普通自定义函数(UDF) #
用户自定义函数是重要的功能,因为它们极大地扩展了 Python Table API 程序的表达能力。
注意: 要执行 Python 用户自定义函数,客户端和集群端都需要安装 Python 3.6 以上版本(3.6、3.7 或 3.8),并安装 PyFlink。
标量函数(ScalarFunction) #
PyFlink 支持在 Python Table API 程序中使用 Python 标量函数。 如果要定义 Python 标量函数,
可以继承 pyflink.table.udf 中的基类 ScalarFunction,并实现 eval 方法。
Python 标量函数的行为由名为 eval 的方法定义,eval 方法支持可变长参数,例如 eval(* args)。
以下示例显示了如何定义自己的 Python 哈希函数、如何在 TableEnvironment 中注册它以及如何在作业中使用它。
from pyflink.table.expressions import call, col
from pyflink.table import DataTypes, TableEnvironment, EnvironmentSettings
from pyflink.table.udf import ScalarFunction, udf
class HashCode(ScalarFunction):
def __init__(self):
self.factor = 12
def eval(self, s):
return hash(s) * self.factor
settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(settings)
hash_code = udf(HashCode(), result_type=DataTypes.BIGINT())
# 在 Python Table API 中使用 Python 自定义函数
my_table.select(col("string"), col("bigint"), hash_code(col("bigint")), call(hash_code, col("bigint")))
# 在 SQL API 中使用 Python 自定义函数
table_env.create_temporary_function("hash_code", udf(HashCode(), result_type=DataTypes.BIGINT()))
table_env.sql_query("SELECT string, bigint, hash_code(bigint) FROM MyTable")
除此之外,还支持在Python Table API程序中使用 Java / Scala 标量函数。
'''
Java code:
// Java 类必须具有公共的无参数构造函数,并且可以在当前的Java类加载器中可以加载到。
public class HashCode extends ScalarFunction {
private int factor = 12;
public int eval(String s) {
return s.hashCode() * factor;
}
}
'''
from pyflink.table.expressions import call, col
from pyflink.table import TableEnvironment, EnvironmentSettings
settings = EnvironmentSettings.in_batch_mode()
table_env = TableEnvironment.create(settings)
# 注册 Java 函数
table_env.create_java_temporary_function("hash_code", "my.java.function.HashCode")
# 在 Python Table API 中使用 Java 函数
my_table.select(call('hash_code', col("string")))
# 在 SQL API 中使用 Java 函数
table_env.sql_query("SELECT string, bigint, hash_code(string) FROM MyTable")
除了扩展基类 ScalarFunction 之外,还支持多种方式来定义 Python 标量函数。
以下示例显示了多种定义 Python 标量函数的方式。该函数需要两个类型为 bigint 的参数作为输入参数,并返回它们的总和作为结果。
# 方式一:扩展基类 calarFunction
class Add(ScalarFunction):
def eval(self, i, j):
return i + j
add = udf(Add(), result_type=DataTypes.BIGINT())
# 方式二:普通 Python 函数
@udf(result_type=DataTypes.BIGINT())
def add(i, j):
return i + j
# 方式三:lambda 函数
add = udf(lambda i, j: i + j, result_type=DataTypes.BIGINT())
# 方式四:callable 函数
class CallableAdd(object):
def __call__(self, i, j):
return i + j
add = udf(CallableAdd(), result_type=DataTypes.BIGINT())
# 方式五:partial 函数
def partial_add(i, j, k):
return i + j + k
add = udf(functools.partial(partial_add, k=1), result_type=DataTypes.BIGINT())
# 注册 Python 自定义函数
table_env.create_temporary_function("add", add)
# 在 Python Table API 中使用 Python 自定义函数
my_table.select(call('add', col('a'), col('b')))
# 也可以在 Python Table API 中直接使用 Python 自定义函数
my_table.select(add(col('a'), col('b')))
表值函数(TableFunction) #
与 Python 用户自定义标量函数类似,Python 用户自定义表值函数以零个,一个或者多个列作为输入参数。但是,与标量函数不同的是,表值函数可以返回 任意数量的行作为输出而不是单个值。Python 用户自定义表值函数的返回类型可以是 Iterable,Iterator 或 generator 类型。
以下示例说明了如何定义自己的 Python 自定义表值函数,将其注册到 TableEnvironment 中,并在作业中使用它。
from pyflink.table.expressions import col
from pyflink.table import DataTypes, TableEnvironment, EnvironmentSettings
from pyflink.table.udf import TableFunction, udtf
class Split(TableFunction):
def eval(self, string):
for s in string.split(" "):
yield s, len(s)
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
my_table = ... # type: Table, table schema: [a: String]
# 注册 Python 表值函数
split = udtf(Split(), result_types=[DataTypes.STRING(), DataTypes.INT()])
# 在 Python Table API 中使用 Python 表值函数
my_table.join_lateral(split(col("a")).alias("word", "length"))
my_table.left_outer_join_lateral(split(col("a")).alias("word", "length"))
# 在 SQL API 中使用 Python 表值函数
table_env.create_temporary_function("split", udtf(Split(), result_types=[DataTypes.STRING(), DataTypes.INT()]))
table_env.sql_query("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
table_env.sql_query("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")
除此之外,还支持在 Python Table API 程序中使用 Java / Scala 表值函数。
'''
Java code:
// 类型"Tuple2 <String,Integer>"代表,表值函数的输出类型为(String,Integer)。
// Java类必须具有公共的无参数构造函数,并且可以在当前的Java类加载器中加载到。
public class Split extends TableFunction<Tuple2<String, Integer>> {
private String separator = " ";
public void eval(String str) {
for (String s : str.split(separator)) {
// use collect(...) to emit a row
collect(new Tuple2<String, Integer>(s, s.length()));
}
}
}
'''
from pyflink.table.expressions import call, col
from pyflink.table import TableEnvironment, EnvironmentSettings
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
my_table = ... # type: Table, table schema: [a: String]
# 注册 Java 自定义函数。
table_env.create_java_temporary_function("split", "my.java.function.Split")
# 在 Python Table API 中使用表值函数。 "alias"指定表的字段名称。
my_table.join_lateral(call('split', col('a')).alias("word", "length")).select(col('a'), col('word'), col('length'))
my_table.left_outer_join_lateral(call('split', col('a')).alias("word", "length")).select(col('a'), col('word'), col('length'))
# 注册 Python 函数。
# 在SQL中将table函数与LATERAL和TABLE关键字一起使用。
# CROSS JOIN表值函数(等效于Table API中的"join")。
table_env.sql_query("SELECT a, word, length FROM MyTable, LATERAL TABLE(split(a)) as T(word, length)")
# LEFT JOIN一个表值函数(等同于Table API中的"left_outer_join")。
table_env.sql_query("SELECT a, word, length FROM MyTable LEFT JOIN LATERAL TABLE(split(a)) as T(word, length) ON TRUE")
像 Python 标量函数一样,您可以使用上述五种方式来定义 Python 表值函数。
注意 唯一的区别是,Python 表值函数的返回类型必须是 iterable(可迭代子类), iterator(迭代器) or generator(生成器)。
# 方式一:生成器函数
@udtf(result_types=DataTypes.BIGINT())
def generator_func(x):
yield 1
yield 2
# 方式二:返回迭代器
@udtf(result_types=DataTypes.BIGINT())
def iterator_func(x):
return range(5)
# 方式三:返回可迭代子类
@udtf(result_types=DataTypes.BIGINT())
def iterable_func(x):
result = [1, 2, 3]
return result
聚合函数(AggregateFunction) #
A user-defined aggregate function (UDAGG) maps scalar values of multiple rows to a new scalar value.
NOTE: Currently the general user-defined aggregate function is only supported in the GroupBy aggregation and Group Window Aggregation in streaming mode. For batch mode, it’s currently not supported and it is recommended to use the Vectorized Aggregate Functions.
The behavior of an aggregate function is centered around the concept of an accumulator. The accumulator is an intermediate data structure that stores the aggregated values until a final aggregation result is computed.
For each set of rows that need to be aggregated, the runtime will create an empty accumulator by calling
create_accumulator(). Subsequently, the accumulate(...) method of the aggregate function will be called for each input
row to update the accumulator. Currently after each row has been processed, the get_value(...) method of the
aggregate function will be called to compute the aggregated result.
The following example illustrates the aggregation process:
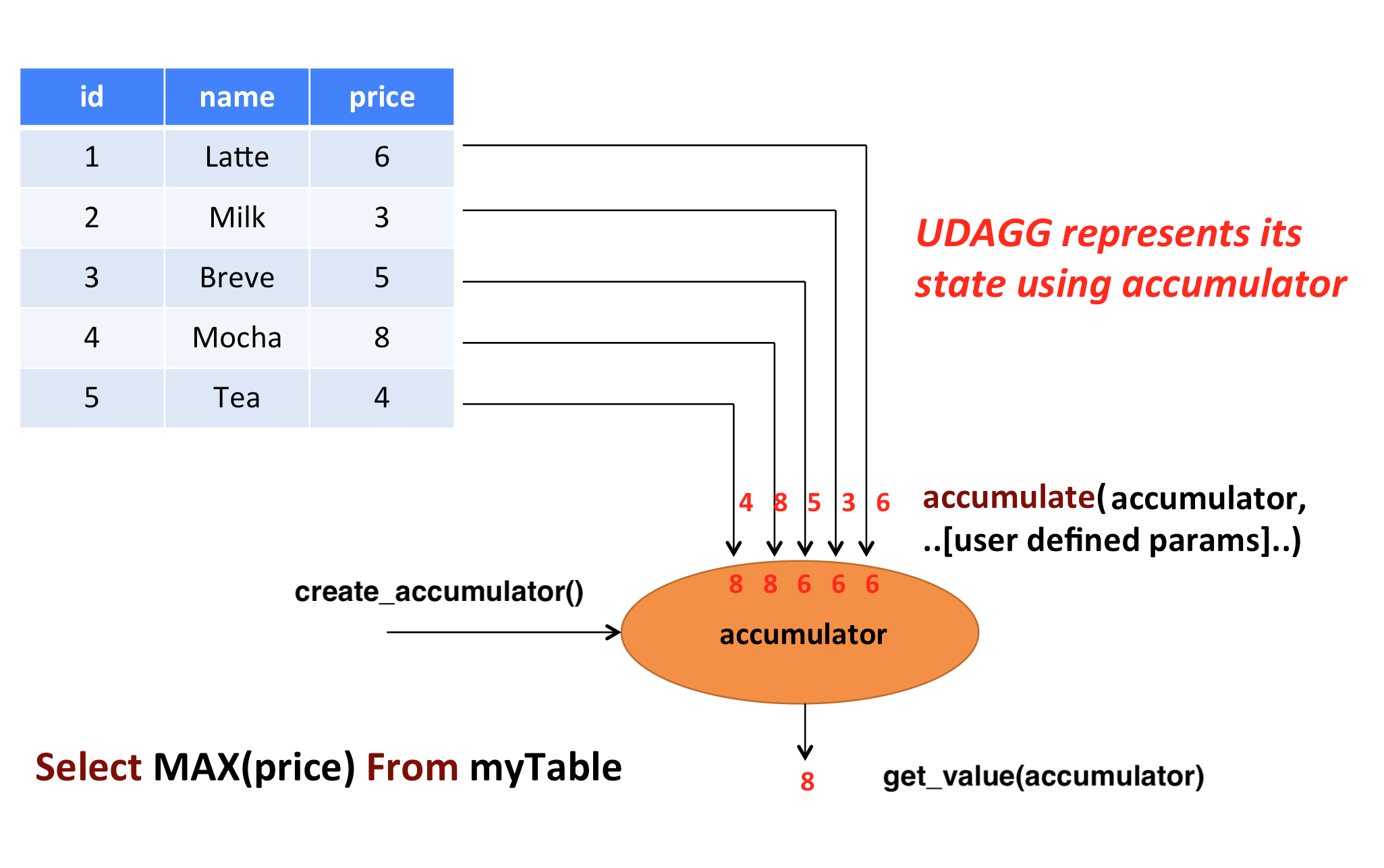
In the above example, we assume a table that contains data about beverages. The table consists of three columns (id, name,
and price) and 5 rows. We would like to find the highest price of all beverages in the table, i.e., perform
a max() aggregation.
In order to define an aggregate function, one has to extend the base class AggregateFunction in
pyflink.table and implement the evaluation method named accumulate(...).
The result type and accumulator type of the aggregate function can be specified by one of the following two approaches:
- Implement the method named
get_result_type()andget_accumulator_type(). - Wrap the function instance with the decorator
udafinpyflink.table.udfand specify the parametersresult_typeandaccumulator_type.
The following example shows how to define your own aggregate function and call it in a query.
from pyflink.common import Row
from pyflink.table import AggregateFunction, DataTypes, TableEnvironment, EnvironmentSettings
from pyflink.table.expressions import call
from pyflink.table.udf import udaf
from pyflink.table.expressions import col, lit
from pyflink.table.window import Tumble
class WeightedAvg(AggregateFunction):
def create_accumulator(self):
# Row(sum, count)
return Row(0, 0)
def get_value(self, accumulator):
if accumulator[1] == 0:
return None
else:
return accumulator[0] / accumulator[1]
def accumulate(self, accumulator, value, weight):
accumulator[0] += value * weight
accumulator[1] += weight
def retract(self, accumulator, value, weight):
accumulator[0] -= value * weight
accumulator[1] -= weight
def get_result_type(self):
return DataTypes.BIGINT()
def get_accumulator_type(self):
return DataTypes.ROW([
DataTypes.FIELD("f0", DataTypes.BIGINT()),
DataTypes.FIELD("f1", DataTypes.BIGINT())])
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# the result type and accumulator type can also be specified in the udaf decorator:
# weighted_avg = udaf(WeightedAvg(), result_type=DataTypes.BIGINT(), accumulator_type=...)
weighted_avg = udaf(WeightedAvg())
t = table_env.from_elements([(1, 2, "Lee"),
(3, 4, "Jay"),
(5, 6, "Jay"),
(7, 8, "Lee")]).alias("value", "count", "name")
# call function "inline" without registration in Table API
result = t.group_by(col("name")).select(weighted_avg(col("value"), col("count")).alias("avg")).execute()
result.print()
# register function
table_env.create_temporary_function("weighted_avg", WeightedAvg())
# call registered function in Table API
result = t.group_by(col("name")).select(call("weighted_avg", col("value"), col("count")).alias("avg")).execute()
result.print()
# register table
table_env.create_temporary_view("source", t)
# call registered function in SQL
result = table_env.sql_query(
"SELECT weighted_avg(`value`, `count`) AS avg FROM source GROUP BY name").execute()
result.print()
# use the general Python aggregate function in GroupBy Window Aggregation
tumble_window = Tumble.over(lit(1).hours) \
.on(col("rowtime")) \
.alias("w")
result = t.window(tumble_window) \
.group_by(col('w'), col('name')) \
.select(col('w').start, col('w').end, weighted_avg(col('value'), col('count'))) \
.execute()
result.print()
The accumulate(...) method of our WeightedAvg class takes three input arguments. The first one is the accumulator
and the other two are user-defined inputs. In order to calculate a weighted average value, the accumulator
needs to store the weighted sum and count of all the data that have already been accumulated. In our example, we
use a Row object as the accumulator. Accumulators will be managed
by Flink’s checkpointing mechanism and are restored in case of failover to ensure exactly-once semantics.
Mandatory and Optional Methods #
The following methods are mandatory for each AggregateFunction:
create_accumulator()accumulate(...)get_value(...)
The following methods of AggregateFunction are required depending on the use case:
retract(...)is required when there are operations that could generate retraction messages before the current aggregation operation, e.g. group aggregate, outer join.
This method is optional, but it is strongly recommended to be implemented to ensure the UDAF can be used in any use case.merge(...)is required for session window ang hop window aggregations.get_result_type()andget_accumulator_type()is required if the result type and accumulator type would not be specified in theudafdecorator.
ListView and MapView #
If an accumulator needs to store large amounts of data, pyflink.table.ListView and pyflink.table.MapView
could be used instead of list and dict. These two data structures provide the similar functionalities as list and dict,
however usually having better performance by leveraging Flink’s state backend to eliminate unnecessary state access.
You can use them by declaring DataTypes.LIST_VIEW(...) and DataTypes.MAP_VIEW(...) in the accumulator type, e.g.:
from pyflink.table import ListView
class ListViewConcatAggregateFunction(AggregateFunction):
def get_value(self, accumulator):
# the ListView is iterable
return accumulator[1].join(accumulator[0])
def create_accumulator(self):
return Row(ListView(), '')
def accumulate(self, accumulator, *args):
accumulator[1] = args[1]
# the ListView support add, clear and iterate operations.
accumulator[0].add(args[0])
def get_accumulator_type(self):
return DataTypes.ROW([
# declare the first column of the accumulator as a string ListView.
DataTypes.FIELD("f0", DataTypes.LIST_VIEW(DataTypes.STRING())),
DataTypes.FIELD("f1", DataTypes.BIGINT())])
def get_result_type(self):
return DataTypes.STRING()
Currently, there are 2 limitations to use the ListView and MapView:
- The accumulator must be a
Row. - The
ListViewandMapViewmust be the first level children of theRowaccumulator.
Please refer to the documentation of the corresponding classes for more information about this advanced feature.
NOTE: For reducing the data transmission cost between Python UDF worker and Java process caused by accessing the data in Flink states(e.g. accumulators and data views),
there is a cached layer between the raw state handler and the Python state backend. You can adjust the values of these configuration options to change the behavior of the cache layer for best performance:
python.state.cache-size, python.map-state.read-cache-size, python.map-state.write-cache-size, python.map-state.iterate-response-batch-size.
For more details please refer to the Python Configuration Documentation.
Table Aggregate Functions #
A user-defined table aggregate function (UDTAGG) maps scalar values of multiple rows to zero, one, or multiple rows (or structured types). The returned record may consist of one or more fields. If an output record consists of only a single field, the structured record can be omitted, and a scalar value can be emitted that will be implicitly wrapped into a row by the runtime.
NOTE: Currently the general user-defined table aggregate function is only supported in the GroupBy aggregation in streaming mode.
Similar to an aggregate function, the behavior of a table aggregate is centered around the concept of an accumulator. The accumulator is an intermediate data structure that stores the aggregated values until a final aggregation result is computed.
For each set of rows that needs to be aggregated, the runtime will create an empty accumulator by calling
create_accumulator(). Subsequently, the accumulate(...) method of the function is called for each
input row to update the accumulator. Once all rows have been processed, the emit_value(...) method of
the function is called to compute and return the final result.
The following example illustrates the aggregation process:
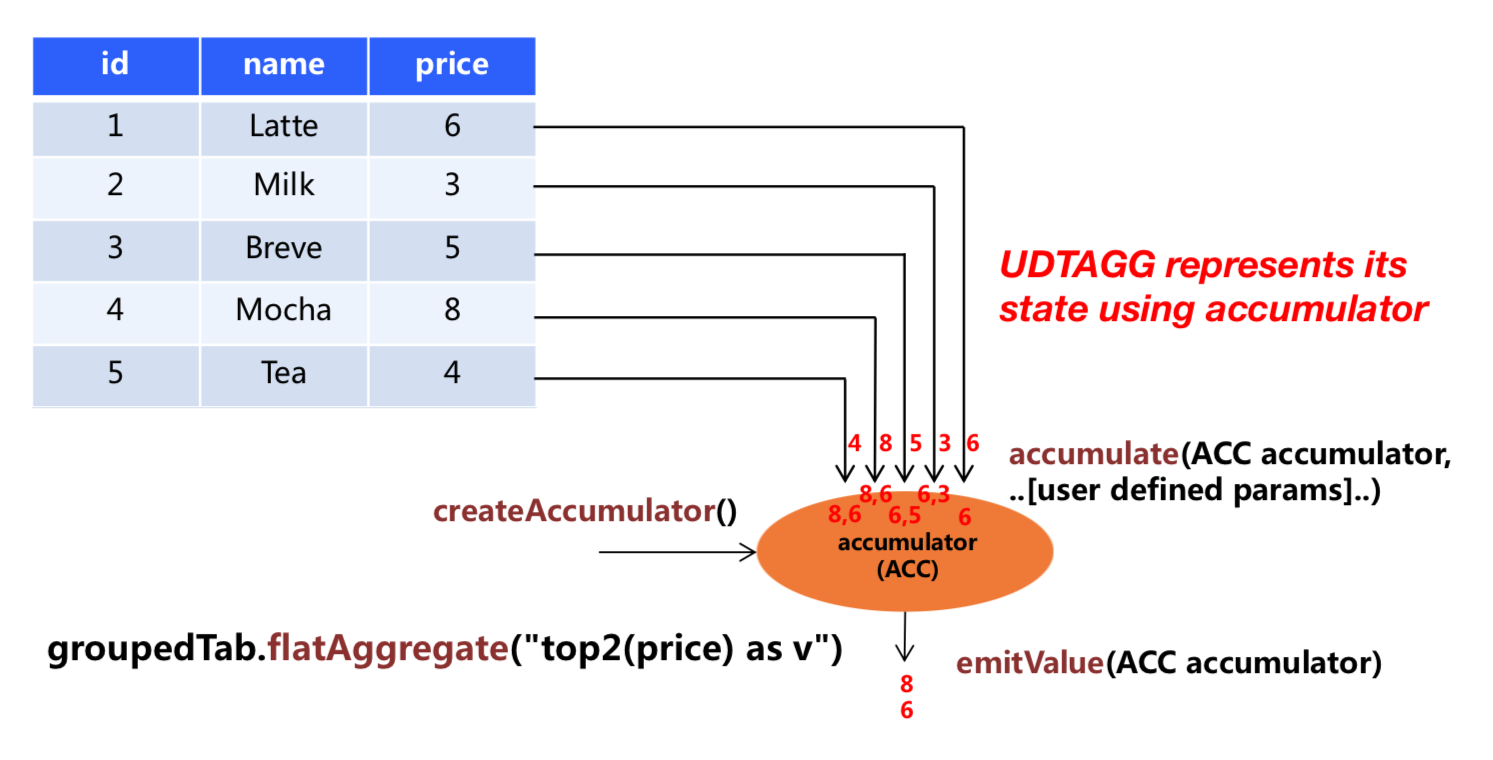
In the example, we assume a table that contains data about beverages. The table consists of three columns (id, name,
and price) and 5 rows. We would like to find the 2 highest prices of all beverages in the table, i.e.,
perform a TOP2() table aggregation. We need to consider each of the 5 rows. The result is a table
with the top 2 values.
In order to define a table aggregate function, one has to extend the base class TableAggregateFunction in
pyflink.table and implement one or more evaluation methods named accumulate(...).
The result type and accumulator type of the aggregate function can be specified by one of the following two approaches:
- Implement the method named
get_result_type()andget_accumulator_type(). - Wrap the function instance with the decorator
udtafinpyflink.table.udfand specify the parametersresult_typeandaccumulator_type.
The following example shows how to define your own aggregate function and call it in a query.
from pyflink.common import Row
from pyflink.table import DataTypes, TableEnvironment, EnvironmentSettings
from pyflink.table.expressions import col
from pyflink.table.udf import udtaf, TableAggregateFunction
class Top2(TableAggregateFunction):
def emit_value(self, accumulator):
yield Row(accumulator[0])
yield Row(accumulator[1])
def create_accumulator(self):
return [None, None]
def accumulate(self, accumulator, row):
if row[0] is not None:
if accumulator[0] is None or row[0] > accumulator[0]:
accumulator[1] = accumulator[0]
accumulator[0] = row[0]
elif accumulator[1] is None or row[0] > accumulator[1]:
accumulator[1] = row[0]
def get_accumulator_type(self):
return DataTypes.ARRAY(DataTypes.BIGINT())
def get_result_type(self):
return DataTypes.ROW(
[DataTypes.FIELD("a", DataTypes.BIGINT())])
env_settings = EnvironmentSettings.in_streaming_mode()
table_env = TableEnvironment.create(env_settings)
# the result type and accumulator type can also be specified in the udtaf decorator:
# top2 = udtaf(Top2(), result_type=DataTypes.ROW([DataTypes.FIELD("a", DataTypes.BIGINT())]), accumulator_type=DataTypes.ARRAY(DataTypes.BIGINT()))
top2 = udtaf(Top2())
t = table_env.from_elements([(1, 'Hi', 'Hello'),
(3, 'Hi', 'hi'),
(5, 'Hi2', 'hi'),
(7, 'Hi', 'Hello'),
(2, 'Hi', 'Hello')],
['a', 'b', 'c'])
# call function "inline" without registration in Table API
t.group_by(col('b')).flat_aggregate(top2).select(col('*')).execute().print()
# the result is:
+----+--------------------------------+----------------------+
| op | b | a |
+----+--------------------------------+----------------------+
| +I | Hi | 1 |
| +I | Hi | <NULL> |
| -D | Hi | 1 |
| -D | Hi | <NULL> |
| +I | Hi | 7 |
| +I | Hi | 3 |
| +I | Hi2 | 5 |
| +I | Hi2 | <NULL> |
+----+--------------------------------+----------------------+
The accumulate(...) method of our Top2 class takes two inputs. The first one is the accumulator
and the second one is the user-defined input. In order to calculate a result, the accumulator needs to
store the 2 highest values of all the data that has been accumulated. Accumulators are automatically managed
by Flink’s checkpointing mechanism and are restored in case of a failure to ensure exactly-once semantics.
The result values are emitted together with a ranking index.
Mandatory and Optional Methods #
The following methods are mandatory for each TableAggregateFunction:
create_accumulator()accumulate(...)emit_value(...)
The following methods of TableAggregateFunction are required depending on the use case:
retract(...)is required when there are operations that could generate retraction messages before the current aggregation operation, e.g. group aggregate, outer join.
This method is optional, but it is strongly recommended to be implemented to ensure the UDTAF can be used in any use case.get_result_type()andget_accumulator_type()is required if the result type and accumulator type would not be specified in theudtafdecorator.
ListView and MapView #
Similar to Aggregation function, we can also use ListView and MapView in Table Aggregate Function.
from pyflink.common import Row
from pyflink.table import ListView
from pyflink.table.types import DataTypes
from pyflink.table.udf import TableAggregateFunction
class ListViewConcatTableAggregateFunction(TableAggregateFunction):
def emit_value(self, accumulator):
result = accumulator[1].join(accumulator[0])
yield Row(result)
yield Row(result)
def create_accumulator(self):
return Row(ListView(), '')
def accumulate(self, accumulator, *args):
accumulator[1] = args[1]
accumulator[0].add(args[0])
def get_accumulator_type(self):
return DataTypes.ROW([
DataTypes.FIELD("f0", DataTypes.LIST_VIEW(DataTypes.STRING())),
DataTypes.FIELD("f1", DataTypes.BIGINT())])
def get_result_type(self):
return DataTypes.ROW([DataTypes.FIELD("a", DataTypes.STRING())])