Autoscaler #
The operator provides a job autoscaler functionality that collects various metrics from running Flink jobs and automatically scales individual job vertexes (chained operator groups) to eliminate backpressure and satisfy the utilization target set by the user. By adjusting parallelism on a job vertex level (in contrast to job parallelism) we can efficiently autoscale complex and heterogeneous streaming applications.
Key benefits to the user:
- Better cluster resource utilization and lower operating costs
- Automatic parallelism tuning for even complex streaming pipelines
- Automatic adaptation to changing load patterns
- Detailed utilization metrics for performance debugging
Overview #
The autoscaler relies on the metrics exposed by the Flink metric system for the individual tasks. The metrics are queried directly from the Flink job.
Collected metrics:
- Backlog information at each source
- Incoming data rate at the sources (e.g. records/sec written into the Kafka topic)
- Number of records processed per second in each job vertex
- Busy time per second of each job vertex (current utilization)
Please note that we are not using any container memory / CPU utilization metrics directly here. High utilization will be reflected in the processing rate and busy time metrics of the individual job vertexes.
The algorithm starts from the sources and recursively computes the required processing capacity (target data rate) for each operator in the pipeline. At the source vertices, target data rate is equal to incoming data rate (from the Kafka topic).
For downstream operators we compute the target data rate as the sum of the input (upstream) operators output data rate along the given edge in the processing graph.
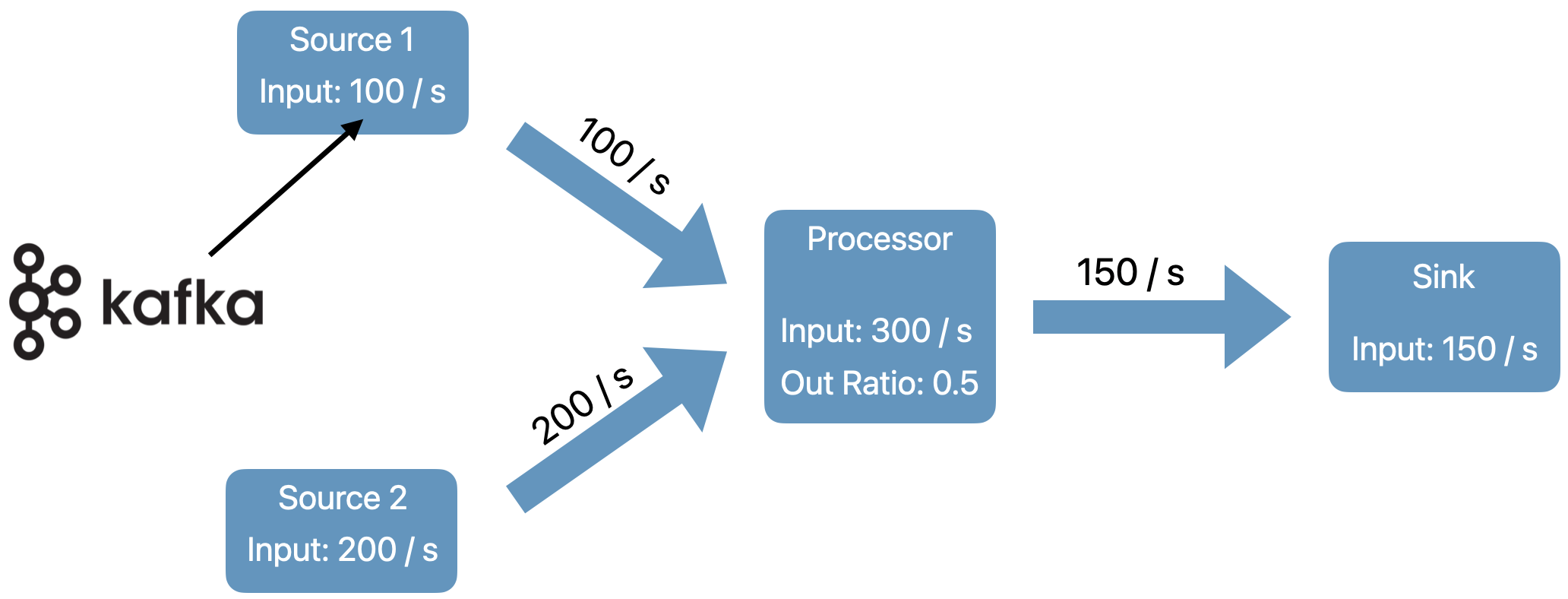
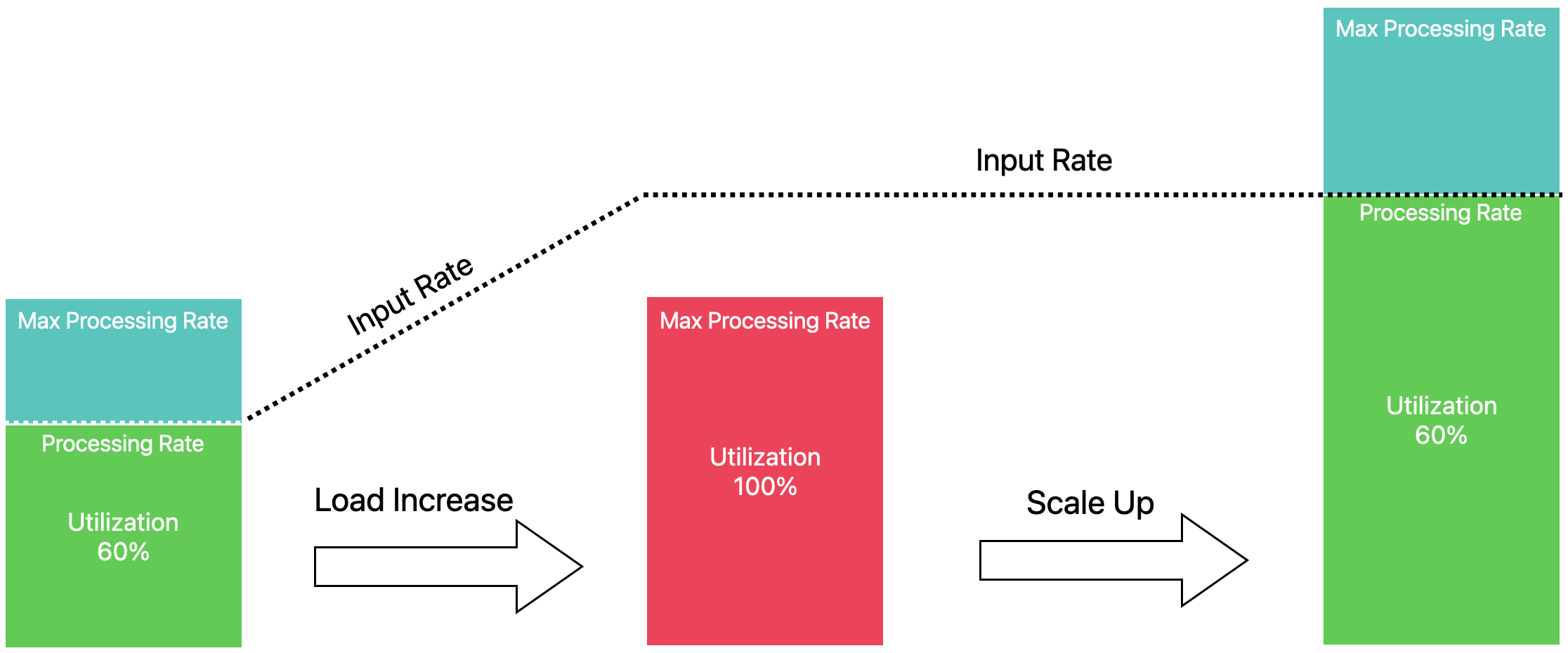
Users configure the target utilization percentage of the operators in the pipeline, e.g. keep the all operators between 60% - 80% busy. The autoscaler then finds a parallelism configuration such that the output rates of all operators match the input rates of all their downstream operators at the targeted utilization.
In this example we see an upscale operation:
Similarly as load decreases, the autoscaler adjusts individual operator parallelism levels to match the current rate over time.
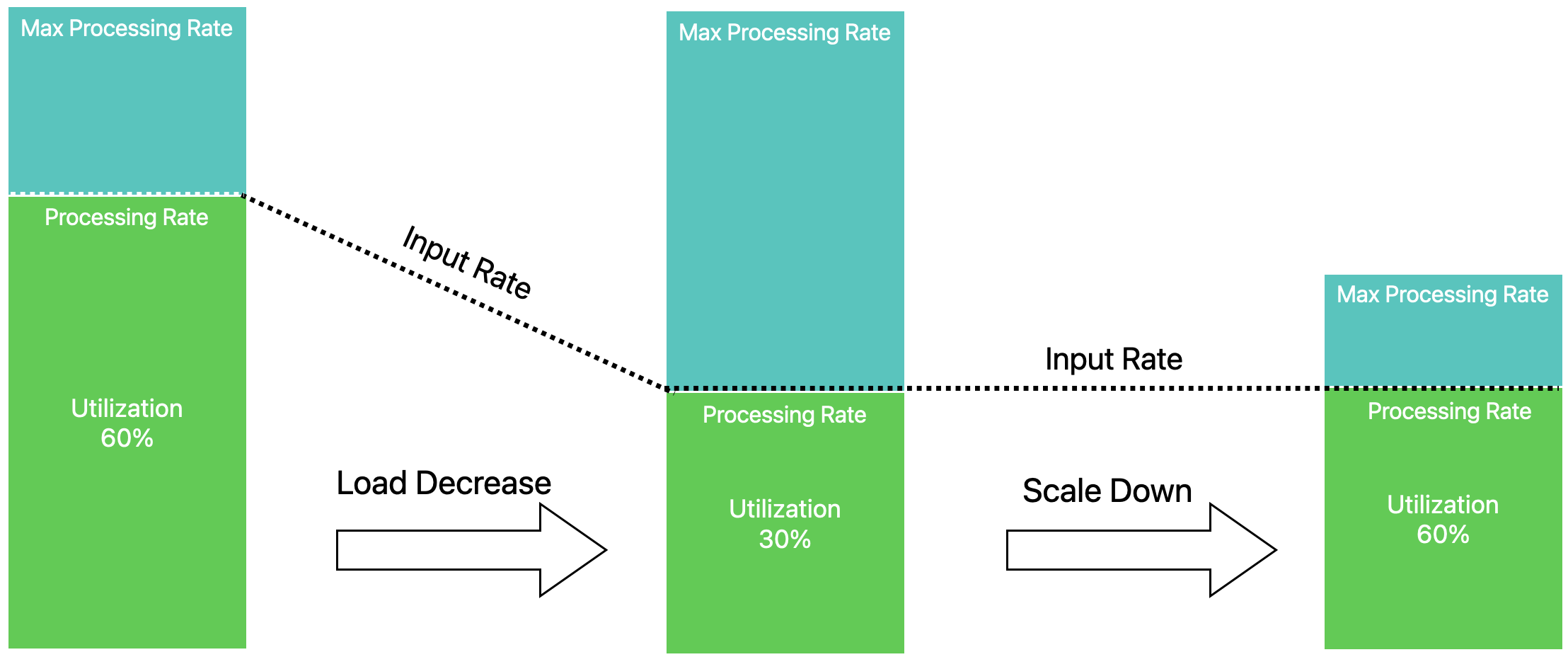
The autoscaler approach is based on Three steps is all you need: fast, accurate, automatic scaling decisions for distributed streaming dataflows by Kalavri et al.
Executing rescaling operations #
By default the autoscaler uses the built in job upgrade mechanism from the operator to perform the rescaling as detailed in Job Management and Stateful upgrades.
Flink 1.18 and in-place scaling support #
The upcoming Flink 1.18 release brings very significant improvements to the speed of scaling operations through the new resource requirements rest endpoint. This allows the autoscaler to scale vertices in-place without performing a full job upgrade cycle.
To try this experimental feature, please use the currently available Flink 1.18 snapshot base image to build you application docker image.
Furthermore make sure you set Flink version to v1_18 in your FlinkDeployment yaml and enable the adaptive scheduler which is required for this feature.
jobmanager.scheduler: adaptive
Job Requirements and Limitations #
Requirements #
The autoscaler currently only works with Flink 1.17 and later flink images, or after backporting the following fixes to your 1.15/1.16 Flink images:
- Job vertex parallelism overrides (must have)
- Support timespan for busyTime metrics (good to have)
Limitations #
By default the autoscaler can work for all job vertices in the processing graph.
However source scaling requires that the sources:
- Use the new Source API that exposes the busy time metric (must have, most common connectors already do)
- Expose the standardized connector metrics for accessing backlog information (good to have, extra capacity will be added for catching up with backlog)
In the current state the autoscaler works best with Kafka sources, as they expose all the standardized metrics. It also comes with some additional benefits when using Kafka such as automatically detecting and limiting source max parallelism to the number of Kafka partitions.
Configuration guide #
Depending on your environment and job characteristics there are a few very important configurations that will affect how well the autoscaler works.
Key configuration areas:
- Job and per operator max parallelism
- Stabilization and metrics collection intervals
- Target utilization and flexible boundaries
- Target catch-up duration and restart time
The defaults might work reasonably well for many applications, but some tuning may be required in this early stage of the autoscaler module.
The autoscaler also supports a passive/metrics-only mode where it only collects and evaluates scaling related performance metrics but does not trigger any job upgrades. This can be used to gain confidence in the module without any impact on the running applications.
To disable scaling actions, set:
job.autoscaler.scaling.enabled: "false"
Job and per operator max parallelism #
When computing the scaled parallelism, the autoscaler always considers the max parallelism settings for each job vertex to ensure that it doesn’t introduce unnecessary data skew. The computed parallelism will always be a divisor of the max parallelism number.
To ensure flexible scaling it is therefore recommended to choose max parallelism settings that have a lot of divisors instead of relying on the Flink provided defaults.
You can then use the pipeline.max-parallelism to configure this for your pipeline.
Some good numbers for max-parallelism are: 120, 180, 240, 360, 720 etc.
It is also possible to set maxParallelism on a per operator level, which can be useful if we want to avoid scaling some sources/sinks beyond a certain number.
Stabilization and metrics collection intervals #
The autoscaler always looks at average metrics in the collection time window defined by job.autoscaler.metrics.window.
The size of this window determines how small fluctuations will affect the autoscaler. The larger the window, the more smoothing and stability we get, but we may be slower to react to sudden load changes.
We suggest you experiment with setting this anywhere between 3-60 minutes for best experience.
To allow jobs to stabilize after recovery users can configure a stabilization window by setting job.autoscaler.stabilization.interval.
During this time period no metrics will be collected and no scaling actions will be taken.
Target utilization and flexible boundaries #
In order to provide stable job performance and some buffer for load fluctuations, the autoscaler allows users to set a target utilization level for the job (job.autoscaler.target.utilization).
A target of 0.6 means we are targeting 60% utilization/load for the job vertexes.
In general, it’s not recommended to set target utilization close to 100% as performance usually degrades as we reach capacity limits in most real world systems.
In addition to the utilization target we can set a utilization boundary, that serves as extra buffer to avoid immediate scaling on load fluctuations.
Setting job.autoscaler.target.utilization.boundary: "0.2" means that we allow 20% deviation from the target utilization before triggering a scaling action.
Target catch-up duration and restart time #
When taking scaling decisions the operator need to account for the extra capacity required to catch up the backlog created during scaling operations. The amount of extra capacity is determined automatically by the following 2 configs:
job.autoscaler.restart.time: Time it usually takes to restart the applicationjob.autoscaler.catch-up.duration: Time to job is expected to catch up after scaling
In the future the autoscaler may be able to automatically determine the restart time, but the target catch-up duration depends on the users SLO.
By lowering the catch-up duration the autoscaler will have to reserve more extra capacity for the scaling actions. We suggest setting this based on your actual objective, such us 10,30,60 minutes etc.
Basic configuration example #
...
flinkVersion: v1_17
flinkConfiguration:
job.autoscaler.enabled: "true"
job.autoscaler.stabilization.interval: 1m
job.autoscaler.metrics.window: 5m
job.autoscaler.target.utilization: "0.6"
job.autoscaler.target.utilization.boundary: "0.2"
job.autoscaler.restart.time: 2m
job.autoscaler.catch-up.duration: 5m
pipeline.max-parallelism: "720"
Advanced config parameters #
The autoscaler also exposes various more advanced config parameters that affect scaling actions:
- Minimum time before scaling down after scaling up a vertex
- Maximum parallelism change when scaling down
- Min/max parallelism
The list of options will likely grow to cover more complex scaling scenarios.
For a detailed config reference check the general configuration page
Extensibility of Autoscaler #
The Autoscaler exposes a set of interfaces for storing autoscaler state, handling autoscaling events, and executing scaling decisions. How these are implemented is specific to the orchestration framework used (e.g. Kubernetes), but the interfaces are designed to be as generic as possible. The following are the introduction of these generic interfaces:
- AutoScalerEventHandler : Handling autoscaler events, such as: ScalingReport,
AutoscalerError, etc.
LoggingEventHandleris the default implementation, it logs events. - AutoScalerStateStore : Storing all state during scaling.
InMemoryAutoScalerStateStoreis the default implementation, it’s based on the Java Heap, so the state will be discarded after process restarts. We will implement persistent State Store in the future, such as :JdbcAutoScalerStateStore. - ScalingRealizer : Applying scaling actions.
- JobAutoScalerContext : Including all details related to the current job.
Autoscaler Standalone #
Flink Autoscaler Standalone is an implementation of Flink Autoscaler, it runs as a separate java process. It computes the reasonable parallelism of all job vertices by monitoring the metrics, such as: processing rate, busy time, etc.
Flink Autoscaler Standalone rescales flink job in-place by rest api of
Externalized Declarative Resource Management.
RescaleApiScalingRealizer is the default implementation of ScalingRealizer, it uses the Rescale API
to apply parallelism changes.
Kubernetes Operator is well integrated with Autoscaler, we strongly recommend using Kubernetes Operator directly for the kubernetes flink jobs, and only flink jobs in non-kubernetes environments use Autoscaler Standalone.
How To Use Autoscaler Standalone #
Currently, Flink Autoscaler Standalone only supports a single Flink cluster. It can be any type of
Flink cluster, includes:
- Flink Standalone Cluster
- MiniCluster
- Flink yarn session cluster
- Flink yarn application cluster
- Flink kubernetes session cluster
- Flink kubernetes application cluster
- etc
You can start a Flink Streaming job with the following ConfigOptions.
# Enable Adaptvie scheduler to play the in-place rescaling.
jobmanager.scheduler : adaptive
# Enable autoscale and scaling
job.autoscaler.enabled : true
job.autoscaler.scaling.enabled : true
job.autoscaler.stabilization.interval : 1m
job.autoscaler.metrics.window : 3m
Note: In-place rescaling is only supported since Flink 1.18. Flink jobs before version 1.18 cannot be scaled automatically, but you can view the
ScalingReportin Log.ScalingReportwill show the recommended parallelism for each vertex.
After the flink job starts, please start the StandaloneAutoscaler process by the following command.
java -cp flink-autoscaler-standalone-1.7.0.jar \
org.apache.flink.autoscaler.standalone.StandaloneAutoscalerEntrypoint \
--flinkClusterHost localhost \
--flinkClusterPort 8081
Updating the flinkClusterHost and flinkClusterPort based on your flink cluster.
In general, the host and port are the same as Flink WebUI.
Extensibility of autoscaler standalone #
Please click here to check out extensibility of generic autoscaler.
Autoscaler Standalone isn’t responsible for job management, so it doesn’t have job information.
Autoscaler Standalone defines the JobListFetcher interface in order to get the
JobAutoScalerContext of the job. It has a control loop that periodically calls
JobListFetcher#fetch to fetch the job list and scale these jobs.
Currently FlinkClusterJobListFetcher is the only implementation of the JobListFetcher
interface, that’s why Flink Autoscaler Standalone only supports a single Flink cluster so far.
We will implement YarnJobListFetcher in the future, Flink Autoscaler Standalone will call
YarnJobListFetcher#fetch to fetch job list from yarn cluster periodically.
Metrics #
The operator reports detailed jobvertex level metrics about the evaluated Flink job metrics that are collected and used in the scaling decision.
This includes:
- Utilization, input rate, target rate metrics
- Scaling thresholds
- Parallelism and max parallelism changes over time
These metrics are reported under the Kubernetes Operator Resource metric group:
[resource_prefix].Autoscaler.[jobVertexID].[ScalingMetric].Current/Average