![]() v1.2
v1.2
JobManager High Availability (HA)
The JobManager coordinates every Flink deployment. It is responsible for both scheduling and resource management.
By default, there is a single JobManager instance per Flink cluster. This creates a single point of failure (SPOF): if the JobManager crashes, no new programs can be submitted and running programs fail.
With JobManager High Availability, you can recover from JobManager failures and thereby eliminate the SPOF. You can configure high availability for both standalone and YARN clusters.
- Standalone Cluster High Availability
- YARN Cluster High Availability
- Configuring for Zookeeper Security
- Bootstrap ZooKeeper
Standalone Cluster High Availability
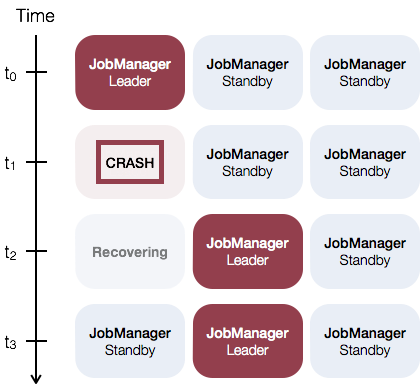
The general idea of JobManager high availability for standalone clusters is that there is a single leading JobManager at any time and multiple standby JobManagers to take over leadership in case the leader fails. This guarantees that there is no single point of failure and programs can make progress as soon as a standby JobManager has taken leadership. There is no explicit distinction between standby and master JobManager instances. Each JobManager can take the role of master or standby.
As an example, consider the following setup with three JobManager instances:
Configuration
To enable JobManager High Availability you have to set the high-availability mode to zookeeper, configure a ZooKeeper quorum and set up a masters file with all JobManagers hosts and their web UI ports.
Flink leverages ZooKeeper for distributed coordination between all running JobManager instances. ZooKeeper is a separate service from Flink, which provides highly reliable distributed coordination via leader election and light-weight consistent state storage. Check out ZooKeeper’s Getting Started Guide for more information about ZooKeeper. Flink includes scripts to bootstrap a simple ZooKeeper installation.
Masters File (masters)
In order to start an HA-cluster configure the masters file in conf/masters:
-
masters file: The masters file contains all hosts, on which JobManagers are started, and the ports to which the web user interface binds.
jobManagerAddress1:webUIPort1 [...] jobManagerAddressX:webUIPortX
By default, the job manager will pick a random port for inter process communication. You can change this via the high-availability.jobmanager.port key. This key accepts single ports (e.g. 50010), ranges (50000-50025), or a combination of both (50010,50011,50020-50025,50050-50075).
Config File (flink-conf.yaml)
In order to start an HA-cluster add the following configuration keys to conf/flink-conf.yaml:
-
high-availability mode (required): The high-availability mode has to be set in
conf/flink-conf.yamlto zookeeper in order to enable high availability mode.high-availability: zookeeper
-
ZooKeeper quorum (required): A ZooKeeper quorum is a replicated group of ZooKeeper servers, which provide the distributed coordination service.
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181
Each addressX:port refers to a ZooKeeper server, which is reachable by Flink at the given address and port.
-
ZooKeeper root (recommended): The root ZooKeeper node, under which all cluster namespace nodes are placed.
high-availability.zookeeper.path.root: /flink
-
ZooKeeper namespace (recommended): The namespace ZooKeeper node, under which all required coordination data for a cluster is placed.
high-availability.zookeeper.path.namespace: /default_ns # important: customize per cluster
Important: if you are running multiple Flink HA clusters, you have to manually configure separate namespaces for each cluster. By default, the Yarn cluster and the Yarn session automatically generate namespaces based on Yarn application id. A manual configuration overrides this behaviour in Yarn. Specifying a namespace with the -z CLI option, in turn, overrides manual configuration.
-
Storage directory (required): JobManager metadata is persisted in the file system storageDir and only a pointer to this state is stored in ZooKeeper.
high-availability.zookeeper.storageDir: hdfs:///flink/recovery
The
storageDirstores all metadata needed to recover a JobManager failure.
After configuring the masters and the ZooKeeper quorum, you can use the provided cluster startup scripts as usual. They will start an HA-cluster. Keep in mind that the ZooKeeper quorum has to be running when you call the scripts and make sure to configure a separate ZooKeeper root path for each HA cluster you are starting.
Example: Standalone Cluster with 2 JobManagers
-
Configure high availability mode and ZooKeeper quorum in
conf/flink-conf.yaml:high-availability: zookeeper high-availability.zookeeper.quorum: localhost:2181 high-availability.zookeeper.path.root: /flink high-availability.zookeeper.path.namespace: /cluster_one # important: customize per cluster high-availability.zookeeper.storageDir: hdfs:///flink/recovery
-
Configure masters in
conf/masters:localhost:8081 localhost:8082
-
Configure ZooKeeper server in
conf/zoo.cfg(currently it’s only possible to run a single ZooKeeper server per machine):server.0=localhost:2888:3888
-
Start ZooKeeper quorum:
$ bin/start-zookeeper-quorum.sh Starting zookeeper daemon on host localhost.
-
Start an HA-cluster:
$ bin/start-cluster.sh Starting HA cluster with 2 masters and 1 peers in ZooKeeper quorum. Starting jobmanager daemon on host localhost. Starting jobmanager daemon on host localhost. Starting taskmanager daemon on host localhost.
-
Stop ZooKeeper quorum and cluster:
$ bin/stop-cluster.sh Stopping taskmanager daemon (pid: 7647) on localhost. Stopping jobmanager daemon (pid: 7495) on host localhost. Stopping jobmanager daemon (pid: 7349) on host localhost. $ bin/stop-zookeeper-quorum.sh Stopping zookeeper daemon (pid: 7101) on host localhost.
YARN Cluster High Availability
When running a highly available YARN cluster, we don’t run multiple JobManager (ApplicationMaster) instances, but only one, which is restarted by YARN on failures. The exact behaviour depends on on the specific YARN version you are using.
Configuration
Maximum Application Master Attempts (yarn-site.xml)
You have to configure the maximum number of attempts for the application masters for your YARN setup in yarn-site.xml:
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>The default for current YARN versions is 2 (meaning a single JobManager failure is tolerated).
Application Attempts (flink-conf.yaml)
In addition to the HA configuration (see above), you have to configure the maximum attempts in conf/flink-conf.yaml:
yarn.application-attempts: 10
This means that the application can be restarted 10 times before YARN fails the application. It’s important to note that yarn.resourcemanager.am.max-attempts is an upper bound for the application restarts. Therfore, the number of application attempts set within Flink cannot exceed the YARN cluster setting with which YARN was started.
Container Shutdown Behaviour
- YARN 2.3.0 < version < 2.4.0. All containers are restarted if the application master fails.
- YARN 2.4.0 < version < 2.6.0. TaskManager containers are kept alive across application master failures. This has the advantage that the startup time is faster and that the user does not have to wait for obtaining the container resources again.
- YARN 2.6.0 <= version: Sets the attempt failure validity interval to the Flinks’ Akka timeout value. The attempt failure validity interval says that an application is only killed after the system has seen the maximum number of application attempts during one interval. This avoids that a long lasting job will deplete it’s application attempts.
Note: Hadoop YARN 2.4.0 has a major bug (fixed in 2.5.0) preventing container restarts from a restarted Application Master/Job Manager container. See FLINK-4142 for details. We recommend using at least Hadoop 2.5.0 for high availability setups on YARN.
Example: Highly Available YARN Session
-
Configure HA mode and ZooKeeper quorum in
conf/flink-conf.yaml:high-availability: zookeeper high-availability.zookeeper.quorum: localhost:2181 high-availability.zookeeper.storageDir: hdfs:///flink/recovery high-availability.zookeeper.path.root: /flink high-availability.zookeeper.path.namespace: /cluster_one # important: customize per cluster yarn.application-attempts: 10
-
Configure ZooKeeper server in
conf/zoo.cfg(currently it’s only possible to run a single ZooKeeper server per machine):server.0=localhost:2888:3888
-
Start ZooKeeper quorum:
$ bin/start-zookeeper-quorum.sh Starting zookeeper daemon on host localhost.
-
Start an HA-cluster:
$ bin/yarn-session.sh -n 2
Configuring for Zookeeper Security
If ZooKeeper is running in secure mode with Kerberos, you can override the following configurations in flink-conf.yaml as necessary:
zookeeper.sasl.service-name: zookeeper # default is "zookeeper". If the ZooKeeper quorum is configured
# with a different service name then it can be supplied here.
zookeeper.sasl.login-context-name: Client # default is "Client". The value needs to match one of the values
# configured in "security.kerberos.login.contexts".
For more information on Flink configuration for Kerberos security, please see here. You can also find here further details on how Flink internally setups Kerberos-based security.
Bootstrap ZooKeeper
If you don’t have a running ZooKeeper installation, you can use the helper scripts, which ship with Flink.
There is a ZooKeeper configuration template in conf/zoo.cfg. You can configure the hosts to run ZooKeeper on with the server.X entries, where X is a unique ID of each server:
server.X=addressX:peerPort:leaderPort [...] server.Y=addressY:peerPort:leaderPort
The script bin/start-zookeeper-quorum.sh will start a ZooKeeper server on each of the configured hosts. The started processes start ZooKeeper servers via a Flink wrapper, which reads the configuration from conf/zoo.cfg and makes sure to set some required configuration values for convenience. In production setups, it is recommended to manage your own ZooKeeper installation.