![]() v1.5
v1.5
Standalone Cluster
This page provides instructions on how to run Flink in a fully distributed fashion on a static (but possibly heterogeneous) cluster.
Requirements
Software Requirements
Flink runs on all UNIX-like environments, e.g. Linux, Mac OS X, and Cygwin (for Windows) and expects the cluster to consist of one master node and one or more worker nodes. Before you start to setup the system, make sure you have the following software installed on each node:
- Java 1.8.x or higher,
- ssh (sshd must be running to use the Flink scripts that manage remote components)
If your cluster does not fulfill these software requirements you will need to install/upgrade it.
Having passwordless SSH and the same directory structure on all your cluster nodes will allow you to use our scripts to control everything.
JAVA_HOME Configuration
Flink requires the JAVA_HOME environment variable to be set on the master and all worker nodes and point to the directory of your Java installation.
You can set this variable in conf/flink-conf.yaml via the env.java.home key.
Flink Setup
Go to the downloads page and get the ready-to-run package. Make sure to pick the Flink package matching your Hadoop version. If you don’t plan to use Hadoop, pick any version.
After downloading the latest release, copy the archive to your master node and extract it:
tar xzf flink-*.tgz
cd flink-*Configuring Flink
After having extracted the system files, you need to configure Flink for the cluster by editing conf/flink-conf.yaml.
Set the jobmanager.rpc.address key to point to your master node. You should also define the maximum amount of main memory the JVM is allowed to allocate on each node by setting the jobmanager.heap.mb and taskmanager.heap.mb keys.
These values are given in MB. If some worker nodes have more main memory which you want to allocate to the Flink system you can overwrite the default value by setting the environment variable FLINK_TM_HEAP on those specific nodes.
Finally, you must provide a list of all nodes in your cluster which shall be used as worker nodes. Therefore, similar to the HDFS configuration, edit the file conf/slaves and enter the IP/host name of each worker node. Each worker node will later run a TaskManager.
The following example illustrates the setup with three nodes (with IP addresses from 10.0.0.1 to 10.0.0.3 and hostnames master, worker1, worker2) and shows the contents of the configuration files (which need to be accessible at the same path on all machines):
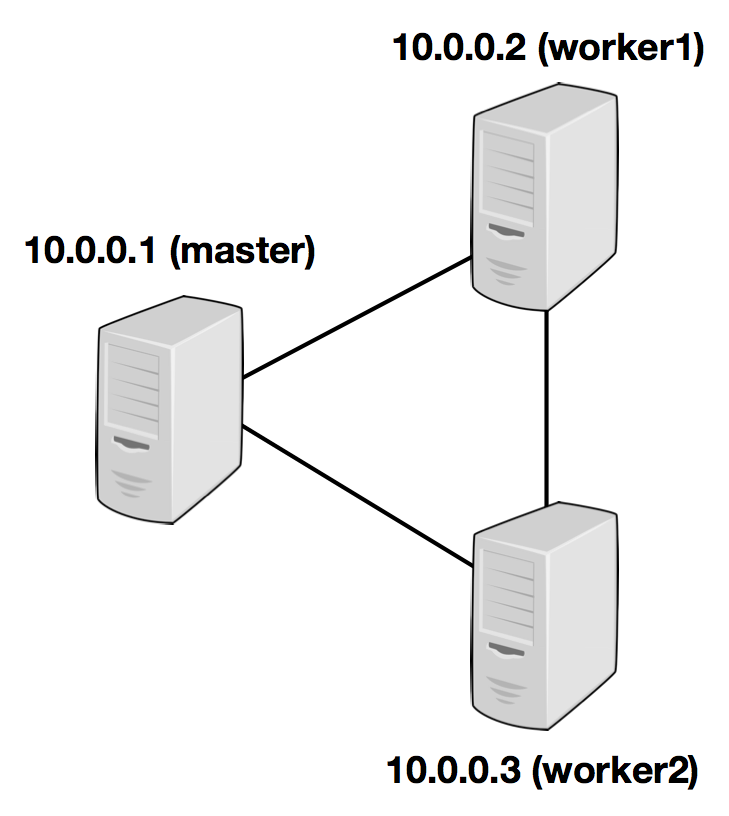
/path/to/flink/conf/
flink-conf.yaml
jobmanager.rpc.address: 10.0.0.1
/path/to/flink/
conf/slaves
10.0.0.2 10.0.0.3
The Flink directory must be available on every worker under the same path. You can use a shared NFS directory, or copy the entire Flink directory to every worker node.
Please see the configuration page for details and additional configuration options.
In particular,
- the amount of available memory per JobManager (
jobmanager.heap.mb), - the amount of available memory per TaskManager (
taskmanager.heap.mb), - the number of available CPUs per machine (
taskmanager.numberOfTaskSlots), - the total number of CPUs in the cluster (
parallelism.default) and - the temporary directories (
taskmanager.tmp.dirs)
are very important configuration values.
Starting Flink
The following script starts a JobManager on the local node and connects via SSH to all worker nodes listed in the slaves file to start the TaskManager on each node. Now your Flink system is up and running. The JobManager running on the local node will now accept jobs at the configured RPC port.
Assuming that you are on the master node and inside the Flink directory:
bin/start-cluster.shTo stop Flink, there is also a stop-cluster.sh script.
Adding JobManager/TaskManager Instances to a Cluster
You can add both JobManager and TaskManager instances to your running cluster with the bin/jobmanager.sh and bin/taskmanager.sh scripts.
Adding a JobManager
bin/jobmanager.sh ((start|start-foreground) [host] [webui-port])|stop|stop-allAdding a TaskManager
bin/taskmanager.sh start|start-foreground|stop|stop-allMake sure to call these scripts on the hosts on which you want to start/stop the respective instance.