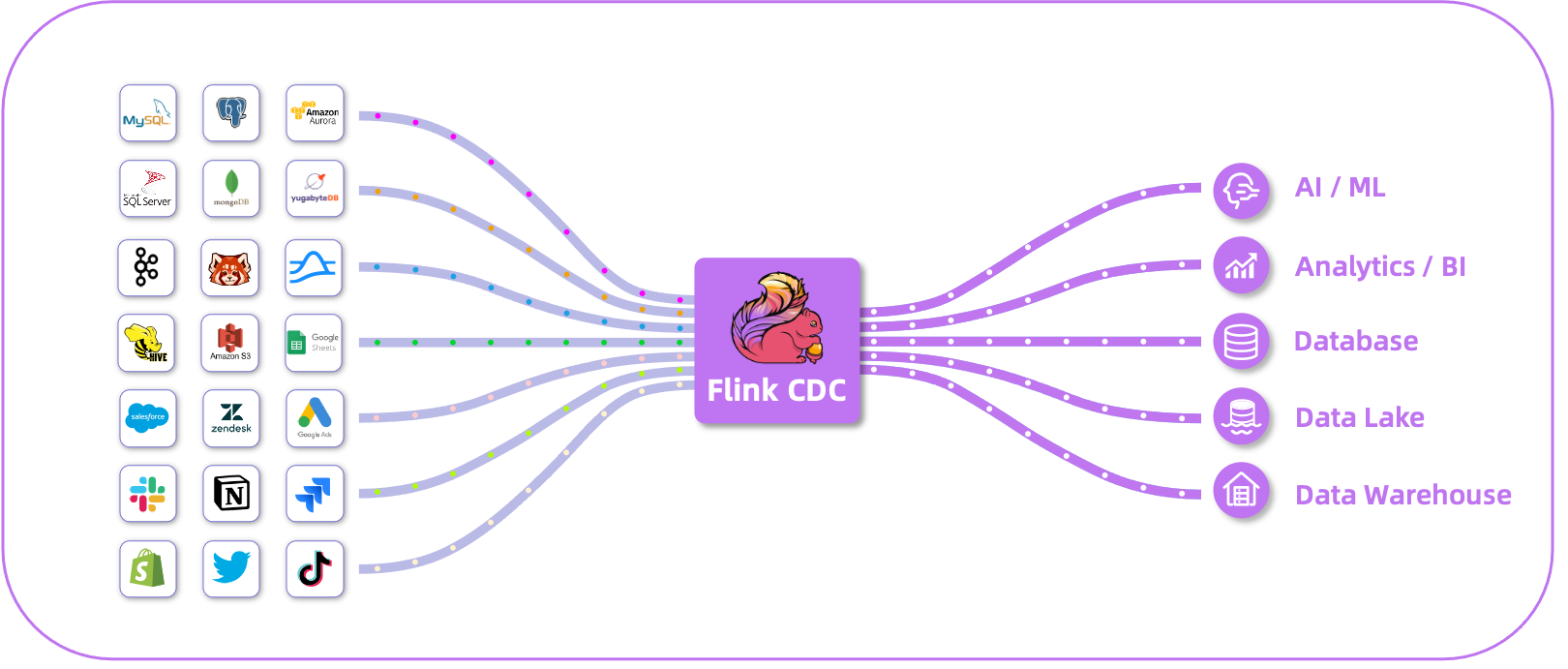
What is Flink CDC?
Flink CDC is a distributed data integration tool for real time data and batch data. Flink CDC brings the simplicity and elegance of data integration via YAML to describe the data movement and transformation.
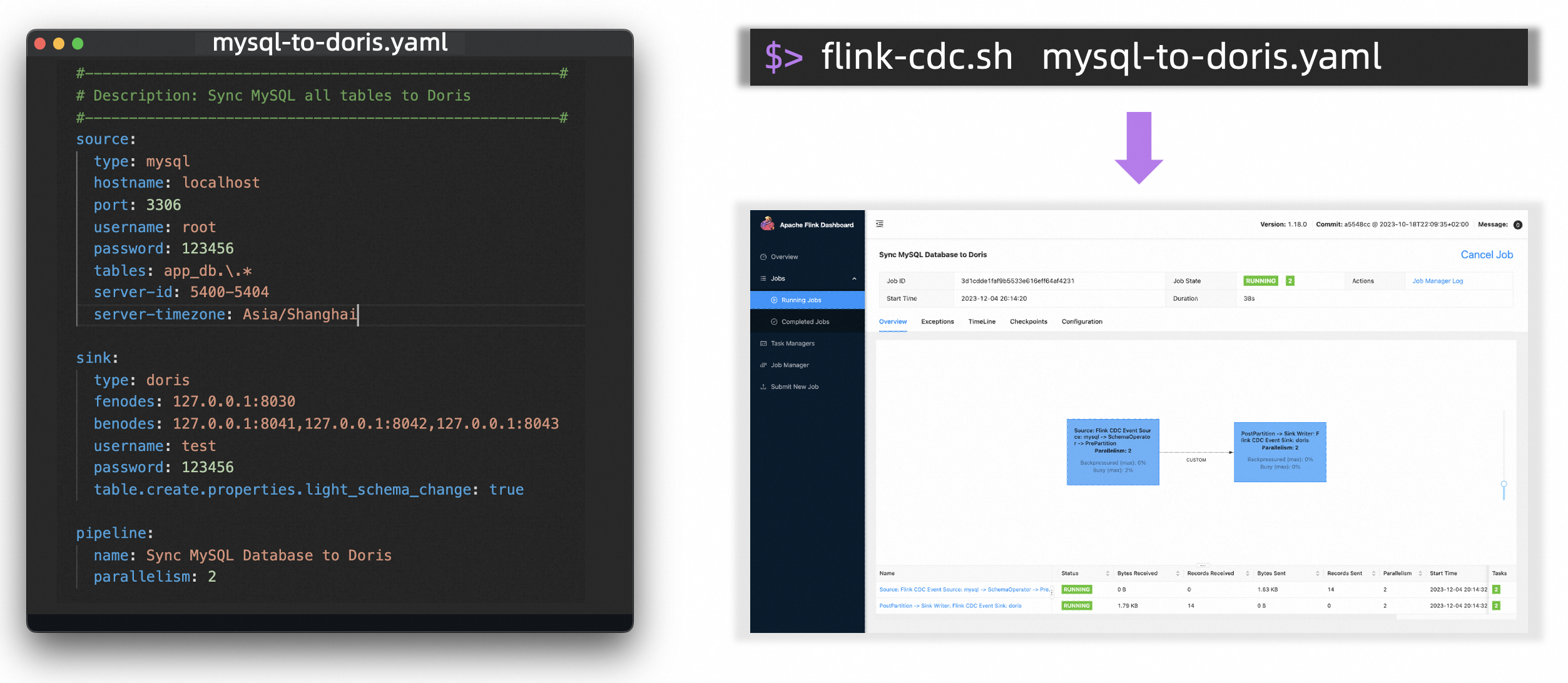
Key Features
Flink CDC supports distributed scanning of historical data of database and then automatically switches to change data capturing. The switch uses the incremental snapshot algorithm which ensure the switch action does not lock the database.
Flink CDC has the ability of automatically creating downstream table using the inferred table structure based on upstream table, and applying upstream DDL to downstream systems during change data capturing.
Flink CDC jobs run in streaming mode by default, providing sub-second end-to-end latency in real-time binlog synchronization scenarios, effectively ensuring data freshness for downstream businesses.
Flink CDC will soon support data transform operations of ETL, including column projection, computed column, filter expression and classical scalar functions.
Flink CDC supports synchronizing all tables of source database instance to downstream in one job by configuring the captured database list and table list.
Flink CDC supports reading database historical data and continues to read CDC events with exactly-once processing, even after job failures.
Learn More
Flink CDC provides a series of quick start demos without any dependencies or java code. A Linux or MacOS computer with Docker installed is enough. Please check out our Quick Start for more information.
If you get stuck, check out our community support resources. In particular, Apache Flink’s user mailing list (user@flink.apache.org) is consistently ranked as one of the most active of any Apache project, and is a great way to get help quickly.
Flink CDC is developed under the umbrella of Apache Flink.