This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
弹性扩缩容
弹性扩缩容 #
Historically, the parallelism of a job has been static throughout its lifecycle and defined once during its submission. Batch jobs couldn’t be rescaled at all, while Streaming jobs could have been stopped with a savepoint and restarted with a different parallelism.
This page describes a new class of schedulers that allow Flink to adjust job’s parallelism at runtime, which pushes Flink one step closer to a truly cloud-native stream processor. The new schedulers are Adaptive Scheduler (streaming) and Adaptive Batch Scheduler (batch).
Adaptive 调度器 #
The Adaptive Scheduler can adjust the parallelism of a job based on available slots. It will automatically reduce the parallelism if not enough slots are available to run the job with the originally configured parallelism; be it due to not enough resources being available at the time of submission, or TaskManager outages during the job execution. If new slots become available the job will be scaled up again, up to the configured parallelism.
In Reactive Mode (see below) the configured parallelism is ignored and treated as if it was set to infinity, letting the job always use as many resources as possible.
One benefit of the Adaptive Scheduler over the default scheduler is that it can handle TaskManager losses gracefully, since it would just scale down in these cases.

Adaptive Scheduler builds on top of a feature called Declarative Resource Management. As you can see, instead of asking for the exact number of slots, JobMaster declares its desired resources (for reactive mode the maximum is set to infinity) to the ResourceManager, which then tries to fulfill those resources.
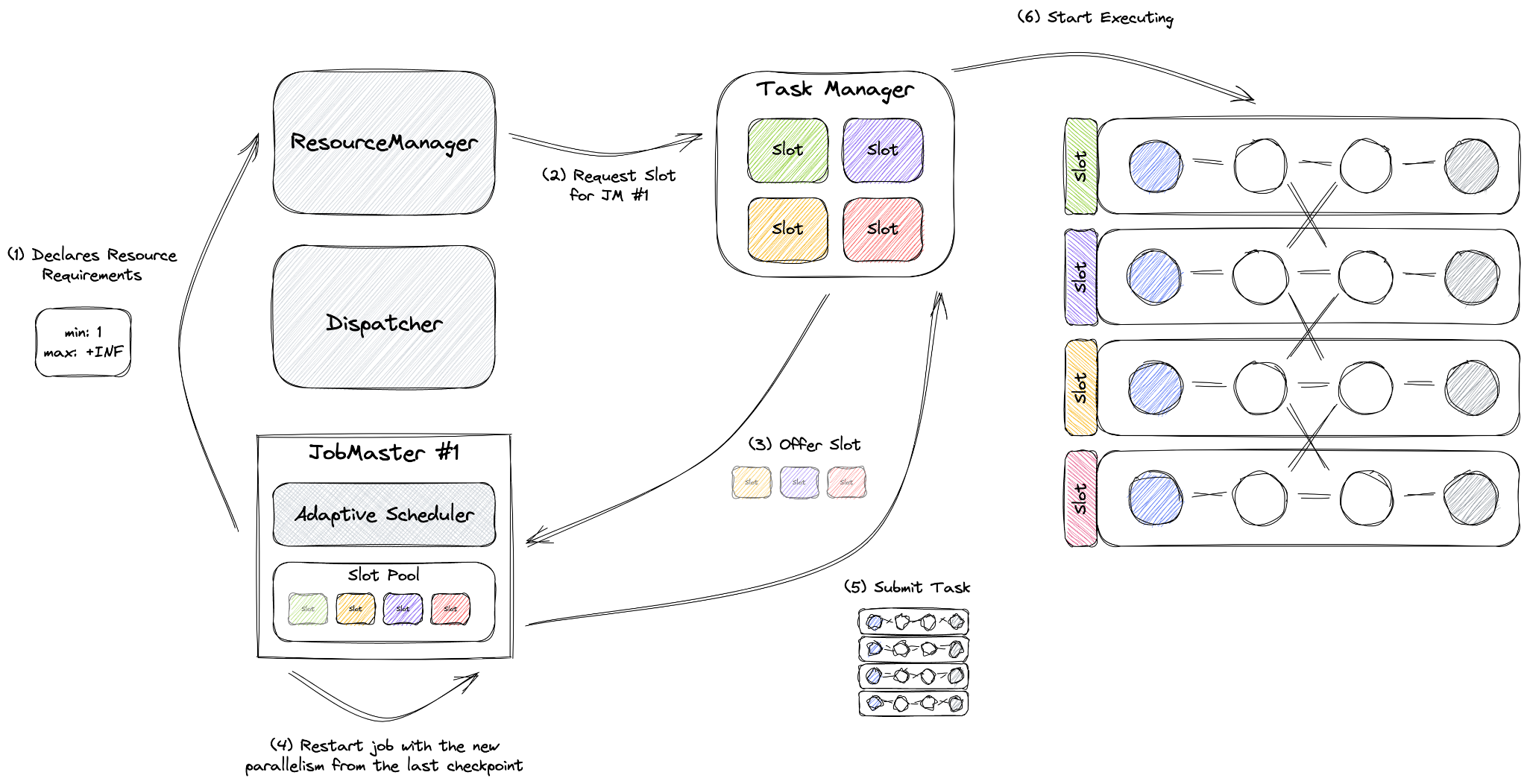
When JobMaster gets more resources during the runtime, it will automatically rescale the job using the latest available savepoint, eliminating the need for an external orchestration.
Starting from Flink 1.18.x, you can re-declare the resource requirements of a running job using Externalized Declarative Resource Management, otherwise the Adaptive Scheduler won’t be able to handle cases where the job needs to be rescaled due to a change in the input rate, or a change in the performance of the workload.
Externalized Declarative Resource Management #
Externalized Declarative Resource Management is an MVP (“minimum viable product”) feature. The Flink community is actively looking for feedback by users through our mailing lists. Please check the limitations listed on this page.
You can use Externalized Declarative Resource Management with the Apache Flink Kubernetes operator for a fully-fledged auto-scaling experience.
Externalized Declarative Resource Management aims to address two deployment scenarios:
- Adaptive Scheduler on Session Cluster, where multiple jobs can compete for resources, and you need a finer-grained control over the distribution of resources between jobs.
- Adaptive Scheduler on Application Cluster in combination with Active Resource Manager (e.g. Native Kubernetes), where you rely on Flink to “greedily” spawn new TaskManagers, but you still want to leverage rescaling capabilities as with Reactive Mode.
by introducing a new REST API endpoint, that allows you to re-declare resource requirements of a running job, by setting per-vertex parallelism boundaries.
PUT /jobs/<job-id>/resource-requirements
REQUEST BODY:
{
"<first-vertex-id>": {
"parallelism": {
"lowerBound": 3,
"upperBound": 5
}
},
"<second-vertex-id>": {
"parallelism": {
"lowerBound": 2,
"upperBound": 3
}
}
}
To a certain extent, the above endpoint could be thought about as a “re-scaling endpoint” and it introduces an important building block for building an auto-scaling experience for Flink.
You can manually try this feature out, by navigating the Job overview in the Flink UI and using up-scale/down-scale buttons in the task list.
Usage #
If you are using Adaptive Scheduler on a session cluster, there are no guarantees regarding the distribution of slots between multiple running jobs in the same session, in case the cluster doesn’t have enough resources. The External Declarative Resource Management can partially mitigate this issue, but it is still recommended to use Adaptive Scheduler on a application cluster.
The jobmanager.scheduler needs to be set to on the cluster level for the adaptive scheduler to be used instead of default scheduler.
jobmanager.scheduler: adaptive
The behavior of Adaptive Scheduler is configured by all configuration options prefixed with jobmanager.adaptive-scheduler in their name.
Limitations #
- Streaming jobs only: The Adaptive Scheduler runs with streaming jobs only. When submitting a batch job, Flink will use the default scheduler of batch jobs, i.e. Adaptive Batch Scheduler
- No support for partial failover: Partial failover means that the scheduler is able to restart parts (“regions” in Flink’s internals) of a failed job, instead of the entire job. This limitation impacts only recovery time of embarrassingly parallel jobs: Flink’s default scheduler can restart failed parts, while Adaptive Scheduler will restart the entire job.
- Scaling events trigger job and task restarts, which will increase the number of Task attempts.
Reactive 模式 #
Reactive Mode is a special mode for Adaptive Scheduler, that assumes a single job per-cluster (enforced by the Application Mode). Reactive Mode configures a job so that it always uses all resources available in the cluster. Adding a TaskManager will scale up your job, removing resources will scale it down. Flink will manage the parallelism of the job, always setting it to the highest possible values.
当发生扩缩容时,Job 会被重启,并且会从最新的 Checkpoint 中恢复。这就意味着不需要花费额外的开销去创建 Savepoint。当然,所需要重新处理的数据量取决于 Checkpoint 的间隔时长,而恢复的时间取决于状态的大小。
借助 Reactive 模式,Flink 用户可以通过一些外部的监控服务产生的指标,例如:消费延迟、CPU 利用率汇总、吞吐量、延迟等,实现一个强大的自动扩缩容机制。当上述的这些指标超出或者低于一定的阈值时,增加或者减少 TaskManager 的数量。在 Kubernetes 中,可以通过改变 Deployment 的副本数(Replica Factor) 实现。而在 AWS 中,可以通过改变 Auto Scaling 组 来实现。这类外部服务只需要负责资源的分配以及回收,而 Flink 则负责在这些资源上运行 Job。
入门 #
你可以参考下面的步骤试用 Reactive 模式。以下步骤假设你使用的是单台机器部署 Flink。
# 以下步骤假设你当前目录处于 Flink 发行版的根目录。
# 将 Job 拷贝到 lib/ 目录下
cp ./examples/streaming/TopSpeedWindowing.jar lib/
# 使用 Reactive 模式提交 Job
./bin/standalone-job.sh start -Dscheduler-mode=reactive -Dexecution.checkpointing.interval="10s" -j org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
# 启动第一个 TaskManager
./bin/taskmanager.sh start
让我们快速解释下上面每一条执行的命令:
./bin/standalone-job.sh start使用 Application 模式 部署 Flink。-Dscheduler-mode=reactive启动 Reactive 模式。-Dexecution.checkpointing.interval="10s"配置 Checkpoint 和重启策略。- 最后一个参数是 Job 的主函数名。
你现在已经启动了一个 Reactive 模式下的 Flink Job。在Web 界面上,你可以看到 Job 运行在一个 TaskManager 上。如果你想要扩容,可以再添加一个 TaskManager,
# 额外启动一个 TaskManager
./bin/taskmanager.sh start
如果想要缩容,可以关掉一个 TaskManager。
# 关闭 TaskManager
./bin/taskmanager.sh stop
用法 #
配置 #
通过将 scheduler-mode 配置成 reactive,你可以开启 Reactive 模式。
每个独立算子的并行度都将由调度器来决定,而不是由配置决定。当并行度在算子上或者整个 Job 上被显式设置时,这些值被会忽略。
而唯一能影响并行度的方式只有通过设置算子的最大并行度(调度器不会忽略这个值)。 最大并行度 maxParallelism 参数的值最大不能超过 2^15(32768)。如果你们没有给算子或者整个 Job 设置最大并行度,会采用默认的最大并行度规则。 这个值很有可能会低于它的最大上限。当使用默认的调度模式时,请参考并行度的最佳实践。
需要注意的是,过大的并行度会影响 Job 的性能,因为 Flink 为此需要维护更多的内部结构。
当开启 Reactive 模式时,jobmanager.adaptive-scheduler.resource-wait-timeout 配置的默认值是 -1。这意味着,JobManager 会一直等待,直到拥有足够的资源。
如果你想要 JobManager 在没有拿到足够的 TaskManager 的一段时间后关闭,可以配置这个参数。
当开启 Reactive 模式时,jobmanager.adaptive-scheduler.resource-stabilization-timeout 配置的默认值是 0:Flink 只要有足够的资源,就会启动 Job。
在 TaskManager 一个一个而不是同时启动的情况下,会造成 Job 在每一个 TaskManager 启动时重启一次。当你希望等待资源稳定后再启动 Job,那么可以增加这个配置的值。
另外,你还可以配置 jobmanager.adaptive-scheduler.min-parallelism-increase:这个配置能够指定在扩容前需要满足的最小额外增加的并行总数。例如,你的 Job 由并行度为 2 的 Source 和并行度为 2 的 Sink组成,并行总数为 4。这个配置的默认值是 1,所以任意并行总数的增加都会导致重启。
建议 #
-
为有状态的 Job 配置周期性的 Checkpoint:Reactive 模式在扩缩容时通过最新完成的 Checkpoint 恢复。如果没有配置周期性的 Checkpoint,你的程序会丢失状态。Checkpoint 同时还配置了重启策略,Reactive会使用配置的重启策略:如果没有设置,Reactive 模式会让 Job 失败而不是运行扩缩容。
-
在 Ractive 模式下缩容可能会导致长时间的停顿,因为 Flink 需要等待 JobManager 和已经停止的 TaskManager 间心跳超时。当你降低 Job 并行度时,你会发现 Job 会停顿大约 50 秒左右。
这是由于默认的心跳超时时间是 50 秒。在你的基础设施允许的情况下,可以降低
heartbeat.timeout的值。但是降低超时时间,会导致比如在网络拥堵或者 GC Pause 的时候,TaskManager 无法响应心跳。需要注意的是,heartbeat.interval配置需要低于超时时间。
局限性 #
由于 Reactive 模式是一个新的实验特性,并不是所有在默认调度器下的功能都能支持(也包括 Adaptive 调度器)。Flink 社区正在解决这些局限性。
-
仅支持 Standalone 部署模式。其他主动的部署模式实现(例如:原生的 Kubernetes 以及 YARN)都明确不支持。Session 模式也同样不支持。仅支持单 Job 的部署。
仅支持如下的部署方式:Application 模式下的 Standalone 部署(可以参考上文)、Application 模式下的 Docker 部署 以及 Standalone 的 Kubernetes Application 集群模式。
Adaptive 调度器的局限性 同样也适用于 Reactive 模式.
Adaptive Batch Scheduler #
Adaptive Batch Scheduler 是一种可以自动调整执行计划的批作业调度器。它目前支持自动推导算子并行度,如果算子未设置并行度,调度器将根据其消费的数据量的大小来推导其并行度。这可以带来诸多好处:
- 批作业用户可以从并行度调优中解脱出来
- 根据数据量自动推导并行度可以更好地适应每天变化的数据量
- SQL作业中的算子也可以分配不同的并行度
当前 Adaptive Batch Scheduler 是 Flink 默认的批作业调度器,无需额外配置。除非用户显式的配置了使用其他调度器,例如 jobmanager.scheduler: default。需要注意的是,由于 “只支持所有数据交换都为 BLOCKING 或 HYBRID 模式的作业”, 需要将 execution.batch-shuffle-mode 配置为 ALL_EXCHANGES_BLOCKING(默认值) 或 ALL_EXCHANGES_HYBRID_FULL 或 ALL_EXCHANGES_HYBRID_SELECTIVE。
自动推导并发度 #
用法 #
使用 Adaptive Batch Scheduler 自动推导算子的并行度,需要:
-
启用自动并行度推导:
Adaptive Batch Scheduler 默认启用了自动并行度推导,你可以通过配置
execution.batch.adaptive.auto-parallelism.enabled来开关此功能。 除此之外,你也可以根据作业的情况调整以下配置:execution.batch.adaptive.auto-parallelism.min-parallelism: 允许自动设置的并行度最小值。execution.batch.adaptive.auto-parallelism.max-parallelism: 允许自动设置的并行度最大值,如果该配置项没有配置将使用通过parallelism.default或者StreamExecutionEnvironment#setParallelism()设置的默认并行度作为允许自动设置的并行度最大值。execution.batch.adaptive.auto-parallelism.avg-data-volume-per-task: 期望每个任务平均处理的数据量大小。请注意,当出现数据倾斜,或者确定的并行度达到最大并行度(由于数据过多)时,一些任务实际处理的数据可能会远远超过这个值。execution.batch.adaptive.auto-parallelism.default-source-parallelism: source 算子可动态推导的最大并行度,若该配置项没有配置将优先使用execution-batch-adaptive-auto-parallelism-max-parallelism作为允许动态推导的并行度最大值,若该配置项也没有配置,将使用parallelism.default或者StreamExecutionEnvironment#setParallelism()设置的默认并行度。
-
不要指定算子的并行度:
Adaptive Batch Scheduler 只会为用户未指定并行度的算子推导并行度。 所以如果你想算子的并行度被自动推导,需要避免通过算子的
setParallelism()方法来为其指定并行度。除此之外,对于 DataSet 作业还需要进行以下配置:
- 配置
parallelism.default: -1 - 不要通过
ExecutionEnvironment的setParallelism()方法来指定并行度
- 配置
让 Source 支持动态并行度推导 #
如果你的作业有用到自定义 Source , 你需要让 Source 实现接口 DynamicParallelismInference 。
public interface DynamicParallelismInference {
int inferParallelism(Context context);
}
其中 Context 会提供可推导并行度上界、期望每个任务平均处理的数据量大小、动态过滤信息来协助并行度推导。 Adaptive Batch Scheduler 将会在调度 Source 节点之前调用上述接口,需注意实现中应尽量避免高耗时的操作。
若 Source 未实现上述接口,execution.batch.adaptive.auto-parallelism.default-source-parallelism 将会作为 Source 节点的并行度。
需注意,Source 动态并行度推导也只会为用户未指定并行度的 Source 算子推导并行度。
性能调优 #
- 建议使用 Sort Shuffle 并且设置
taskmanager.network.memory.buffers-per-channel为0。 这会解耦并行度与需要的网络内存,对于大规模作业,这样可以降低遇到 “Insufficient number of network buffers” 错误的可能性。 - 建议将
execution.batch.adaptive.auto-parallelism.max-parallelism设置为最坏情况下预期需要的并行度。不建议配置太大的值,否则可能会影响性能。这个配置项会影响上游任务产出的 subpartition 的数量,过多的 subpartition 可能会影响 hash shuffle 的性能,或者由于小包影响网络传输的性能。
局限性 #
- 只支持批作业: Adaptive Batch Scheduler 只支持批作业。当提交的是一个流作业时,会抛出异常。
- 只支持所有数据交换都为 BLOCKING 或 HYBRID 模式的作业: 目前 Adaptive Batch Scheduler 只支持 shuffle mode 为 ALL_EXCHANGES_BLOCKING 或 ALL_EXCHANGES_HYBRID_FULL 或 ALL_EXCHANGES_HYBRID_SELECTIVE 的作业。请注意,使用 DataSet API 的作业无法识别上述 shuffle 模式,需要将 ExecutionMode 设置为 BATCH_FORCED 才能强制启用 BLOCKING shuffle。
- 不支持 FileInputFormat 类型的 source: 不支持 FileInputFormat 类型的 source, 包括
StreamExecutionEnvironment#readFile(...)StreamExecutionEnvironment#readTextFile(...)和StreamExecutionEnvironment#createInput(FileInputFormat, ...)。 当使用 Adaptive Batch Scheduler 时,用户应该使用新版的 Source API (FileSystem DataStream Connector 或 FileSystem SQL Connector) 来读取文件. - Web UI 上展示的上游输出的数据量和下游收到的数据量可能不一致: 在使用 Adaptive Batch Scheduler 自动推导并行度时,对于 broadcast 边,上游算子发送的数据量和下游算子接收的数据量可能会不相等,这在 Web UI 的显示上可能会困扰用户。细节详见 FLIP-187。