High Availability #
JobManager High Availability (HA) hardens a Flink cluster against JobManager failures. This feature ensures that a Flink cluster will always continue executing your submitted jobs.
JobManager High Availability #
The JobManager coordinates every Flink deployment. It is responsible for both scheduling and resource management.
By default, there is a single JobManager instance per Flink cluster. This creates a single point of failure (SPOF): if the JobManager crashes, no new programs can be submitted and running programs fail.
With JobManager High Availability, you can recover from JobManager failures and thereby eliminate the SPOF. You can configure high availability for every cluster deployment. See the list of available high availability services for more information.
How to make a cluster highly available #
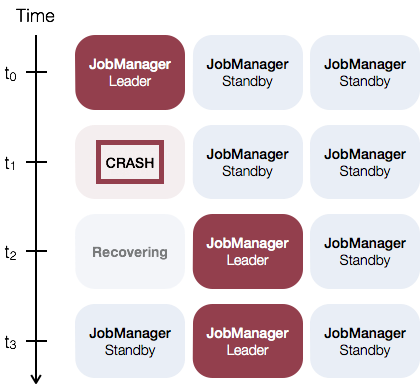
The general idea of JobManager High Availability is that there is a single leading JobManager at any time and multiple standby JobManagers to take over leadership in case the leader fails. This guarantees that there is no single point of failure and programs can make progress as soon as a standby JobManager has taken leadership.
As an example, consider the following setup with three JobManager instances:
Flink’s high availability services encapsulate the required services to make everything work:
- Leader election: Selecting a single leader out of a pool of
ncandidates - Service discovery: Retrieving the address of the current leader
- State persistence: Persisting state which is required for the successor to resume the job execution (JobGraphs, user code jars, completed checkpoints)
High Availability Services #
Flink ships with two high availability service implementations:
-
ZooKeeper: ZooKeeper HA services can be used with every Flink cluster deployment. They require a running ZooKeeper quorum.
-
Kubernetes: Kubernetes HA services only work when running on Kubernetes.
High Availability data lifecycle #
In order to recover submitted jobs, Flink persists metadata and the job artifacts. The HA data will be kept until the respective job either succeeds, is cancelled or fails terminally. Once this happens, all the HA data, including the metadata stored in the HA services, will be deleted.
JobResultStore #
The JobResultStore is used to archive the final result of a job that reached a globally-terminal state (i.e. finished, cancelled or failed). The data is stored on a file system (see job-result-store.storage-path). Entries in this store are marked as dirty as long as the corresponding job wasn’t cleaned up properly (artifacts are found in the job’s subfolder in high-availability.storageDir).
Dirty entries are subject to cleanup, i.e. the corresponding job is either cleaned up by Flink at the moment or will be picked up for cleanup as part of a recovery. The entries will be deleted as soon as the cleanup succeeds. Check the JobResultStore configuration parameters under HA configuration options for further details on how to adapt the behavior.