User-defined Functions #
User-defined functions (UDFs) are extension points to call frequently used logic or custom logic that cannot be expressed otherwise in queries.
User-defined functions can be implemented in a JVM language (such as Java or Scala) or Python. An implementer can use arbitrary third party libraries within a UDF. This page will focus on JVM-based languages, please refer to the PyFlink documentation for details on writing general and vectorized UDFs in Python.
Overview #
Currently, Flink distinguishes between the following kinds of functions:
- Scalar functions map scalar values to a new scalar value.
- Table functions map scalar values to new rows.
- Aggregate functions map scalar values of multiple rows to a new scalar value.
- Table aggregate functions map scalar values of multiple rows to new rows.
- Async table functions are special functions for table sources that perform a lookup.
The following example shows how to create a simple scalar function and how to call the function in both Table API and SQL.
For SQL queries, a function must always be registered under a name. For Table API, a function can be registered or directly used inline.
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// define function logic
public static class SubstringFunction extends ScalarFunction {
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env.from("MyTable").select(call(SubstringFunction.class, $("myField"), 5, 12));
// register function
env.createTemporarySystemFunction("SubstringFunction", SubstringFunction.class);
// call registered function in Table API
env.from("MyTable").select(call("SubstringFunction", $("myField"), 5, 12));
// call registered function in SQL
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable");
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
// define function logic
class SubstringFunction extends ScalarFunction {
def eval(s: String, begin: Integer, end: Integer): String = {
s.substring(begin, end)
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env.from("MyTable").select(call(classOf[SubstringFunction], $"myField", 5, 12))
// register function
env.createTemporarySystemFunction("SubstringFunction", classOf[SubstringFunction])
// call registered function in Table API
env.from("MyTable").select(call("SubstringFunction", $"myField", 5, 12))
// call registered function in SQL
env.sqlQuery("SELECT SubstringFunction(myField, 5, 12) FROM MyTable")
For interactive sessions, it is also possible to parameterize functions before using or registering them. In this case, function instances instead of function classes can be used as temporary functions.
It requires that the parameters are serializable for shipping function instances to the cluster.
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
// define parameterizable function logic
public static class SubstringFunction extends ScalarFunction {
private boolean endInclusive;
public SubstringFunction(boolean endInclusive) {
this.endInclusive = endInclusive;
}
public String eval(String s, Integer begin, Integer end) {
return s.substring(begin, endInclusive ? end + 1 : end);
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env.from("MyTable").select(call(new SubstringFunction(true), $("myField"), 5, 12));
// register function
env.createTemporarySystemFunction("SubstringFunction", new SubstringFunction(true));
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
// define parameterizable function logic
class SubstringFunction(val endInclusive) extends ScalarFunction {
def eval(s: String, begin: Integer, end: Integer): String = {
s.substring(endInclusive ? end + 1 : end)
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env.from("MyTable").select(call(new SubstringFunction(true), $"myField", 5, 12))
// register function
env.createTemporarySystemFunction("SubstringFunction", new SubstringFunction(true))
You can use star * expression as one argument of the function call to act as a wildcard in Table API,
all columns in the table will be passed to the function at the corresponding position.
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class MyConcatFunction extends ScalarFunction {
public String eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object... fields) {
return Arrays.stream(fields)
.map(Object::toString)
.collect(Collectors.joining(","));
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function with $("*"), if MyTable has 3 fields (a, b, c),
// all of them will be passed to MyConcatFunction.
env.from("MyTable").select(call(MyConcatFunction.class, $("*")));
// it's equal to call function with explicitly selecting all columns.
env.from("MyTable").select(call(MyConcatFunction.class, $("a"), $("b"), $("c")));
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
import scala.annotation.varargs
class MyConcatFunction extends ScalarFunction {
@varargs
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) row: AnyRef*): String = {
row.map(f => f.toString).mkString(",")
}
}
val env = TableEnvironment.create(...)
// call function with $"*", if MyTable has 3 fields (a, b, c),
// all of them will be passed to MyConcatFunction.
env.from("MyTable").select(call(classOf[MyConcatFunction], $"*"));
// it's equal to call function with explicitly selecting all columns.
env.from("MyTable").select(call(classOf[MyConcatFunction], $"a", $"b", $"c"));
Implementation Guide #
Independent of the kind of function, all user-defined functions follow some basic implementation principles.
Function Class #
An implementation class must extend from one of the available base classes (e.g. org.apache.flink.table.functions.ScalarFunction).
The class must be declared public, not abstract, and should be globally accessible. Thus, non-static inner or anonymous classes are not allowed.
For storing a user-defined function in a persistent catalog, the class must have a default constructor and must be instantiable during runtime. Anonymous functions in Table API can only be persisted if the function is not stateful (i.e. containing only transient and static fields).
Evaluation Methods #
The base class provides a set of methods that can be overridden such as open(), close(), or isDeterministic().
However, in addition to those declared methods, the main runtime logic that is applied to every incoming record must be implemented through specialized evaluation methods.
Depending on the function kind, evaluation methods such as eval(), accumulate(), or retract() are called by code-generated operators during runtime.
The methods must be declared public and take a well-defined set of arguments.
Regular JVM method calling semantics apply. Therefore, it is possible to:
- implement overloaded methods such as
eval(Integer)andeval(LocalDateTime), - use var-args such as
eval(Integer...), - use object inheritance such as
eval(Object)that takes bothLocalDateTimeandInteger, - and combinations of the above such as
eval(Object...)that takes all kinds of arguments.
If you intend to implement functions in Scala, please add the scala.annotation.varargs annotation in
case of variable arguments. Furthermore, it is recommended to use boxed primitives (e.g. java.lang.Integer
instead of Int) to support NULL.
The following snippets shows an example of an overloaded function:
import org.apache.flink.table.functions.ScalarFunction;
// function with overloaded evaluation methods
public static class SumFunction extends ScalarFunction {
public Integer eval(Integer a, Integer b) {
return a + b;
}
public Integer eval(String a, String b) {
return Integer.valueOf(a) + Integer.valueOf(b);
}
public Integer eval(Double... d) {
double result = 0;
for (double value : d)
result += value;
return (int) result;
}
}
import org.apache.flink.table.functions.ScalarFunction
import java.lang.Integer
import java.lang.Double
import scala.annotation.varargs
// function with overloaded evaluation methods
class SumFunction extends ScalarFunction {
def eval(a: Integer, b: Integer): Integer = {
a + b
}
def eval(a: String, b: String): Integer = {
Integer.valueOf(a) + Integer.valueOf(b)
}
@varargs // generate var-args like Java
def eval(d: Double*): Integer = {
d.sum.toInt
}
}
Type Inference #
The table ecosystem (similar to the SQL standard) is a strongly typed API. Therefore, both function parameters and return types must be mapped to a data type.
From a logical perspective, the planner needs information about expected types, precision, and scale. From a JVM perspective, the planner needs information about how internal data structures are represented as JVM objects when calling a user-defined function.
The logic for validating input arguments and deriving data types for both the parameters and the result of a function is summarized under the term type inference.
Flink’s user-defined functions implement an automatic type inference extraction that derives data types from the function’s class and its evaluation methods via reflection. If this implicit reflective extraction approach is not successful, the extraction process can be supported by annotating affected parameters, classes, or methods with @DataTypeHint and @FunctionHint. More examples on how to annotate functions are shown below.
If more advanced type inference logic is required, an implementer can explicitly override the getTypeInference() method in every user-defined function. However, the annotation approach is recommended because it keeps custom type inference logic close to the affected locations and falls back to the default behavior for the remaining implementation.
Automatic Type Inference #
The automatic type inference inspects the function’s class and evaluation methods to derive data types for the arguments and result of a function. @DataTypeHint and @FunctionHint annotations support the automatic extraction.
For a full list of classes that can be implicitly mapped to a data type, see the data type extraction section.
@DataTypeHint
In many scenarios, it is required to support the automatic extraction inline for parameters and return types of a function
The following example shows how to use data type hints. More information can be found in the documentation of the annotation class.
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;
// function with overloaded evaluation methods
public static class OverloadedFunction extends ScalarFunction {
// no hint required
public Long eval(long a, long b) {
return a + b;
}
// define the precision and scale of a decimal
public @DataTypeHint("DECIMAL(12, 3)") BigDecimal eval(double a, double b) {
return BigDecimal.valueOf(a + b);
}
// define a nested data type
@DataTypeHint("ROW<s STRING, t TIMESTAMP_LTZ(3)>")
public Row eval(int i) {
return Row.of(String.valueOf(i), Instant.ofEpochSecond(i));
}
// allow wildcard input and customly serialized output
@DataTypeHint(value = "RAW", bridgedTo = ByteBuffer.class)
public ByteBuffer eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return MyUtils.serializeToByteBuffer(o);
}
}
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.InputGroup
import org.apache.flink.table.functions.ScalarFunction
import org.apache.flink.types.Row
import scala.annotation.varargs
// function with overloaded evaluation methods
class OverloadedFunction extends ScalarFunction {
// no hint required
def eval(a: Long, b: Long): Long = {
a + b
}
// define the precision and scale of a decimal
@DataTypeHint("DECIMAL(12, 3)")
def eval(double a, double b): BigDecimal = {
java.lang.BigDecimal.valueOf(a + b)
}
// define a nested data type
@DataTypeHint("ROW<s STRING, t TIMESTAMP_LTZ(3)>")
def eval(Int i): Row = {
Row.of(java.lang.String.valueOf(i), java.time.Instant.ofEpochSecond(i))
}
// allow wildcard input and customly serialized output
@DataTypeHint(value = "RAW", bridgedTo = classOf[java.nio.ByteBuffer])
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o): java.nio.ByteBuffer = {
MyUtils.serializeToByteBuffer(o)
}
}
@FunctionHint
In some scenarios, it is desirable that one evaluation method handles multiple different data types at the same time. Furthermore, in some scenarios, overloaded evaluation methods have a common result type that should be declared only once.
The @FunctionHint annotation can provide a mapping from argument data types to a result data type. It enables annotating entire function classes or evaluation methods for input, accumulator, and result data types. One or more annotations can be declared on top of a class or individually for each evaluation method for overloading function signatures. All hint parameters are optional. If a parameter is not defined, the default reflection-based extraction is used. Hint parameters defined on top of a function class are inherited by all evaluation methods.
The following example shows how to use function hints. More information can be found in the documentation of the annotation class.
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
// function with overloaded evaluation methods
// but globally defined output type
@FunctionHint(output = @DataTypeHint("ROW<s STRING, i INT>"))
public static class OverloadedFunction extends TableFunction<Row> {
public void eval(int a, int b) {
collect(Row.of("Sum", a + b));
}
// overloading of arguments is still possible
public void eval() {
collect(Row.of("Empty args", -1));
}
}
// decouples the type inference from evaluation methods,
// the type inference is entirely determined by the function hints
@FunctionHint(
input = {@DataTypeHint("INT"), @DataTypeHint("INT")},
output = @DataTypeHint("INT")
)
@FunctionHint(
input = {@DataTypeHint("BIGINT"), @DataTypeHint("BIGINT")},
output = @DataTypeHint("BIGINT")
)
@FunctionHint(
input = {},
output = @DataTypeHint("BOOLEAN")
)
public static class OverloadedFunction extends TableFunction<Object> {
// an implementer just needs to make sure that a method exists
// that can be called by the JVM
public void eval(Object... o) {
if (o.length == 0) {
collect(false);
}
collect(o[0]);
}
}
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.FunctionHint
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
// function with overloaded evaluation methods
// but globally defined output type
@FunctionHint(output = new DataTypeHint("ROW<s STRING, i INT>"))
class OverloadedFunction extends TableFunction[Row] {
def eval(a: Int, b: Int): Unit = {
collect(Row.of("Sum", Int.box(a + b)))
}
// overloading of arguments is still possible
def eval(): Unit = {
collect(Row.of("Empty args", Int.box(-1)))
}
}
// decouples the type inference from evaluation methods,
// the type inference is entirely determined by the function hints
@FunctionHint(
input = Array(new DataTypeHint("INT"), new DataTypeHint("INT")),
output = new DataTypeHint("INT")
)
@FunctionHint(
input = Array(new DataTypeHint("BIGINT"), new DataTypeHint("BIGINT")),
output = new DataTypeHint("BIGINT")
)
@FunctionHint(
input = Array(),
output = new DataTypeHint("BOOLEAN")
)
class OverloadedFunction extends TableFunction[AnyRef] {
// an implementer just needs to make sure that a method exists
// that can be called by the JVM
@varargs
def eval(o: AnyRef*) = {
if (o.length == 0) {
collect(Boolean.box(false))
}
collect(o(0))
}
}
Custom Type Inference #
For most scenarios, @DataTypeHint and @FunctionHint should be sufficient to model user-defined functions. However, by overriding the automatic type inference defined in getTypeInference(), implementers can create arbitrary functions that behave like built-in system functions.
The following example implemented in Java illustrates the potential of a custom type inference logic. It uses a string literal argument to determine the result type of a function. The function takes two string arguments: the first argument represents the string to be parsed, the second argument represents the target type.
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.catalog.DataTypeFactory;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.table.types.inference.TypeInference;
import org.apache.flink.types.Row;
public static class LiteralFunction extends ScalarFunction {
public Object eval(String s, String type) {
switch (type) {
case "INT":
return Integer.valueOf(s);
case "DOUBLE":
return Double.valueOf(s);
case "STRING":
default:
return s;
}
}
// the automatic, reflection-based type inference is disabled and
// replaced by the following logic
@Override
public TypeInference getTypeInference(DataTypeFactory typeFactory) {
return TypeInference.newBuilder()
// specify typed arguments
// parameters will be casted implicitly to those types if necessary
.typedArguments(DataTypes.STRING(), DataTypes.STRING())
// specify a strategy for the result data type of the function
.outputTypeStrategy(callContext -> {
if (!callContext.isArgumentLiteral(1) || callContext.isArgumentNull(1)) {
throw callContext.newValidationError("Literal expected for second argument.");
}
// return a data type based on a literal
final String literal = callContext.getArgumentValue(1, String.class).orElse("STRING");
switch (literal) {
case "INT":
return Optional.of(DataTypes.INT().notNull());
case "DOUBLE":
return Optional.of(DataTypes.DOUBLE().notNull());
case "STRING":
default:
return Optional.of(DataTypes.STRING());
}
})
.build();
}
}
For more examples of custom type inference, see also the flink-examples-table module with
advanced function implementation
.
Determinism #
Every user-defined function class can declare whether it produces deterministic results or not by overriding
the isDeterministic() method. If the function is not purely functional (like random(), date(), or now()),
the method must return false. By default, isDeterministic() returns true.
Furthermore, the isDeterministic() method might also influence the runtime behavior. A runtime
implementation might be called at two different stages:
1. During planning (i.e. pre-flight phase): If a function is called with constant expressions
or constant expressions can be derived from the given statement, a function is pre-evaluated
for constant expression reduction and might not be executed on the cluster anymore. Unless
isDeterministic() is used to disable constant expression reduction in this case. For example,
the following calls to ABS are executed during planning: SELECT ABS(-1) FROM t and
SELECT ABS(field) FROM t WHERE field = -1; whereas SELECT ABS(field) FROM t is not.
2. During runtime (i.e. cluster execution): If a function is called with non-constant expressions
or isDeterministic() returns false.
System (Built-in) Function Determinism #
The determinism of system (built-in) functions are immutable. There exists two kinds of functions which are not deterministic:
dynamic function and non-deterministic function, according to Apache Calcite’s SqlOperator definition:
/**
* Returns whether a call to this operator is guaranteed to always return
* the same result given the same operands; true is assumed by default.
*/
public boolean isDeterministic() {
return true;
}
/**
* Returns whether it is unsafe to cache query plans referencing this
* operator; false is assumed by default.
*/
public boolean isDynamicFunction() {
return false;
}
isDeterministic indicates the determinism of a function, will be evaluated per record during runtime if returns false.
isDynamicFunction implies the function can only be evaluated at query-start if returns true,
it will be only pre-evaluated during planning for batch mode, while for streaming mode, it is equivalent to a non-deterministic
function because of the query is continuously being executed logically(the abstraction of continuous query over the dynamic tables),
so the dynamic functions are also re-evaluated for each query execution(equivalent to per record in current implementation).
The following system functions are always non-deterministic(evaluated per record during runtime both in batch and streaming mode):
- UUID
- RAND
- RAND_INTEGER
- CURRENT_DATABASE
- UNIX_TIMESTAMP
- CURRENT_ROW_TIMESTAMP
The following system temporal functions are dynamic, which will be pre-evaluated during planning(query-start) for batch mode and evaluated per record for streaming mode:
- CURRENT_DATE
- CURRENT_TIME
- CURRENT_TIMESTAMP
- NOW
- LOCALTIME
- LOCALTIMESTAMP
Note: isDynamicFunction is only applicable for system functions.
Runtime Integration #
Sometimes it might be necessary for a user-defined function to get global runtime information or do some setup/clean-up work before the actual work. User-defined functions provide open() and close() methods that can be overridden and provide similar functionality as the methods in RichFunction of DataStream API.
The open() method is called once before the evaluation method. The close() method after the last call to the evaluation method.
The open() method provides a FunctionContext that contains information about the context in which user-defined functions are executed, such as the metric group, the distributed cache files, or the global job parameters.
The following information can be obtained by calling the corresponding methods of FunctionContext:
| Method | Description |
|---|---|
getMetricGroup() |
Metric group for this parallel subtask. |
getCachedFile(name) |
Local temporary file copy of a distributed cache file. |
getJobParameter(name, defaultValue) |
Global job parameter value associated with given key. |
getExternalResourceInfos(resourceName) |
Returns a set of external resource infos associated with the given key. |
Note: Depending on the context in which the function is executed, not all methods from above might be available. For example, during constant expression reduction adding a metric is a no-op operation.
The following example snippet shows how to use FunctionContext in a scalar function for accessing a global job parameter:
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.FunctionContext;
import org.apache.flink.table.functions.ScalarFunction;
public static class HashCodeFunction extends ScalarFunction {
private int factor = 0;
@Override
public void open(FunctionContext context) throws Exception {
// access the global "hashcode_factor" parameter
// "12" would be the default value if the parameter does not exist
factor = Integer.parseInt(context.getJobParameter("hashcode_factor", "12"));
}
public int eval(String s) {
return s.hashCode() * factor;
}
}
TableEnvironment env = TableEnvironment.create(...);
// add job parameter
env.getConfig().addJobParameter("hashcode_factor", "31");
// register the function
env.createTemporarySystemFunction("hashCode", HashCodeFunction.class);
// use the function
env.sqlQuery("SELECT myField, hashCode(myField) FROM MyTable");
import org.apache.flink.table.api._
import org.apache.flink.table.functions.FunctionContext
import org.apache.flink.table.functions.ScalarFunction
class HashCodeFunction extends ScalarFunction {
private var factor: Int = 0
override def open(context: FunctionContext): Unit = {
// access the global "hashcode_factor" parameter
// "12" would be the default value if the parameter does not exist
factor = context.getJobParameter("hashcode_factor", "12").toInt
}
def eval(s: String): Int = {
s.hashCode * factor
}
}
val env = TableEnvironment.create(...)
// add job parameter
env.getConfig.addJobParameter("hashcode_factor", "31")
// register the function
env.createTemporarySystemFunction("hashCode", classOf[HashCodeFunction])
// use the function
env.sqlQuery("SELECT myField, hashCode(myField) FROM MyTable")
Scalar Functions #
A user-defined scalar function maps zero, one, or multiple scalar values to a new scalar value. Any data type listed in the data types section can be used as a parameter or return type of an evaluation method.
In order to define a scalar function, one has to extend the base class ScalarFunction in org.apache.flink.table.functions and implement one or more evaluation methods named eval(...).
The following example shows how to define your own hash code function and call it in a query. See the Implementation Guide for more details.
import org.apache.flink.table.annotation.InputGroup;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.ScalarFunction;
import static org.apache.flink.table.api.Expressions.*;
public static class HashFunction extends ScalarFunction {
// take any data type and return INT
public int eval(@DataTypeHint(inputGroup = InputGroup.ANY) Object o) {
return o.hashCode();
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env.from("MyTable").select(call(HashFunction.class, $("myField")));
// register function
env.createTemporarySystemFunction("HashFunction", HashFunction.class);
// call registered function in Table API
env.from("MyTable").select(call("HashFunction", $("myField")));
// call registered function in SQL
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable");
import org.apache.flink.table.annotation.InputGroup
import org.apache.flink.table.api._
import org.apache.flink.table.functions.ScalarFunction
class HashFunction extends ScalarFunction {
// take any data type and return INT
def eval(@DataTypeHint(inputGroup = InputGroup.ANY) o: AnyRef): Int = {
o.hashCode()
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env.from("MyTable").select(call(classOf[HashFunction], $"myField"))
// register function
env.createTemporarySystemFunction("HashFunction", classOf[HashFunction])
// call registered function in Table API
env.from("MyTable").select(call("HashFunction", $"myField"))
// call registered function in SQL
env.sqlQuery("SELECT HashFunction(myField) FROM MyTable")
If you intend to implement or call functions in Python, please refer to the Python Scalar Functions documentation for more details.
Table Functions #
Similar to a user-defined scalar function, a user-defined table function (UDTF) takes zero, one, or multiple scalar values as input arguments. However, it can return an arbitrary number of rows (or structured types) as output instead of a single value. The returned record may consist of one or more fields. If an output record consists of only a single field, the structured record can be omitted, and a scalar value can be emitted that will be implicitly wrapped into a row by the runtime.
In order to define a table function, one has to extend the base class TableFunction in org.apache.flink.table.functions and implement one or more evaluation methods named eval(...). Similar to other functions, input and output data types are automatically extracted using reflection. This includes the generic argument T of the class for determining an output data type. In contrast to scalar functions, the evaluation method itself must not have a return type, instead, table functions provide a collect(T) method that can be called within every evaluation method for emitting zero, one, or more records.
In the Table API, a table function is used with .joinLateral(...) or .leftOuterJoinLateral(...). The joinLateral operator (cross) joins each row from the outer table (table on the left of the operator) with all rows produced by the table-valued function (which is on the right side of the operator). The leftOuterJoinLateral operator joins each row from the outer table (table on the left of the operator) with all rows produced by the table-valued function (which is on the right side of the operator) and preserves outer rows for which the table function returns an empty table.
In SQL, use LATERAL TABLE(<TableFunction>) with JOIN or LEFT JOIN with an ON TRUE join condition.
The following example shows how to define your own split function and call it in a query. See the Implementation Guide for more details.
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.*;
@FunctionHint(output = @DataTypeHint("ROW<word STRING, length INT>"))
public static class SplitFunction extends TableFunction<Row> {
public void eval(String str) {
for (String s : str.split(" ")) {
// use collect(...) to emit a row
collect(Row.of(s, s.length()));
}
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env
.from("MyTable")
.joinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")))
.select($("myField"), $("word"), $("length"));
// rename fields of the function in Table API
env
.from("MyTable")
.leftOuterJoinLateral(call(SplitFunction.class, $("myField")).as("newWord", "newLength"))
.select($("myField"), $("newWord"), $("newLength"));
// register function
env.createTemporarySystemFunction("SplitFunction", SplitFunction.class);
// call registered function in Table API
env
.from("MyTable")
.joinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
env
.from("MyTable")
.leftOuterJoinLateral(call("SplitFunction", $("myField")))
.select($("myField"), $("word"), $("length"));
// call registered function in SQL
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))");
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE");
// rename fields of the function in SQL
env.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE");
import org.apache.flink.table.annotation.DataTypeHint
import org.apache.flink.table.annotation.FunctionHint
import org.apache.flink.table.api._
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
@FunctionHint(output = new DataTypeHint("ROW<word STRING, length INT>"))
class SplitFunction extends TableFunction[Row] {
def eval(str: String): Unit = {
// use collect(...) to emit a row
str.split(" ").foreach(s => collect(Row.of(s, Int.box(s.length))))
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env
.from("MyTable")
.joinLateral(call(classOf[SplitFunction], $"myField")
.select($"myField", $"word", $"length")
env
.from("MyTable")
.leftOuterJoinLateral(call(classOf[SplitFunction], $"myField"))
.select($"myField", $"word", $"length")
// rename fields of the function in Table API
env
.from("MyTable")
.leftOuterJoinLateral(call(classOf[SplitFunction], $"myField").as("newWord", "newLength"))
.select($"myField", $"newWord", $"newLength")
// register function
env.createTemporarySystemFunction("SplitFunction", classOf[SplitFunction])
// call registered function in Table API
env
.from("MyTable")
.joinLateral(call("SplitFunction", $"myField"))
.select($"myField", $"word", $"length")
env
.from("MyTable")
.leftOuterJoinLateral(call("SplitFunction", $"myField"))
.select($"myField", $"word", $"length")
// call registered function in SQL
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable, LATERAL TABLE(SplitFunction(myField))")
env.sqlQuery(
"SELECT myField, word, length " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) ON TRUE")
// rename fields of the function in SQL
env.sqlQuery(
"SELECT myField, newWord, newLength " +
"FROM MyTable " +
"LEFT JOIN LATERAL TABLE(SplitFunction(myField)) AS T(newWord, newLength) ON TRUE")
If you intend to implement functions in Scala, do not implement a table function as a Scala object. Scala objects are singletons and will cause concurrency issues.
If you intend to implement or call functions in Python, please refer to the Python Table Functions documentation for more details.
Aggregate Functions #
A user-defined aggregate function (UDAGG) maps scalar values of multiple rows to a new scalar value.
The behavior of an aggregate function is centered around the concept of an accumulator. The accumulator is an intermediate data structure that stores the aggregated values until a final aggregation result is computed.
For each set of rows that needs to be aggregated, the runtime will create an empty accumulator by calling
createAccumulator(). Subsequently, the accumulate(...) method of the function is called for each input
row to update the accumulator. Once all rows have been processed, the getValue(...) method of the
function is called to compute and return the final result.
The following example illustrates the aggregation process:
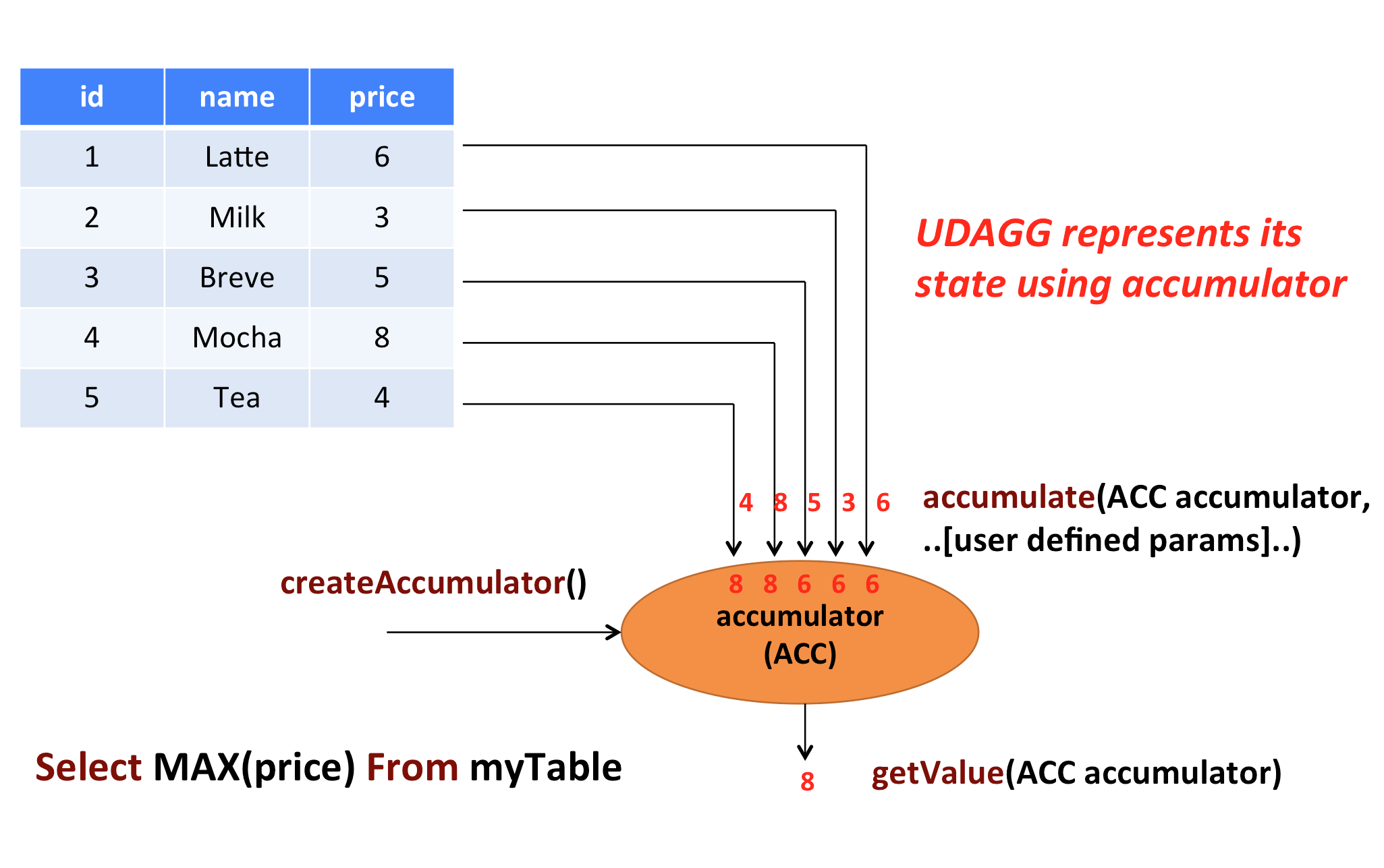
In the example, we assume a table that contains data about beverages. The table consists of three columns (id, name,
and price) and 5 rows. We would like to find the highest price of all beverages in the table, i.e., perform
a max() aggregation. We need to consider each of the 5 rows. The result is a single numeric value.
In order to define an aggregate function, one has to extend the base class AggregateFunction in
org.apache.flink.table.functions and implement one or more evaluation methods named accumulate(...).
An accumulate method must be declared publicly and not static. Accumulate methods can also be overloaded
by implementing multiple methods named accumulate.
By default, input, accumulator, and output data types are automatically extracted using reflection. This
includes the generic argument ACC of the class for determining an accumulator data type and the generic
argument T for determining an accumulator data type. Input arguments are derived from one or more
accumulate(...) methods. See the Implementation Guide for more details.
If you intend to implement or call functions in Python, please refer to the Python Functions documentation for more details.
The following example shows how to define your own aggregate function and call it in a query.
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.AggregateFunction;
import static org.apache.flink.table.api.Expressions.*;
// mutable accumulator of structured type for the aggregate function
public static class WeightedAvgAccumulator {
public long sum = 0;
public int count = 0;
}
// function that takes (value BIGINT, weight INT), stores intermediate results in a structured
// type of WeightedAvgAccumulator, and returns the weighted average as BIGINT
public static class WeightedAvg extends AggregateFunction<Long, WeightedAvgAccumulator> {
@Override
public WeightedAvgAccumulator createAccumulator() {
return new WeightedAvgAccumulator();
}
@Override
public Long getValue(WeightedAvgAccumulator acc) {
if (acc.count == 0) {
return null;
} else {
return acc.sum / acc.count;
}
}
public void accumulate(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum += iValue * iWeight;
acc.count += iWeight;
}
public void retract(WeightedAvgAccumulator acc, Long iValue, Integer iWeight) {
acc.sum -= iValue * iWeight;
acc.count -= iWeight;
}
public void merge(WeightedAvgAccumulator acc, Iterable<WeightedAvgAccumulator> it) {
for (WeightedAvgAccumulator a : it) {
acc.count += a.count;
acc.sum += a.sum;
}
}
public void resetAccumulator(WeightedAvgAccumulator acc) {
acc.count = 0;
acc.sum = 0L;
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env
.from("MyTable")
.groupBy($("myField"))
.select($("myField"), call(WeightedAvg.class, $("value"), $("weight")));
// register function
env.createTemporarySystemFunction("WeightedAvg", WeightedAvg.class);
// call registered function in Table API
env
.from("MyTable")
.groupBy($("myField"))
.select($("myField"), call("WeightedAvg", $("value"), $("weight")));
// call registered function in SQL
env.sqlQuery(
"SELECT myField, WeightedAvg(`value`, weight) FROM MyTable GROUP BY myField"
);
import org.apache.flink.table.api._
import org.apache.flink.table.functions.AggregateFunction
// mutable accumulator of structured type for the aggregate function
case class WeightedAvgAccumulator(
var sum: Long = 0,
var count: Int = 0
)
// function that takes (value BIGINT, weight INT), stores intermediate results in a structured
// type of WeightedAvgAccumulator, and returns the weighted average as BIGINT
class WeightedAvg extends AggregateFunction[java.lang.Long, WeightedAvgAccumulator] {
override def createAccumulator(): WeightedAvgAccumulator = {
WeightedAvgAccumulator()
}
override def getValue(acc: WeightedAvgAccumulator): java.lang.Long = {
if (acc.count == 0) {
null
} else {
acc.sum / acc.count
}
}
def accumulate(acc: WeightedAvgAccumulator, iValue: java.lang.Long, iWeight: java.lang.Integer): Unit = {
acc.sum += iValue * iWeight
acc.count += iWeight
}
def retract(acc: WeightedAvgAccumulator, iValue: java.lang.Long, iWeight: java.lang.Integer): Unit = {
acc.sum -= iValue * iWeight
acc.count -= iWeight
}
def merge(acc: WeightedAvgAccumulator, it: java.lang.Iterable[WeightedAvgAccumulator]): Unit = {
val iter = it.iterator()
while (iter.hasNext) {
val a = iter.next()
acc.count += a.count
acc.sum += a.sum
}
}
def resetAccumulator(acc: WeightedAvgAccumulator): Unit = {
acc.count = 0
acc.sum = 0L
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env
.from("MyTable")
.groupBy($"myField")
.select($"myField", call(classOf[WeightedAvg], $"value", $"weight"))
// register function
env.createTemporarySystemFunction("WeightedAvg", classOf[WeightedAvg])
// call registered function in Table API
env
.from("MyTable")
.groupBy($"myField")
.select($"myField", call("WeightedAvg", $"value", $"weight"))
// call registered function in SQL
env.sqlQuery(
"SELECT myField, WeightedAvg(`value`, weight) FROM MyTable GROUP BY myField"
)
The accumulate(...) method of our WeightedAvg class takes three inputs. The first one is the accumulator
and the other two are user-defined inputs. In order to calculate a weighted average value, the accumulator
needs to store the weighted sum and count of all the data that has been accumulated. In our example, we
define a class WeightedAvgAccumulator to be the accumulator. Accumulators are automatically managed
by Flink’s checkpointing mechanism and are restored in case of a failure to ensure exactly-once semantics.
Mandatory and Optional Methods #
The following methods are mandatory for each AggregateFunction:
createAccumulator()accumulate(...)getValue(...)
Additionally, there are a few methods that can be optionally implemented. While some of these methods
allow the system more efficient query execution, others are mandatory for certain use cases. For instance,
the merge(...) method is mandatory if the aggregation function should be applied in the context of a
session group window (the accumulators of two session windows need to be joined when a row is observed
that “connects” them).
The following methods of AggregateFunction are required depending on the use case:
retract(...)is required for aggregations onOVERwindows.merge(...)is required for many bounded aggregations and session window and hop window aggregations. Besides, this method is also helpful for optimizations. For example, two phase aggregation optimization requires all theAggregateFunctionsupportmergemethod.
If the aggregate function can only be applied in an OVER window, this can be declared by returning the
requirement FunctionRequirement.OVER_WINDOW_ONLY in getRequirements().
If an accumulator needs to store large amounts of data, org.apache.flink.table.api.dataview.ListView
and org.apache.flink.table.api.dataview.MapView provide advanced features for leveraging Flink’s state
backends in unbounded data scenarios. Please see the docs of the corresponding classes for more information
about this advanced feature.
Since some of the methods are optional, or can be overloaded, the runtime invokes aggregate function methods via generated code. This means the base class does not always provide a signature to be overridden by the concrete implementation. Nevertheless, all mentioned methods must be declared publicly, not static, and named exactly as the names mentioned above to be called.
Detailed documentation for all methods that are not declared in AggregateFunction and called by generated
code is given below.
accumulate(...)
/*
* Processes the input values and updates the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An aggregate function
* requires at least one accumulate() method.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs])
/*
* Processes the input values and updates the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An aggregate function
* requires at least one accumulate() method.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit
retract(...)
/*
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This method must be implemented for
* bounded OVER aggregates over unbounded tables.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs])
/*
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This method must be implemented for
* bounded OVER aggregates over unbounded tables.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit
merge(...)
/*
* Merges a group of accumulator instances into one accumulator instance. This method must be
* implemented for unbounded session window grouping aggregates and bounded grouping aggregates.
*
* param: accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* param: iterable an java.lang.Iterable pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> iterable)
/*
* Merges a group of accumulator instances into one accumulator instance. This method must be
* implemented for unbounded session window grouping aggregates and bounded grouping aggregates.
*
* param: accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* param: iterable an java.lang.Iterable pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, iterable: java.lang.Iterable[ACC]): Unit
If you intend to implement or call functions in Python, please refer to the Python Aggregate Functions documentation for more details.
Table Aggregate Functions #
A user-defined table aggregate function (UDTAGG) maps scalar values of multiple rows to zero, one, or multiple rows (or structured types). The returned record may consist of one or more fields. If an output record consists of only a single field, the structured record can be omitted, and a scalar value can be emitted that will be implicitly wrapped into a row by the runtime.
Similar to an aggregate function, the behavior of a table aggregate is centered around the concept of an accumulator. The accumulator is an intermediate data structure that stores the aggregated values until a final aggregation result is computed.
For each set of rows that needs to be aggregated, the runtime will create an empty accumulator by calling
createAccumulator(). Subsequently, the accumulate(...) method of the function is called for each
input row to update the accumulator. Once all rows have been processed, the emitValue(...) or emitUpdateWithRetract(...)
method of the function is called to compute and return the final result.
The following example illustrates the aggregation process:
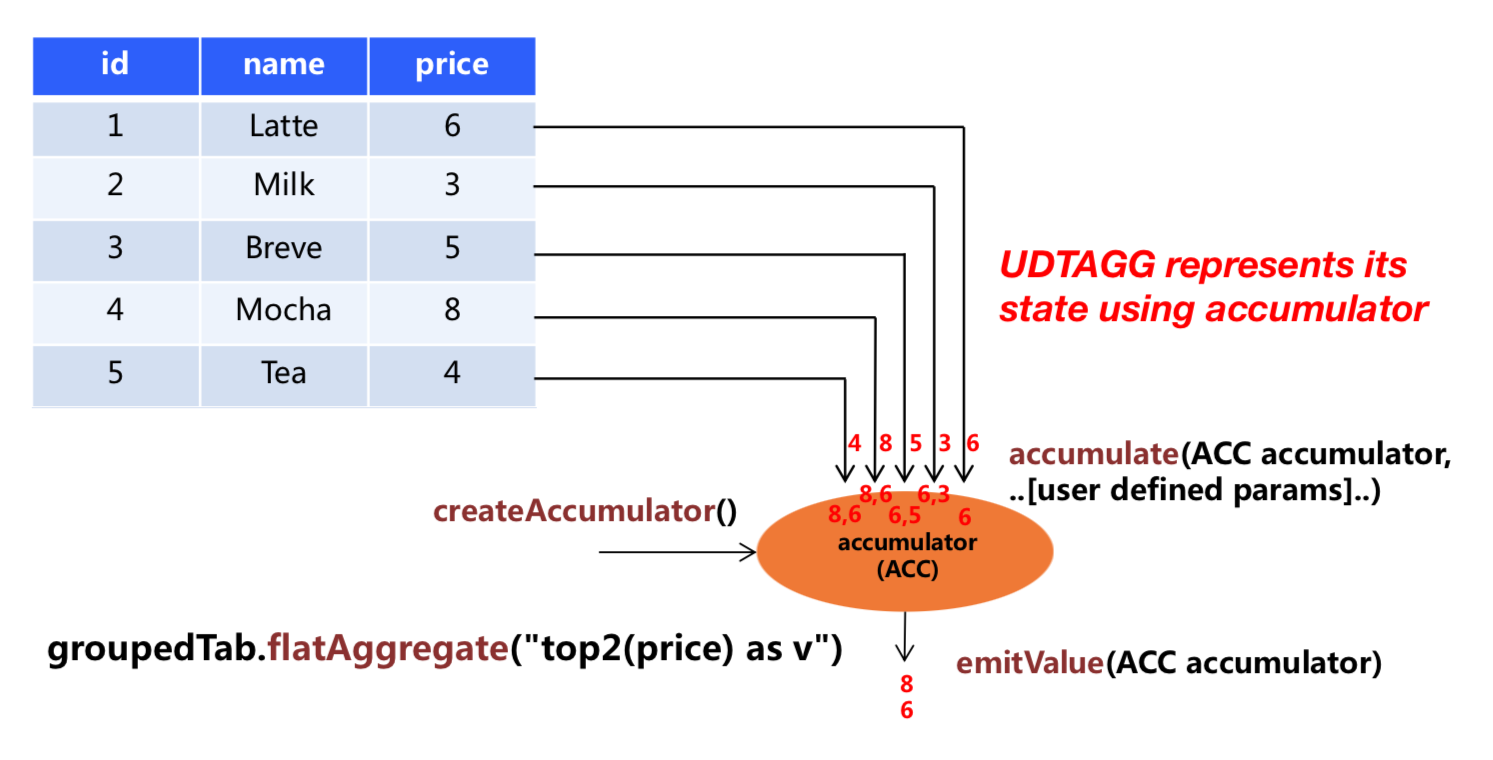
In the example, we assume a table that contains data about beverages. The table consists of three columns (id, name,
and price) and 5 rows. We would like to find the 2 highest prices of all beverages in the table, i.e.,
perform a TOP2() table aggregation. We need to consider each of the 5 rows. The result is a table
with the top 2 values.
In order to define a table aggregate function, one has to extend the base class TableAggregateFunction in
org.apache.flink.table.functions and implement one or more evaluation methods named accumulate(...).
An accumulate method must be declared publicly and not static. Accumulate methods can also be overloaded
by implementing multiple methods named accumulate.
By default, input, accumulator, and output data types are automatically extracted using reflection. This
includes the generic argument ACC of the class for determining an accumulator data type and the generic
argument T for determining an accumulator data type. Input arguments are derived from one or more
accumulate(...) methods. See the Implementation Guide for more details.
If you intend to implement or call functions in Python, please refer to the Python Functions documentation for more details.
The following example shows how to define your own table aggregate function and call it in a query.
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.table.api.*;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.util.Collector;
import static org.apache.flink.table.api.Expressions.*;
// mutable accumulator of structured type for the aggregate function
public static class Top2Accumulator {
public Integer first;
public Integer second;
}
// function that takes (value INT), stores intermediate results in a structured
// type of Top2Accumulator, and returns the result as a structured type of Tuple2<Integer, Integer>
// for value and rank
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accumulator> {
@Override
public Top2Accumulator createAccumulator() {
Top2Accumulator acc = new Top2Accumulator();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accumulator acc, Integer value) {
if (value > acc.first) {
acc.second = acc.first;
acc.first = value;
} else if (value > acc.second) {
acc.second = value;
}
}
public void merge(Top2Accumulator acc, Iterable<Top2Accumulator> it) {
for (Top2Accumulator otherAcc : it) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accumulator acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
TableEnvironment env = TableEnvironment.create(...);
// call function "inline" without registration in Table API
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call(Top2.class, $("value")))
.select($("myField"), $("f0"), $("f1"));
// call function "inline" without registration in Table API
// but use an alias for a better naming of Tuple2's fields
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call(Top2.class, $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
// register function
env.createTemporarySystemFunction("Top2", Top2.class);
// call registered function in Table API
env
.from("MyTable")
.groupBy($("myField"))
.flatAggregate(call("Top2", $("value")).as("value", "rank"))
.select($("myField"), $("value"), $("rank"));
import java.lang.Integer
import org.apache.flink.api.java.tuple.Tuple2
import org.apache.flink.table.api._
import org.apache.flink.table.functions.TableAggregateFunction
import org.apache.flink.util.Collector
// mutable accumulator of structured type for the aggregate function
case class Top2Accumulator(
var first: Integer,
var second: Integer
)
// function that takes (value INT), stores intermediate results in a structured
// type of Top2Accumulator, and returns the result as a structured type of Tuple2[Integer, Integer]
// for value and rank
class Top2 extends TableAggregateFunction[Tuple2[Integer, Integer], Top2Accumulator] {
override def createAccumulator(): Top2Accumulator = {
Top2Accumulator(
Integer.MIN_VALUE,
Integer.MIN_VALUE
)
}
def accumulate(acc: Top2Accumulator, value: Integer): Unit = {
if (value > acc.first) {
acc.second = acc.first
acc.first = value
} else if (value > acc.second) {
acc.second = value
}
}
def merge(acc: Top2Accumulator, it: java.lang.Iterable[Top2Accumulator]) {
val iter = it.iterator()
while (iter.hasNext) {
val otherAcc = iter.next()
accumulate(acc, otherAcc.first)
accumulate(acc, otherAcc.second)
}
}
def emitValue(acc: Top2Accumulator, out: Collector[Tuple2[Integer, Integer]]): Unit = {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1))
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2))
}
}
}
val env = TableEnvironment.create(...)
// call function "inline" without registration in Table API
env
.from("MyTable")
.groupBy($"myField")
.flatAggregate(call(classOf[Top2], $"value"))
.select($"myField", $"f0", $"f1")
// call function "inline" without registration in Table API
// but use an alias for a better naming of Tuple2's fields
env
.from("MyTable")
.groupBy($"myField")
.flatAggregate(call(classOf[Top2], $"value").as("value", "rank"))
.select($"myField", $"value", $"rank")
// register function
env.createTemporarySystemFunction("Top2", classOf[Top2])
// call registered function in Table API
env
.from("MyTable")
.groupBy($"myField")
.flatAggregate(call("Top2", $"value").as("value", "rank"))
.select($"myField", $"value", $"rank")
The accumulate(...) method of our Top2 class takes two inputs. The first one is the accumulator
and the second one is the user-defined input. In order to calculate a result, the accumulator needs to
store the 2 highest values of all the data that has been accumulated. Accumulators are automatically managed
by Flink’s checkpointing mechanism and are restored in case of a failure to ensure exactly-once semantics.
The result values are emitted together with a ranking index.
Mandatory and Optional Methods #
The following methods are mandatory for each TableAggregateFunction:
createAccumulator()accumulate(...)emitValue(...)oremitUpdateWithRetract(...)
Additionally, there are a few methods that can be optionally implemented. While some of these methods
allow the system more efficient query execution, others are mandatory for certain use cases. For instance,
the merge(...) method is mandatory if the aggregation function should be applied in the context of a
session group window (the accumulators of two session windows need to be joined when a row is observed
that “connects” them).
The following methods of TableAggregateFunction are required depending on the use case:
retract(...)is required for aggregations onOVERwindows.merge(...)is required for many bounded aggregations and unbounded session and hop window aggregations.emitValue(...)is required for bounded and window aggregations.
The following methods of TableAggregateFunction are used to improve the performance of streaming jobs:
emitUpdateWithRetract(...)is used to emit values that have been updated under retract mode.
The emitValue(...) method always emits the full data according to the accumulator. In unbounded scenarios,
this may bring performance problems. Take a Top N function as an example. The emitValue(...) would emit
all N values each time. In order to improve the performance, one can implement emitUpdateWithRetract(...) which
outputs data incrementally in retract mode. In other words, once there is an update, the method can retract
old records before sending new, updated ones. The method will be used in preference to the emitValue(...)
method.
If the table aggregate function can only be applied in an OVER window, this can be declared by returning the
requirement FunctionRequirement.OVER_WINDOW_ONLY in getRequirements().
If an accumulator needs to store large amounts of data, org.apache.flink.table.api.dataview.ListView
and org.apache.flink.table.api.dataview.MapView provide advanced features for leveraging Flink’s state
backends in unbounded data scenarios. Please see the docs of the corresponding classes for more information
about this advanced feature.
Since some of methods are optional or can be overloaded, the methods are called by generated code. The base class does not always provide a signature to be overridden by the concrete implementation class. Nevertheless, all mentioned methods must be declared publicly, not static, and named exactly as the names mentioned above to be called.
Detailed documentation for all methods that are not declared in TableAggregateFunction and called by generated
code is given below.
accumulate(...)
/*
* Processes the input values and updates the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An aggregate function
* requires at least one accumulate() method.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
public void accumulate(ACC accumulator, [user defined inputs])
/*
* Processes the input values and updates the provided accumulator instance. The method
* accumulate can be overloaded with different custom types and arguments. An aggregate function
* requires at least one accumulate() method.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
def accumulate(accumulator: ACC, [user defined inputs]): Unit
retract(...)
/*
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This method must be implemented for
* bounded OVER aggregates over unbounded tables.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
public void retract(ACC accumulator, [user defined inputs])
/*
* Retracts the input values from the accumulator instance. The current design assumes the
* inputs are the values that have been previously accumulated. The method retract can be
* overloaded with different custom types and arguments. This method must be implemented for
* bounded OVER aggregates over unbounded tables.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: [user defined inputs] the input value (usually obtained from new arrived data).
*/
def retract(accumulator: ACC, [user defined inputs]): Unit
merge(...)
/*
* Merges a group of accumulator instances into one accumulator instance. This method must be
* implemented for unbounded session window grouping aggregates and bounded grouping aggregates.
*
* param: accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* param: iterable an java.lang.Iterable pointed to a group of accumulators that will be
* merged.
*/
public void merge(ACC accumulator, java.lang.Iterable<ACC> iterable)
/*
* Merges a group of accumulator instances into one accumulator instance. This method must be
* implemented for unbounded session window grouping aggregates and bounded grouping aggregates.
*
* param: accumulator the accumulator which will keep the merged aggregate results. It should
* be noted that the accumulator may contain the previous aggregated
* results. Therefore user should not replace or clean this instance in the
* custom merge method.
* param: iterable an java.lang.Iterable pointed to a group of accumulators that will be
* merged.
*/
def merge(accumulator: ACC, iterable: java.lang.Iterable[ACC]): Unit
emitValue(...)
/*
* Called every time when an aggregation result should be materialized. The returned value could
* be either an early and incomplete result (periodically emitted as data arrives) or the final
* result of the aggregation.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: out the collector used to output data.
*/
public void emitValue(ACC accumulator, org.apache.flink.util.Collector<T> out)
/*
* Called every time when an aggregation result should be materialized. The returned value could
* be either an early and incomplete result (periodically emitted as data arrives) or the final
* result of the aggregation.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: out the collector used to output data.
*/
def emitValue(accumulator: ACC, out: org.apache.flink.util.Collector[T]): Unit
emitUpdateWithRetract(...)
/*
* Called every time when an aggregation result should be materialized. The returned value could
* be either an early and incomplete result (periodically emitted as data arrives) or the final
* result of the aggregation.
*
* Compared to emitValue(), emitUpdateWithRetract() is used to emit values that have been updated. This method
* outputs data incrementally in retraction mode (also known as "update before" and "update after"). Once
* there is an update, we have to retract old records before sending new updated ones. The emitUpdateWithRetract()
* method will be used in preference to the emitValue() method if both methods are defined in the table aggregate
* function, because the method is treated to be more efficient than emitValue as it can output
* values incrementally.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: out the retractable collector used to output data. Use the collect() method
* to output(add) records and use retract method to retract(delete)
* records.
*/
public void emitUpdateWithRetract(ACC accumulator, RetractableCollector<T> out)
/*
* Called every time when an aggregation result should be materialized. The returned value could
* be either an early and incomplete result (periodically emitted as data arrives) or the final
* result of the aggregation.
*
* Compared to emitValue(), emitUpdateWithRetract() is used to emit values that have been updated. This method
* outputs data incrementally in retraction mode (also known as "update before" and "update after"). Once
* there is an update, we have to retract old records before sending new updated ones. The emitUpdateWithRetract()
* method will be used in preference to the emitValue() method if both methods are defined in the table aggregate
* function, because the method is treated to be more efficient than emitValue as it can output
* values incrementally.
*
* param: accumulator the accumulator which contains the current aggregated results
* param: out the retractable collector used to output data. Use the collect() method
* to output(add) records and use retract method to retract(delete)
* records.
*/
def emitUpdateWithRetract(accumulator: ACC, out: RetractableCollector[T]): Unit
Retraction Example #
The following example shows how to use the emitUpdateWithRetract(...) method to emit only incremental
updates. In order to do so, the accumulator keeps both the old and new top 2 values.
If the N of Top N is big, it might be inefficient to keep both the old and new values. One way to
solve this case is to store only the input record in the accumulator in accumulate method and then perform
a calculation in emitUpdateWithRetract.
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.table.functions.TableAggregateFunction;
public static class Top2WithRetractAccumulator {
public Integer first;
public Integer second;
public Integer oldFirst;
public Integer oldSecond;
}
public static class Top2WithRetract
extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2WithRetractAccumulator> {
@Override
public Top2WithRetractAccumulator createAccumulator() {
Top2WithRetractAccumulator acc = new Top2WithRetractAccumulator();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
acc.oldFirst = Integer.MIN_VALUE;
acc.oldSecond = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2WithRetractAccumulator acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void emitUpdateWithRetract(
Top2WithRetractAccumulator acc,
RetractableCollector<Tuple2<Integer, Integer>> out) {
if (!acc.first.equals(acc.oldFirst)) {
// if there is an update, retract the old value then emit a new value
if (acc.oldFirst != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldFirst, 1));
}
out.collect(Tuple2.of(acc.first, 1));
acc.oldFirst = acc.first;
}
if (!acc.second.equals(acc.oldSecond)) {
// if there is an update, retract the old value then emit a new value
if (acc.oldSecond != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldSecond, 2));
}
out.collect(Tuple2.of(acc.second, 2));
acc.oldSecond = acc.second;
}
}
}
import org.apache.flink.api.java.tuple.Tuple2
import org.apache.flink.table.functions.TableAggregateFunction
import org.apache.flink.table.functions.TableAggregateFunction.RetractableCollector
case class Top2WithRetractAccumulator(
var first: Integer,
var second: Integer,
var oldFirst: Integer,
var oldSecond: Integer
)
class Top2WithRetract
extends TableAggregateFunction[Tuple2[Integer, Integer], Top2WithRetractAccumulator] {
override def createAccumulator(): Top2WithRetractAccumulator = {
Top2WithRetractAccumulator(
Integer.MIN_VALUE,
Integer.MIN_VALUE,
Integer.MIN_VALUE,
Integer.MIN_VALUE
)
}
def accumulate(acc: Top2WithRetractAccumulator, value: Integer): Unit = {
if (value > acc.first) {
acc.second = acc.first
acc.first = value
} else if (value > acc.second) {
acc.second = value
}
}
def emitUpdateWithRetract(
acc: Top2WithRetractAccumulator,
out: RetractableCollector[Tuple2[Integer, Integer]])
: Unit = {
if (!acc.first.equals(acc.oldFirst)) {
// if there is an update, retract the old value then emit a new value
if (acc.oldFirst != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldFirst, 1))
}
out.collect(Tuple2.of(acc.first, 1))
acc.oldFirst = acc.first
}
if (!acc.second.equals(acc.oldSecond)) {
// if there is an update, retract the old value then emit a new value
if (acc.oldSecond != Integer.MIN_VALUE) {
out.retract(Tuple2.of(acc.oldSecond, 2))
}
out.collect(Tuple2.of(acc.second, 2))
acc.oldSecond = acc.second
}
}
}