This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
基于 Table API 实现实时报表
基于 Table API 实现实时报表 #
Apache Flink 提供了 Table API 作为批流统一的关系型 API。也就是说,在无界的实时流数据或者有界的批数据集上进行查询具有相同的语义,得到的结果一致。 Flink 的 Table API 可以简化数据分析、构建数据流水线以及 ETL 应用的定义。
你接下来要搭建的是什么系统? #
在本教程中,你将学习构建一个通过账户来追踪金融交易的实时看板。 数据流水线为:先从 Kafka 中读取数据,再将结果写入到 MySQL 中,最后通过 Grafana 展示。
准备条件 #
我们默认你对 Java 有一定了解,当然如果你使用的是其他编程语言,也可以继续学习。 同时也默认你了解基本的关系型概念,例如 SELECT 、GROUP BY 等语句。
困难求助 #
如果遇到问题,可以参考 社区支持资源。 Flink 的 用户邮件列表 是 Apache 项目中最活跃的一个,这也是快速寻求帮助的重要途径。
在 Windows 环境下,如果用来生成数据的 docker 容器启动失败,请检查使用的脚本是否正确。 例如 docker-entrypoint.sh 是容器 table-walkthrough_data-generator_1 所需的 bash 脚本。 如果不可用,会报 standard_init_linux.go:211: exec user process caused “no such file or directory” 的错误。 一种解决办法是在 docker-entrypoint.sh 的第一行将脚本执行器切换到 sh
如何跟着教程练习 #
本教程依赖如下运行环境:
- Java 11
- Maven
- Docker
注意: 本文中使用的 Apache Flink Docker 镜像仅适用于 Apache Flink 发行版。
由于你目前正在浏览快照版的文档,因此下文中引用的分支可能已经不存在了,请先通过左侧菜单下方的版本选择器切换到发行版文档再查看。
我们使用的配置文件位于 flink-playgrounds 代码仓库中,
当下载完成后,在你的 IDE 中打开 flink-playground/table-walkthrough 项目,并找到文件 SpendReport。
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
代码分析 #
执行环境 #
前两行代码创建了 TableEnvironment(表环境)。
创建表环境时,你可以设置作业属性,定义应用的批流模式,以及创建数据源。
我们先创建一个标准的表环境,并选择流式执行器。
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
注册表 #
接下来,在当前 catalog 中创建表,这样就可以读写外部系统的数据,批流数据都可以。 表类型的 source 可以读取外部系统中的数据,这些外部系统可以是数据库、键值类型存储、消息队列或者文件系统。 而表类型的 sink 则可以将表中的数据写到外部存储系统。 不同的 source 或 sink 类型,有不同的表格式(formats),例如 CSV, JSON, Avro, 或者 Parquet。
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
这里注册了两张表:一张存交易数据的输入表,一张存消费报告的输出表。
交易表(transactions)存的是信用卡交易记录,记录包含账户 ID(account_id),交易时间(transaction_time),以及美元单位的金额(amount)。
交易表实际是一个 Kafka topic 上的逻辑视图,视图对应的 topic 是 transactions,表格式是 CSV。
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
第二张 spend_report 表存储聚合后的最终结果,底层存储是 MySQL 数据库中的一张表。
查询数据 #
配置好环境并注册好表后,你就可以开始开发你的第一个应用了。
通过 TableEnvironment 实例 ,你可以使用函数 from 从输入表读取数据,然后将结果调用 executeInsert 写入到输出表。
函数 report 用于实现具体的业务逻辑,这里暂时未实现。
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
测试 #
项目还包含一个测试类 SpendReportTest,辅助验证报表逻辑。
该测试类的表环境使用的是批处理模式。
EnvironmentSettings settings = EnvironmentSettings.inBatchMode();
TableEnvironment tEnv = TableEnvironment.create(settings);
提供批流统一的语义是 Flink 的重要特性,这意味着应用的开发和测试可以在批模式下使用静态数据集完成,而实际部署到生产时再切换为流式。
尝试下 #
在作业拉起来的大体处理框架下,你可以再添加一些业务逻辑。 现在的目标是创建一个报表,报表按照账户显示一天中每个小时的总支出。因此,毫秒粒度的时间戳字段需要向下舍入到小时。
Flink 支持使用纯 SQL 或者 Table API 开发关系型数据应用。
其中,Table API 是受 SQL 启发设计出的一套链式 DSL,可以用 Python、Java 或者 Scala 开发,在 IDE 中也集成的很好。
同时也如 SQL 查询一样,Table 应用可以按列查询,或者按列分组。
通过类似 floor 以及 sum 这样的 系统函数,你已经可以开发这个报表了。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
用户自定义函数 #
Flink 内置的函数是有限的,有时是需要通过 用户自定义函数来拓展这些函数。
假如 floor 函数不是系统预设函数,也可以自己实现。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp) {
return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}
然后就可以在你的应用中使用了。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount"));
}
这条查询会从表 transactions 消费所有的记录,然后计算报表所需内容,最后将结果以高效、可拓展的方式输出。
按此逻辑实现,可以通过测试。
添加窗口函数 #
在数据处理中,按照时间做分组是常见操作,在处理无限流时更是如此。
按时间分组的函数叫 window,Flink 提供了灵活的窗口函数语法。
最常见的窗口是 Tumble ,窗口区间长度固定,并且区间不重叠。
public static Table report(Table transactions) {
return transactions
.window(Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts"))
.groupBy($("account_id"), $("log_ts"))
.select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount"));
}
上面的代码含义为:使用滚动窗口,窗口按照指定的时间戳字段划分,区间为一小时。
比如,时间戳为 2019-06-01 01:23:47 的行会进入窗口 2019-06-01 01:00:00中。
不同于其他属性,时间在一个持续不断的流式应用中总是向前移动,因此基于时间的聚合总是不重复的。
不同于 floor 以及 UDF,窗口函数是 [内部的]intrinsics,可以运行时优化。
批环境中,如果需要按照时间属性分组数据,窗口函数也有便利的 API。
按此逻辑实现,测试也可以通过。
再用流式处理一次! #
这次编写的应用是一个功能齐全、有状态的分布式流式应用! 查询语句持续消费 Kafka 中交易数据流,然后计算每小时的消费,最后当窗口结束时立刻提交结果。 由于输入是无边界的,停止作业需要手工操作。 同时,由于作业使用了窗口函数,Flink 会执行一些特定的优化,例如当框架检测出窗口结束时,清理状态数据。
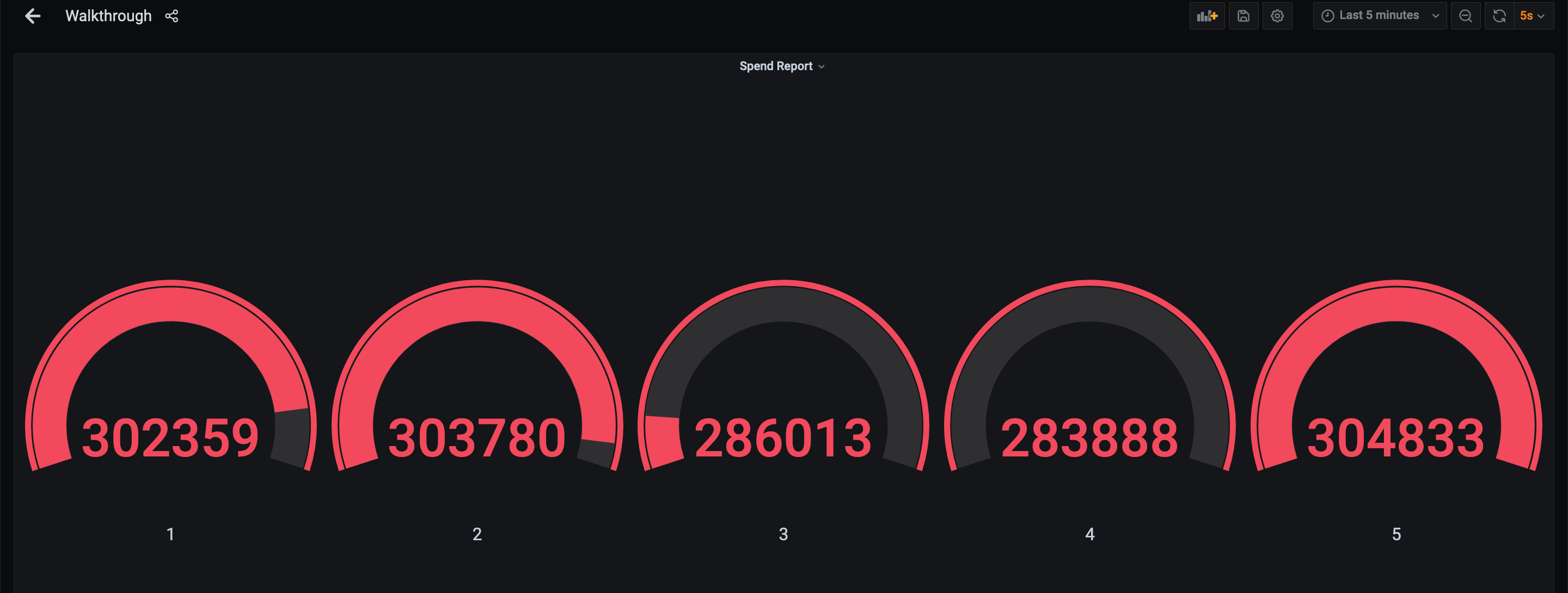
本次教程中的流式应用,已经完全容器化,并可以在本地运行。 环境中具体包含了 Kafka 的 topic、持续数据生成器、MySQL 以及 Grafana。
在 table-walkthrough 目录下启动 docker-compose 脚本。
$ docker-compose build
$ docker-compose up -d
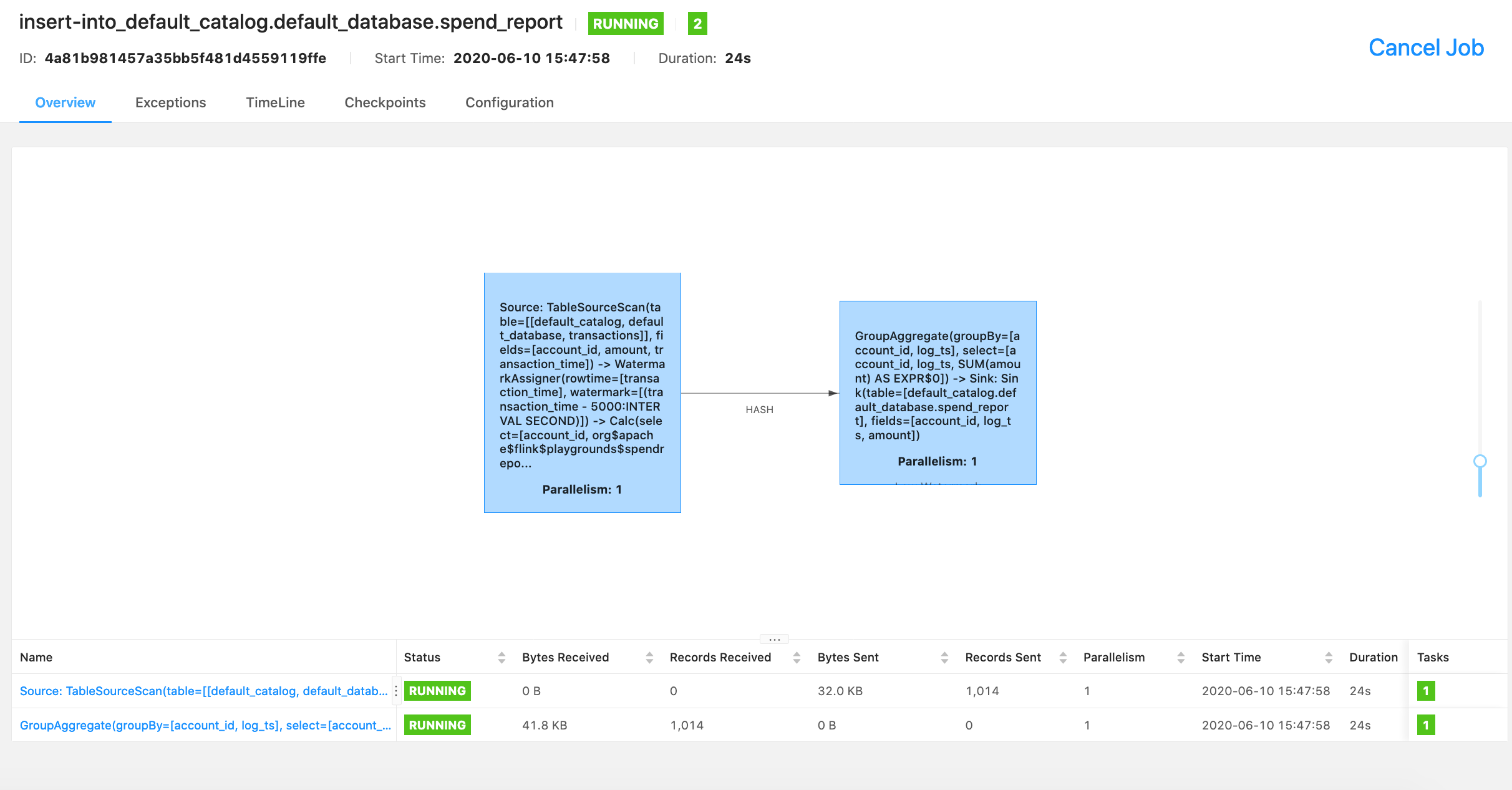
运行中的作业信息可以通过 Flink console 查看。
结果数据在 MySQL 中查看。
$ docker-compose exec mysql mysql -Dsql-demo -usql-demo -pdemo-sql
mysql> use sql-demo;
Database changed
mysql> select count(*) from spend_report;
+----------+
| count(*) |
+----------+
| 110 |
+----------+
完整的可视化结果可以访问 Grafana!