Overview #
Flink Table Store is a unified storage to build dynamic tables for both streaming and batch processing in Flink, supporting high-speed data ingestion and timely data query.
Architecture #
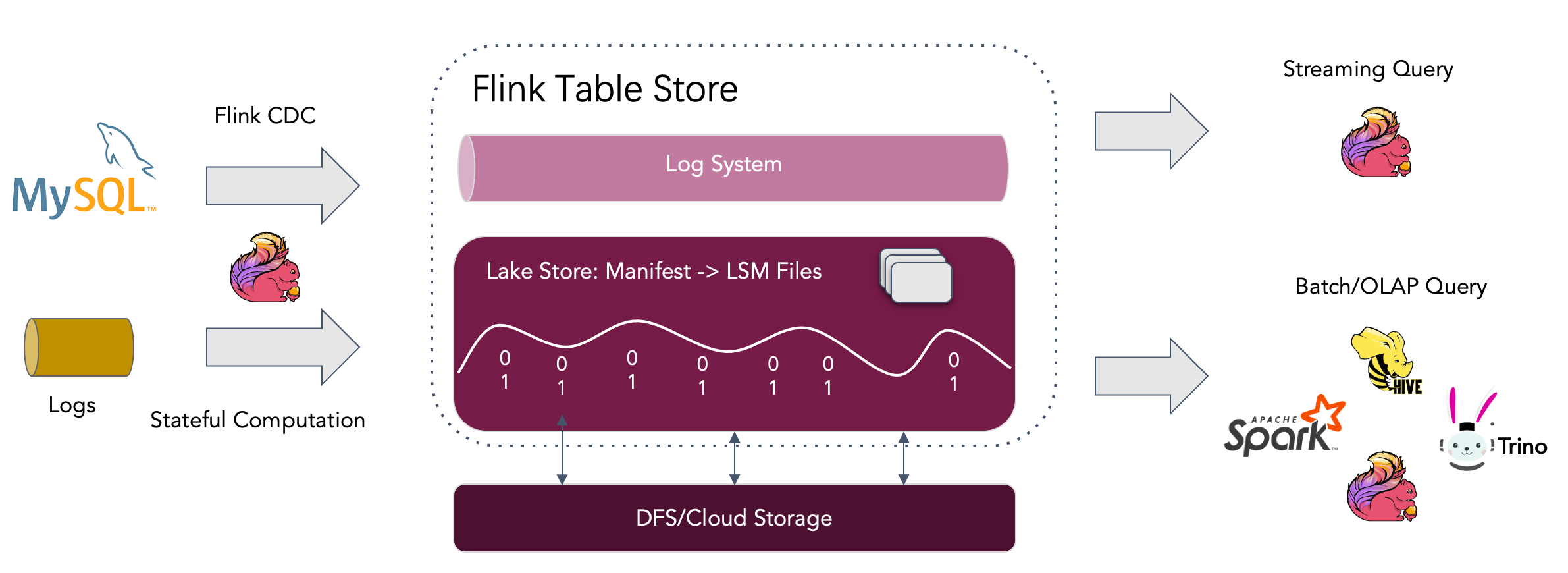
As shown in the architecture above:
Read/Write: Table Store supports a versatile way to read/write data and perform OLAP queries.
- For reads, it supports consuming data <1> from historical snapshots (in batch mode), <2>from the latest offset (in streaming mode), or <3> reading incremental snapshots in a hybrid way.
- For writes, it supports streaming synchronization from the changelog of databases (CDC) or batch insert/overwrite from offline data.
Ecosystem: In addition to Apache Flink, Table Store also supports read by other computation engines like Apache Hive, Apache Spark and Trino.
Internal: Under the hood, Table Store uses a hybrid storage architecture with a lake format to store historical data and a queue system to store incremental data. The former stores the columnar files on the filesystem/object-store and uses the LSM tree structure to support a large volume of data updates and high-performance queries. The latter uses Apache Kafka to capture data in real-time.
Setup Table Store #
Note: Table Store is only supported since Flink 1.14.
- Download flink-table-store-dist-0.2.1.jar for Flink 1.15.
- Download flink-table-store-dist-0.2.1_1.14.jar for Flink 1.14.
Flink Table Store has shaded all the dependencies in the package, so you don’t have to worry about conflicts with other connector dependencies.
The steps to set up are:
- Copy the Table Store bundle jar to
flink/lib. - Setting the HADOOP_CLASSPATH environment variable or copy the
Pre-bundled Hadoop Jar to
flink/lib.
Unified Storage #
There are three types of connectors in Flink SQL.
- Message queue, such as Apache Kafka, it is used in both source and intermediate stages in this pipeline, to guarantee the latency stay within seconds.
- OLAP system, such as Clickhouse, it receives processed data in streaming fashion and serving user’s ad-hoc queries.
- Batch storage, such as Apache Hive, it supports various operations
of the traditional batch processing, including
INSERT OVERWRITE.
Flink Table Store provides table abstraction. It is used in a way that does not differ from the traditional database:
- In Flink
batchexecution mode, it acts like a Hive table and supports various operations of Batch SQL. Query it to see the latest snapshot. - In Flink
streamingexecution mode, it acts like a message queue. Query it acts like querying a stream changelog from a message queue where historical data never expires.