #
累积窗口在某些场景中非常有用,比如说提前触发的滚动窗口。例如:每日仪表盘从 00:00 开始每分钟绘制累积 UV,10:00 时 UV 就是从 00:00 到 10:00 的UV 总数。累积窗口可以简单且有效地实现它。
CUMULATE 函数指定元素到多个窗口,从初始的窗口开始,直到达到最大的窗口大小的窗口,所有的窗口都包含其区间内的元素,另外,窗口的开始时间是固定的。
你可以将 CUMULATE 函数视为首先应用具有最大窗口大小的 TUMBLE 窗口,然后将每个滚动窗口拆分为具有相同窗口开始但窗口结束步长不同的几个窗口。 所以累积窗口会产生重叠并且没有固定大小。
例如:1小时步长,24小时大小的累计窗口,每天可以获得如下这些窗口:[00:00, 01:00),[00:00, 02:00),[00:00, 03:00), …, [00:00, 24:00)
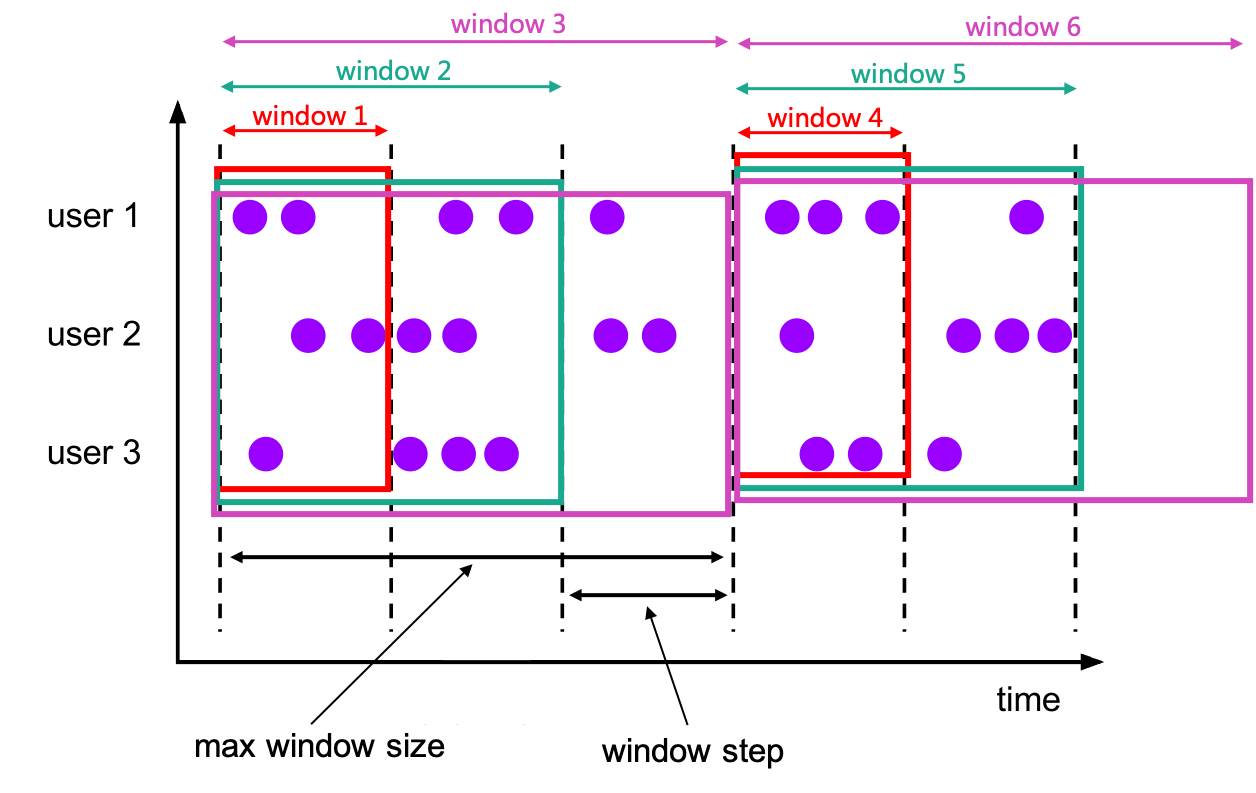
CUMULATE 函数通过时间属性字段为每一行数据分配了一个窗口。
在流计算模式,这个时间属性字段必须被指定为 事件或处理时间属性。
在批计算模式,这个窗口表函数的时间属性字段必须是 TIMESTAMP 或 TIMESTAMP_LTZ 的类型。
CUMULATE 的返回值包括原始表的所有列和附加的三个用于指定窗口的列,分别是:“window_start”,“window_end”,“window_time”。函数运行后,原有的时间属性 “timecol” 将转换为一个常规的 timestamp 列。
CUMULATE 有四个必填参数和一个可选参数:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data:拥有时间属性列的表。timecol:列描述符,决定数据的哪个时间属性列应该映射到窗口。step:指定连续的累积窗口之间增加的窗口大小。size:指定累积窗口的最大宽度的窗口时间。size必须是step的整数倍。offset:窗口的偏移量 [非必填]。
下面是 Bid 表的调用示例:
> SELECT * FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
> SELECT * FROM TABLE(
CUMULATE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
STEP => INTERVAL '2' MINUTES,
SIZE => INTERVAL '10' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:06 | 2020-04-15 08:05:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 |
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:08 | 2020-04-15 08:07:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:00 | 2020-04-15 08:10 | 2020-04-15 08:09:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:12 | 2020-04-15 08:11:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:14 | 2020-04-15 08:13:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:16 | 2020-04-15 08:15:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:18 | 2020-04-15 08:17:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:10 | 2020-04-15 08:20 | 2020-04-15 08:19:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the cumulating windowed table
> SELECT window_start, window_end, SUM(price)
FROM TABLE(
CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:00 | 2020-04-15 08:06 | 4.00 |
| 2020-04-15 08:00 | 2020-04-15 08:08 | 6.00 |
| 2020-04-15 08:00 | 2020-04-15 08:10 | 11.00 |
| 2020-04-15 08:10 | 2020-04-15 08:12 | 3.00 |
| 2020-04-15 08:10 | 2020-04-15 08:14 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:16 | 4.00 |
| 2020-04-15 08:10 | 2020-04-15 08:18 | 10.00 |
| 2020-04-15 08:10 | 2020-04-15 08:20 | 10.00 |
+------------------+------------------+-------+
窗口偏移 #
Offset 可选参数,可以用来改变窗口的分配。可以是正或者负的区间。默认情况下窗口的偏移是 0。不同的偏移值可以决定记录分配的窗口。
例如:在 10 分钟大小的滚动窗口下,时间戳为 2021-06-30 00:00:04 的数据会被分配到那个窗口呢?
- 当
offset为-16 MINUTE,数据会分配到窗口 [2021-06-29 23:54:00,2021-06-30 00:04:00)。 - 当
offset为-6 MINUTE,数据会分配到窗口 [2021-06-29 23:54:00,2021-06-30 00:04:00)。 - 当
offset为-4 MINUTE,数据会分配到窗口 [2021-06-29 23:56:00,2021-06-30 00:06:00)。 - 当
offset为0,数据会分配到窗口 [2021-06-30 00:00:00,2021-06-30 00:10:00)。 - 当
offset为4 MINUTE,数据会分配到窗口 [2021-06-29 23:54:00,2021-06-30 00:04:00)。 - 当
offset为6 MINUTE,数据会分配到窗口 [2021-06-29 23:56:00,2021-06-30 00:06:00)。 - 当
offset为16 MINUTE,数据会分配到窗口 [2021-06-29 23:56:00,2021-06-30 00:06:00)。 我们可以发现,有些不同的窗口偏移参数对窗口分配的影响是一样的。在上面的例子中,-16 MINUTE,-6 MINUTE和4 MINUTE对 10 分钟大小的滚动窗口效果相同。
*注意:窗口偏移只影响窗口的分配,并不会影响 Watermark *
下面的 SQL 展示了偏移在滚动窗口如何使用。
-- NOTE: Currently Flink doesn't support evaluating individual window table-valued function,
-- window table-valued function should be used with aggregate operation,
-- this example is just used for explaining the syntax and the data produced by table-valued function.
Flink SQL> SELECT * FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES));
-- or with the named params
-- note: the DATA param must be the first
Flink SQL> SELECT * FROM TABLE(
TUMBLE(
DATA => TABLE Bid,
TIMECOL => DESCRIPTOR(bidtime),
SIZE => INTERVAL '10' MINUTES,
OFFSET => INTERVAL '1' MINUTES));
+------------------+-------+------+------------------+------------------+-------------------------+
| bidtime | price | item | window_start | window_end | window_time |
+------------------+-------+------+------------------+------------------+-------------------------+
| 2020-04-15 08:05 | 4.00 | C | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:07 | 2.00 | A | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:09 | 5.00 | D | 2020-04-15 08:01 | 2020-04-15 08:11 | 2020-04-15 08:10:59.999 |
| 2020-04-15 08:11 | 3.00 | B | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
| 2020-04-15 08:13 | 1.00 | E | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
| 2020-04-15 08:17 | 6.00 | F | 2020-04-15 08:11 | 2020-04-15 08:21 | 2020-04-15 08:20:59.999 |
+------------------+-------+------+------------------+------------------+-------------------------+
-- apply aggregation on the tumbling windowed table
Flink SQL> SELECT window_start, window_end, SUM(price)
FROM TABLE(
TUMBLE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '10' MINUTES, INTERVAL '1' MINUTES))
GROUP BY window_start, window_end;
+------------------+------------------+-------+
| window_start | window_end | price |
+------------------+------------------+-------+
| 2020-04-15 08:01 | 2020-04-15 08:11 | 11.00 |
| 2020-04-15 08:11 | 2020-04-15 08:21 | 10.00 |
+------------------+------------------+-------+
注意:为了更好地理解窗口行为,这里把 timestamp 值得后面的 0 去掉了。例如:在 Flink SQL Client 中,如果类型是 TIMESTAMP(3),2020-04-15 08:05 应该显示成 2020-04-15 08:05:00.000