Table Types #
Table Store supports various types of tables. Users can specify write-mode table property to specify table types when creating tables.
Changelog Tables with Primary Keys #
Changelog table is the default table type when creating a table. Users can insert, update or delete records in the table.
Primary keys are a set of columns that are unique for each record. Table Store imposes an ordering of data, which means the system will sort the primary key within each bucket. Using this feature, users can achieve high performance by adding filter conditions on the primary key.
By defining primary keys on a changelog table, users can access the following features.
Merge Engines #
When Table Store sink receives two or more records with the same primary keys, it will merge them into one record to keep primary keys unique. By specifying the merge-engine table property, users can choose how records are merged together.
Deduplicate #
deduplicate merge engine is the default merge engine. Table Store will only keep the latest record and throw away other records with the same primary keys.
Specifically, if the latest record is a DELETE record, all records with the same primary keys will be deleted.
Partial Update #
By specifying 'merge-engine' = 'partial-update', users can set columns of a record across multiple updates and finally get a complete record. Specifically, value fields are updated to the latest data one by one under the same primary key, but null values are not overwritten.
For example, let’s say Table Store receives three records:
<1, 23.0, 10, NULL>-<1, NULL, NULL, 'This is a book'><1, 25.2, NULL, NULL>
If the first column is the primary key. The final result will be <1, 25.2, 10, 'This is a book'>.
For streaming queries,partial-updatemerge engine must be used together withfull-compactionchangelog producer.
Partial cannot receiveDELETEmessages because the behavior cannot be defined. You can configurepartial-update.ignore-deleteto ignoreDELETEmessages.
Aggregation #
Sometimes users only care about aggregated results. The aggregation merge engine aggregates each value field with the latest data one by one under the same primary key according to the aggregate function.
Each field not part of the primary keys must be given an aggregate function, specified by the fields.<field-name>.aggregate-function table property. For example, consider the following table definition.
CREATE TABLE MyTable (
product_id BIGINT,
price DOUBLE,
sales BIGINT,
PRIMARY KEY (product_id) NOT ENFORCED
) WITH (
'merge-engine' = 'aggregation',
'fields.price.aggregate-function' = 'max',
'fields.sales.aggregate-function' = 'sum'
);
Field price will be aggregated by the max function, and field sales will be aggregated by the sum function. Given two input records <1, 23.0, 15> and <1, 30.2, 20>, the final result will be <1, 30.2, 35>.
Current supported aggregate functions and data types are:
sum: supports DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT and DOUBLE.min/max: support DECIMAL, TINYINT, SMALLINT, INTEGER, BIGINT, FLOAT, DOUBLE, DATE, TIME, TIMESTAMP and TIMESTAMP_LTZ.last_value/last_non_null_value: support all data types.listagg: supports STRING data type.bool_and/bool_or: support BOOLEAN data type.
Only sum supports retraction (UPDATE_BEFORE and DELETE), others aggregate functions do not support retraction.
If you allow some functions to ignore retraction messages, you can configure:
'fields.${field_name}.ignore-retract'='true'.
For streaming queries,aggregationmerge engine must be used together withfull-compactionchangelog producer.
Changelog Producers #
Streaming queries will continuously produce latest changes. These changes can come from the underlying table files or from an external log system like Kafka. Compared to the external log system, changes from table files have lower cost but higher latency (depending on how often snapshots are created).
By specifying the changelog-producer table property when creating the table, users can choose the pattern of changes produced from files.
The changelog-producer table property only affects changelog from files. It does not affect the external log system.
None #
By default, no extra changelog producer will be applied to the writer of table. Table Store source can only see the merged changes across snapshots, like what keys are removed and what are the new values of some keys.
However, these merged changes cannot form a complete changelog, because we can’t read the old values of the keys directly from them. Merged changes require the consumers to “remember” the values of each key and to rewrite the values without seeing the old ones. Some consumers, however, need the old values to ensure correctness or efficiency.
Consider a consumer which calculates the sum on some grouping keys (might not be equal to the primary keys). If the consumer only sees a new value 5, it cannot determine what values should be added to the summing result. For example, if the old value is 4, it should add 1 to the result. But if the old value is 6, it should in turn subtract 1 from the result. Old values are important for these types of consumers.
To conclude, none changelog producers are best suited for consumers such as a database system. Flink also has a built-in “normalize” operator which persists the values of each key in states. As one can easily tell, this operator will be very costly and should be avoided.

Input #
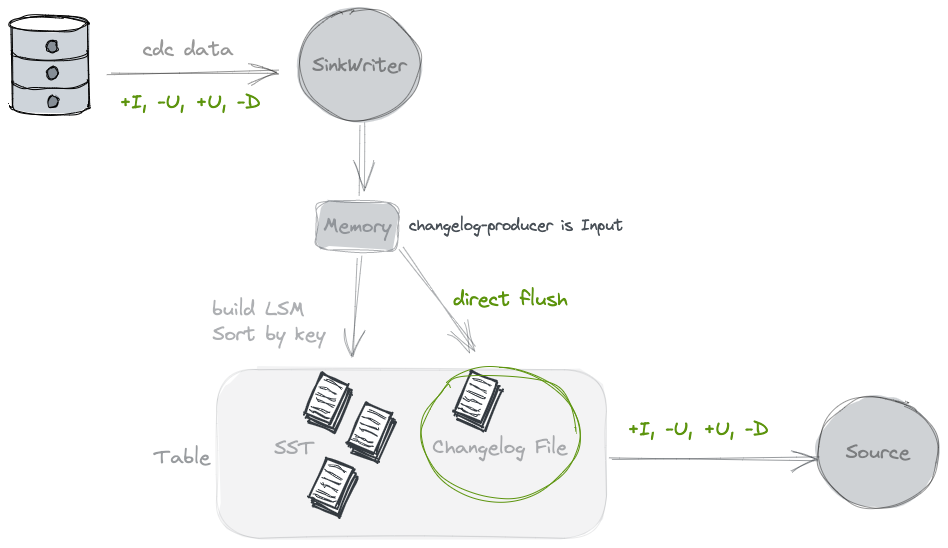
By specifying 'changelog-producer' = 'input', Table Store writers rely on their inputs as a source of complete changelog. All input records will be saved in separated changelog files and will be given to the consumers by Table Store sources.
input changelog producer can be used when Table Store writers' inputs are complete changelog, such as from a database CDC, or generated by Flink stateful computation.
Full Compaction #
If your input can’t produce a complete changelog but you still want to get rid of the costly normalized operator, you may consider using the full compaction changelog producer.
By specifying 'changelog-producer' = 'full-compaction', Table Store will compare the results between full compactions and produce the differences as changelog. The latency of changelog is affected by the frequency of full compactions.
By specifying changelog-producer.compaction-interval table property (default value 30min), users can define the maximum interval between two full compactions to ensure latency. This table property does not affect normal compactions and they may still be performed once in a while by writers to reduce reader costs.
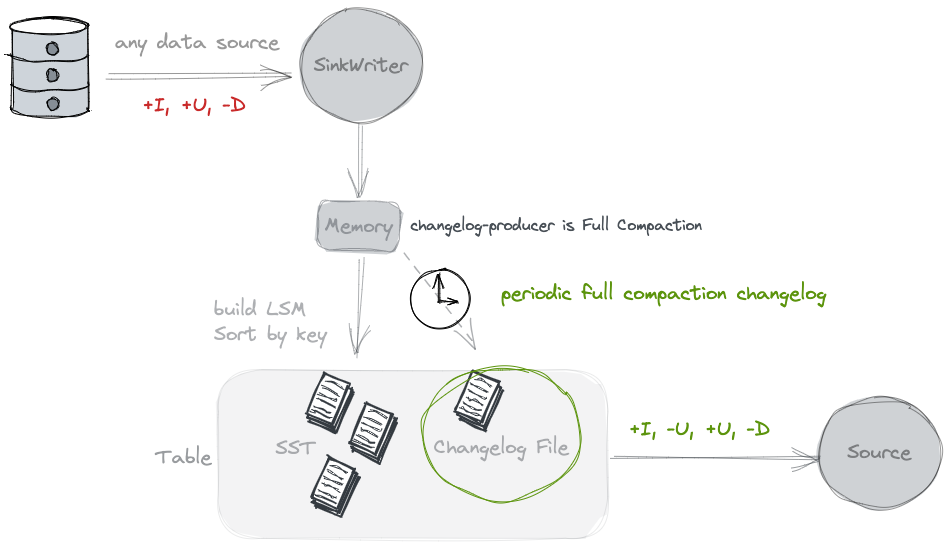
Full compaction changelog producer can produce complete changelog for any type of source. However it is not as efficient as the input changelog producer and the latency to produce changelog might be high.
Changelog Tables without Primary Keys #
Changelog tables can also be used without primary keys. Users can only insert or delete a whole record from the table. No update is supported.
Append-only Tables #
By specifying 'write-mode' = 'append-only' when creating the table, user creates an append-only table.
You can only insert a whole record into the table. No delete or update is supported and you cannot define primary keys. This type of table is suitable for use cases that do not require updates (such as log data synchronization).