This documentation is for an out-of-date version of Apache Flink. We recommend you use the latest stable version.
SQL Client
SQL Client #
Flink’s Table & SQL API makes it possible to work with queries written in the SQL language, but these queries need to be embedded within a table program that is written in either Java or Scala. Moreover, these programs need to be packaged with a build tool before being submitted to a cluster. This more or less limits the usage of Flink to Java/Scala programmers.
The SQL Client aims to provide an easy way of writing, debugging, and submitting table programs to a Flink cluster without a single line of Java or Scala code. The SQL Client CLI allows for retrieving and visualizing real-time results from the running distributed application on the command line.
Getting Started #
This section describes how to setup and run your first Flink SQL program from the command-line.
The SQL Client is bundled in the regular Flink distribution and thus runnable out-of-the-box. It requires only a running Flink cluster where table programs can be executed. For more information about setting up a Flink cluster see the Cluster & Deployment part. If you simply want to try out the SQL Client, you can also start a local cluster with one worker using the following command:
./bin/start-cluster.sh
Starting the SQL Client CLI #
The SQL Client scripts are also located in the binary directory of Flink. In the future, a user will have two possibilities of starting the SQL Client CLI either by starting an embedded standalone process or by connecting to a remote SQL Client Gateway. At the moment only the embedded mode is supported, and default mode is embedded. You can start the CLI by calling:
./bin/sql-client.sh
or explicitly use embedded mode:
./bin/sql-client.sh embedded
See SQL Client startup options below for more details.
Running SQL Queries #
For validating your setup and cluster connection, you can enter the simple query below and press Enter to execute it.
SET 'sql-client.execution.result-mode' = 'tableau';
SET 'execution.runtime-mode' = 'batch';
SELECT
name,
COUNT(*) AS cnt
FROM
(VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name)
GROUP BY name;
The SQL client will retrieve the results from the cluster and visualize them (you can close the result view by pressing the Q key):
+-------+-----+
| name | cnt |
+-------+-----+
| Alice | 1 |
| Bob | 2 |
| Greg | 1 |
+-------+-----+
The SET command allows you to tune the job execution and the sql client behaviour. See SQL Client Configuration below for more details.
After a query is defined, it can be submitted to the cluster as a long-running, detached Flink job. The configuration section explains how to declare table sources for reading data, how to declare table sinks for writing data, and how to configure other table program properties.
Getting help #
The documentation of the SQL client commands can be accessed by typing the HELP command.
See also the general SQL documentation.
Configuration #
SQL Client startup options #
The SQL Client can be started with the following optional CLI commands. They are discussed in detail in the subsequent paragraphs.
./bin/sql-client.sh --help
Mode "embedded" (default) submits Flink jobs from the local machine.
Syntax: [embedded] [OPTIONS]
"embedded" mode options:
-f,--file <script file> Script file that should be executed.
In this mode, the client will not
open an interactive terminal.
-h,--help Show the help message with
descriptions of all options.
-hist,--history <History file path> The file which you want to save the
command history into. If not
specified, we will auto-generate one
under your user's home directory.
-i,--init <initialization file> Script file that used to init the
session context. If get error in
execution, the sql client will exit.
Notice it's not allowed to add query
or insert into the init file.
-j,--jar <JAR file> A JAR file to be imported into the
session. The file might contain
user-defined classes needed for the
execution of statements such as
functions, table sources, or sinks.
Can be used multiple times.
-l,--library <JAR directory> A JAR file directory with which every
new session is initialized. The files
might contain user-defined classes
needed for the execution of
statements such as functions, table
sources, or sinks. Can be used
multiple times.
-pyarch,--pyArchives <arg> Add python archive files for job. The
archive files will be extracted to
the working directory of python UDF
worker. For each archive file, a
target directory be specified. If the
target directory name is specified,
the archive file will be extracted to
a directory with the
specified name. Otherwise, the
archive file will be extracted to a
directory with the same name of the
archive file. The files uploaded via
this option are accessible via
relative path. '#' could be used as
the separator of the archive file
path and the target directory name.
Comma (',') could be used as the
separator to specify multiple archive
files. This option can be used to
upload the virtual environment, the
data files used in Python UDF (e.g.:
--pyArchives
file:///tmp/py37.zip,file:///tmp/data
.zip#data --pyExecutable
py37.zip/py37/bin/python). The data
files could be accessed in Python
UDF, e.g.: f = open('data/data.txt',
'r').
-pyexec,--pyExecutable <arg> Specify the path of the python
interpreter used to execute the
python UDF worker (e.g.:
--pyExecutable
/usr/local/bin/python3). The python
UDF worker depends on Python 3.6+,
Apache Beam (version == 2.27.0), Pip
(version >= 7.1.0) and SetupTools
(version >= 37.0.0). Please ensure
that the specified environment meets
the above requirements.
-pyfs,--pyFiles <pythonFiles> Attach custom files for job.
The standard resource file suffixes
such as .py/.egg/.zip/.whl or
directory are all supported. These
files will be added to the PYTHONPATH
of both the local client and the
remote python UDF worker. Files
suffixed with .zip will be extracted
and added to PYTHONPATH. Comma (',')
could be used as the separator to
specify multiple files (e.g.:
--pyFiles
file:///tmp/myresource.zip,hdfs:///$n
amenode_address/myresource2.zip).
-pyreq,--pyRequirements <arg> Specify a requirements.txt file which
defines the third-party dependencies.
These dependencies will be installed
and added to the PYTHONPATH of the
python UDF worker. A directory which
contains the installation packages of
these dependencies could be specified
optionally. Use '#' as the separator
if the optional parameter exists
(e.g.: --pyRequirements
file:///tmp/requirements.txt#file:///
tmp/cached_dir).
-s,--session <session identifier> The identifier for a session.
'default' is the default identifier.
-u,--update <SQL update statement> Deprecated Experimental (for testing
only!) feature: Instructs the SQL
Client to immediately execute the
given update statement after starting
up. The process is shut down after
the statement has been submitted to
the cluster and returns an
appropriate return code. Currently,
this feature is only supported for
INSERT INTO statements that declare
the target sink table.Please use
option -f to submit update statement.
SQL Client Configuration #
You can configure the SQL client by setting the options below, or any valid Flink configuration entry:
SET 'key' = 'value';
| Key | Default | Type | Description |
|---|---|---|---|
sql-client.display.max-column-widthStreaming |
30 | Integer | When printing the query results, this parameter determines the number of characters shown on screen before truncating.This only applies to columns with variable-length types (e.g. STRING) in streaming mode.Fixed-length types and all types in batch mode are printed using a deterministic column width |
sql-client.execution.max-table-result.rowsBatch Streaming |
1000000 | Integer | The number of rows to cache when in the table mode. If the number of rows exceeds the specified value, it retries the row in the FIFO style. |
sql-client.execution.result-modeBatch Streaming |
TABLE | Enum |
Determines how the query result should be displayed. Possible values:
|
sql-client.verboseBatch Streaming |
false | Boolean | Determine whether to output the verbose output to the console. If set the option true, it will print the exception stack. Otherwise, it only output the cause. |
SQL client result modes #
The CLI supports three modes for maintaining and visualizing results.
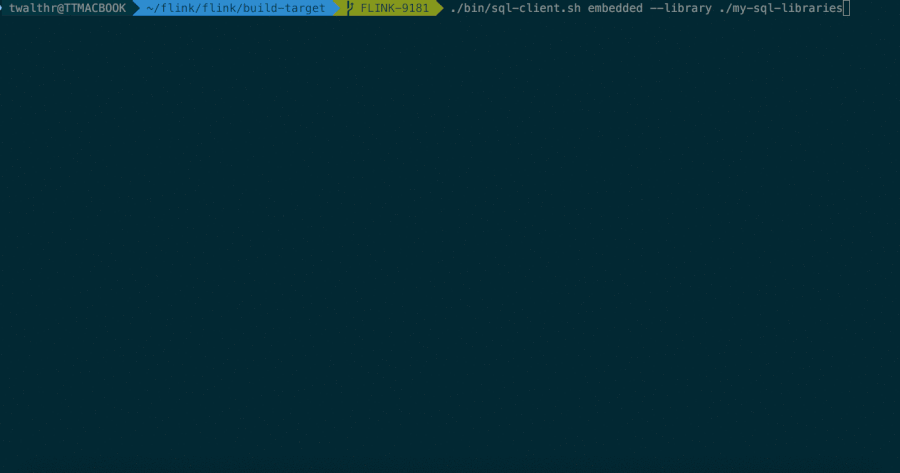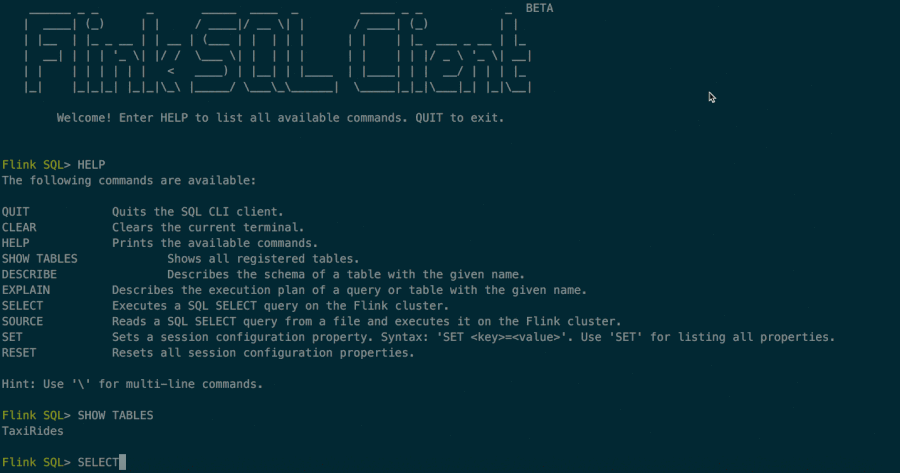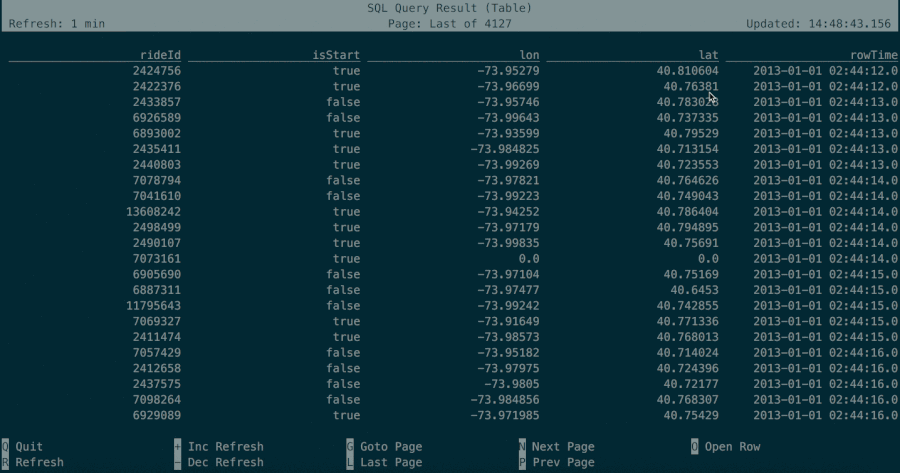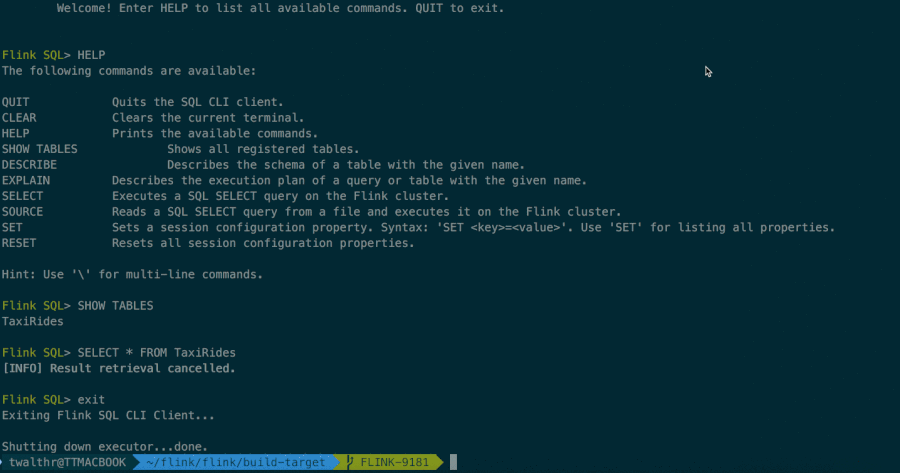
The table mode materializes results in memory and visualizes them in a regular, paginated table representation. It can be enabled by executing the following command in the CLI:
SET 'sql-client.execution.result-mode' = 'table';
The result of a query would then look like this, you can use the keys indicated at the bottom of the screen as well as the arrows keys to navigate and open the various records:
name age isHappy dob height
user1 20 true 1995-12-03 1.7
user2 30 true 1972-08-02 1.89
user3 40 false 1983-12-23 1.63
user4 41 true 1977-11-13 1.72
user5 22 false 1998-02-20 1.61
user6 12 true 1969-04-08 1.58
user7 38 false 1987-12-15 1.6
user8 62 true 1996-08-05 1.82
Q Quit + Inc Refresh G Goto Page N Next Page O Open Row
R Refresh - Dec Refresh L Last Page P Prev Page
The changelog mode does not materialize results and visualizes the result stream that is produced
by a continuous query consisting of insertions (+) and retractions (-).
SET 'sql-client.execution.result-mode' = 'changelog';
The result of a query would then look like this:
op name age isHappy dob height
+I user1 20 true 1995-12-03 1.7
+I user2 30 true 1972-08-02 1.89
+I user3 40 false 1983-12-23 1.63
+I user4 41 true 1977-11-13 1.72
+I user5 22 false 1998-02-20 1.61
+I user6 12 true 1969-04-08 1.58
+I user7 38 false 1987-12-15 1.6
+I user8 62 true 1996-08-05 1.82
Q Quit + Inc Refresh O Open Row
R Refresh - Dec Refresh
The tableau mode is more like a traditional way which will display the results in the screen directly with a tableau format.
The displaying content will be influenced by the query execution type (execution.type).
SET 'sql-client.execution.result-mode' = 'tableau';
The result of a query would then look like this:
+----+--------------------------------+-------------+---------+------------+--------------------------------+
| op | name | age | isHappy | dob | height |
+----+--------------------------------+-------------+---------+------------+--------------------------------+
| +I | user1 | 20 | true | 1995-12-03 | 1.7 |
| +I | user2 | 30 | true | 1972-08-02 | 1.89 |
| +I | user3 | 40 | false | 1983-12-23 | 1.63 |
| +I | user4 | 41 | true | 1977-11-13 | 1.72 |
| +I | user5 | 22 | false | 1998-02-20 | 1.61 |
| +I | user6 | 12 | true | 1969-04-08 | 1.58 |
| +I | user7 | 38 | false | 1987-12-15 | 1.6 |
| +I | user8 | 62 | true | 1996-08-05 | 1.82 |
+----+--------------------------------+-------------+---------+------------+--------------------------------+
Received a total of 8 rows
Note that when you use this mode with streaming query, the result will be continuously printed on the console. If the input data of
this query is bounded, the job will terminate after Flink processed all input data, and the printing will also be stopped automatically.
Otherwise, if you want to terminate a running query, just type CTRL-C in this case, the job and the printing will be stopped.
All these result modes can be useful during the prototyping of SQL queries. In all these modes,
results are stored in the Java heap memory of the SQL Client. In order to keep the CLI interface responsive,
the changelog mode only shows the latest 1000 changes. The table mode allows for navigating through
bigger results that are only limited by the available main memory and the configured
maximum number of rows (sql-client.execution.max-table-result.rows).
Attention Queries that are executed in a batch environment, can only be retrieved using the table or tableau result mode.
Initialize Session Using SQL Files #
A SQL query needs a configuration environment in which it is executed. SQL Client supports the -i
startup option to execute an initialization SQL file to setup environment when starting up the SQL Client.
The so-called initialization SQL file can use DDLs to define available catalogs, table sources and sinks,
user-defined functions, and other properties required for execution and deployment.
An example of such a file is presented below.
-- Define available catalogs
CREATE CATALOG MyCatalog
WITH (
'type' = 'hive'
);
USE CATALOG MyCatalog;
-- Define available database
CREATE DATABASE MyDatabase;
USE MyDatabase;
-- Define TABLE
CREATE TABLE MyTable(
MyField1 INT,
MyField2 STRING
) WITH (
'connector' = 'filesystem',
'path' = '/path/to/something',
'format' = 'csv'
);
-- Define VIEW
CREATE VIEW MyCustomView AS SELECT MyField2 FROM MyTable;
-- Define user-defined functions here.
CREATE FUNCTION foo.bar.AggregateUDF AS myUDF;
-- Properties that change the fundamental execution behavior of a table program.
SET 'execution.runtime-mode' = 'streaming'; -- execution mode either 'batch' or 'streaming'
SET 'sql-client.execution.result-mode' = 'table'; -- available values: 'table', 'changelog' and 'tableau'
SET 'sql-client.execution.max-table-result.rows' = '10000'; -- optional: maximum number of maintained rows
SET 'parallelism.default' = '1'; -- optional: Flink's parallelism (1 by default)
SET 'pipeline.auto-watermark-interval' = '200'; --optional: interval for periodic watermarks
SET 'pipeline.max-parallelism' = '10'; -- optional: Flink's maximum parallelism
SET 'table.exec.state.ttl' = '1000'; -- optional: table program's idle state time
SET 'restart-strategy' = 'fixed-delay';
-- Configuration options for adjusting and tuning table programs.
SET 'table.optimizer.join-reorder-enabled' = 'true';
SET 'table.exec.spill-compression.enabled' = 'true';
SET 'table.exec.spill-compression.block-size' = '128kb';
This configuration:
- connects to Hive catalogs and uses
MyCatalogas the current catalog withMyDatabaseas the current database of the catalog, - defines a table
MyTableSourcethat can read data from a CSV file, - defines a view
MyCustomViewthat declares a virtual table using a SQL query, - defines a user-defined function
myUDFthat can be instantiated using the class name, - uses streaming mode for running statements and a parallelism of 1,
- runs exploratory queries in the
tableresult mode, - and makes some planner adjustments around join reordering and spilling via configuration options.
When using -i <init.sql> option to initialize SQL Client session, the following statements are allowed in an initialization SQL file:
- DDL(CREATE/DROP/ALTER),
- USE CATALOG/DATABASE,
- LOAD/UNLOAD MODULE,
- SET command,
- RESET command.
When execute queries or insert statements, please enter the interactive mode or use the -f option to submit the SQL statements.
Attention If SQL Client receives errors during initialization, SQL Client will exit with error messages.
Dependencies #
The SQL Client does not require setting up a Java project using Maven, Gradle, or sbt. Instead, you
can pass the dependencies as regular JAR files that get submitted to the cluster. You can either specify
each JAR file separately (using --jar) or define entire library directories (using --library). For
connectors to external systems (such as Apache Kafka) and corresponding data formats (such as JSON),
Flink provides ready-to-use JAR bundles. These JAR files can be downloaded for each release from
the Maven central repository.
The full list of offered SQL JARs can be found on the connection to external systems page.
You can refer to the configuration section for information on how to configure connector and format dependencies.
Use SQL Client to submit job #
SQL Client allows users to submit jobs either within the interactive command line or using -f option to execute sql file.
In both modes, SQL Client supports to parse and execute all types of the Flink supported SQL statements.
Interactive Command Line #
In interactive Command Line, the SQL Client reads user inputs and executes the statement terminated by a semicolon (;).
SQL Client will print success message if the statement is executed successfully. When getting errors, SQL Client will also print error messages.
By default, the error message only contains the error cause. In order to print the full exception stack for debugging, please set the
sql-client.verbose to true through command SET 'sql-client.verbose' = 'true';.
Execute SQL Files #
SQL Client supports to execute a SQL script file with the -f option. SQL Client will execute
statements one by one in the SQL script file and print execution messages for each executed statements.
Once a statement fails, the SQL Client will exit and all the remaining statements will not be executed.
An example of such a file is presented below.
CREATE TEMPORARY TABLE users (
user_id BIGINT,
user_name STRING,
user_level STRING,
region STRING,
PRIMARY KEY (user_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'users',
'properties.bootstrap.servers' = '...',
'key.format' = 'csv',
'value.format' = 'avro'
);
-- set sync mode
SET 'table.dml-sync' = 'true';
-- set the job name
SET 'pipeline.name' = 'SqlJob';
-- set the queue that the job submit to
SET 'yarn.application.queue' = 'root';
-- set the job parallelism
SET 'parallelism.default' = '100';
-- restore from the specific savepoint path
SET 'execution.savepoint.path' = '/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab';
INSERT INTO pageviews_enriched
SELECT *
FROM pageviews AS p
LEFT JOIN users FOR SYSTEM_TIME AS OF p.proctime AS u
ON p.user_id = u.user_id;
This configuration:
- defines a temporal table source
usersthat reads from a CSV file, - set the properties, e.g job name,
- set the savepoint path,
- submit a sql job that load the savepoint from the specified savepoint path.
Attention Compared to the interactive mode, SQL Client will stop execution and exits when there are errors.
Execute a set of SQL statements #
SQL Client execute each INSERT INTO statement as a single Flink job. However, this is sometimes not
optimal because some part of the pipeline can be reused. SQL Client supports STATEMENT SET syntax to
execute a set of SQL statements. This is an equivalent feature with StatementSet in Table API. The
STATEMENT SET syntax encloses one or more INSERT INTO statements. All statements in a STATEMENT SET
block are holistically optimized and executed as a single Flink job. Joint optimization and execution
allows for reusing common intermediate results and can therefore significantly improve the efficiency
of executing multiple queries.
Syntax #
EXECUTE STATEMENT SET
BEGIN
-- one or more INSERT INTO statements
{ INSERT INTO|OVERWRITE <select_statement>; }+
END;
Attention The statements of enclosed in the STATEMENT SET must be separated by a semicolon (;).
The old syntax BEGIN STATEMENT SET; ... END; is deprecated, may be removed in the future version.
Flink SQL> CREATE TABLE pageviews (
> user_id BIGINT,
> page_id BIGINT,
> viewtime TIMESTAMP,
> proctime AS PROCTIME()
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'pageviews',
> 'properties.bootstrap.servers' = '...',
> 'format' = 'avro'
> );
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE pageview (
> page_id BIGINT,
> cnt BIGINT
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://localhost:3306/mydatabase',
> 'table-name' = 'pageview'
> );
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE uniqueview (
> page_id BIGINT,
> cnt BIGINT
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://localhost:3306/mydatabase',
> 'table-name' = 'uniqueview'
> );
[INFO] Execute statement succeed.
Flink SQL> EXECUTE STATEMENT SET
> BEGIN
>
> INSERT INTO pageview
> SELECT page_id, count(1)
> FROM pageviews
> GROUP BY page_id;
>
> INSERT INTO uniqueview
> SELECT page_id, count(distinct user_id)
> FROM pageviews
> GROUP BY page_id;
>
> END;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 6b1af540c0c0bb3fcfcad50ac037c862
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
proctime AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = '...',
'format' = 'avro'
);
CREATE TABLE pageview (
page_id BIGINT,
cnt BIGINT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'pageview'
);
CREATE TABLE uniqueview (
page_id BIGINT,
cnt BIGINT
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'uniqueview'
);
EXECUTE STATEMENT SET
BEGIN
INSERT INTO pageview
SELECT page_id, count(1)
FROM pageviews
GROUP BY page_id;
INSERT INTO uniqueview
SELECT page_id, count(distinct user_id)
FROM pageviews
GROUP BY page_id;
END;
Execute DML statements sync/async #
By default, SQL Client executes DML statements asynchronously. That means, SQL Client will submit a job for the DML statement to a Flink cluster, and not wait for the job to finish. So SQL Client can submit multiple jobs at the same time. This is useful for streaming jobs, which are long-running in general.
SQL Client makes sure that a statement is successfully submitted to the cluster. Once the statement is submitted, the CLI will show information about the Flink job.
Flink SQL> INSERT INTO MyTableSink SELECT * FROM MyTableSource;
[INFO] Table update statement has been successfully submitted to the cluster:
Cluster ID: StandaloneClusterId
Job ID: 6f922fe5cba87406ff23ae4a7bb79044
Attention The SQL Client does not track the status of the running Flink job after submission. The CLI process can be shutdown after the submission without affecting the detached query. Flink’s restart strategy takes care of the fault-tolerance. A query can be cancelled using Flink’s web interface, command-line, or REST API.
However, for batch users, it’s more common that the next DML statement requires waiting until the
previous DML statement finishes. In order to execute DML statements synchronously, you can set
table.dml-sync option to true in SQL Client.
Flink SQL> SET 'table.dml-sync' = 'true';
[INFO] Session property has been set.
Flink SQL> INSERT INTO MyTableSink SELECT * FROM MyTableSource;
[INFO] Submitting SQL update statement to the cluster...
[INFO] Execute statement in sync mode. Please wait for the execution finish...
[INFO] Complete execution of the SQL update statement.
Attention If you want to terminate the job, just type CTRL-C to cancel the execution.
Start a SQL Job from a savepoint #
Flink supports to start the job with specified savepoint. In SQL Client, it’s allowed to use SET command to specify the path of the savepoint.
Flink SQL> SET 'execution.savepoint.path' = '/tmp/flink-savepoints/savepoint-cca7bc-bb1e257f0dab';
[INFO] Session property has been set.
-- all the following DML statements will be restroed from the specified savepoint path
Flink SQL> INSERT INTO ...
When the path to savepoint is specified, Flink will try to restore the state from the savepoint when executing all the following DML statements.
Because the specified savepoint path will affect all the following DML statements, you can use RESET command to reset this config option, i.e. disable restoring from savepoint.
Flink SQL> RESET execution.savepoint.path;
[INFO] Session property has been reset.
For more details about creating and managing savepoints, please refer to Job Lifecycle Management.
Define a Custom Job Name #
SQL Client supports to define job name for queries and DML statements through SET command.
Flink SQL> SET 'pipeline.name' = 'kafka-to-hive';
[INFO] Session property has been set.
-- all the following DML statements will use the specified job name.
Flink SQL> INSERT INTO ...
Because the specified job name will affect all the following queries and DML statements, you can also use RESET command to reset this configuration, i.e. use default job names.
Flink SQL> RESET pipeline.name;
[INFO] Session property has been reset.
If the option pipeline.name is not specified, SQL Client will generate a default name for the submitted job, e.g. insert-into_<sink_table_name> for INSERT INTO statements.
Limitations & Future #
The current SQL Client only supports embedded mode. In the future, the community plans to extend its functionality by providing a REST-based SQL Client Gateway, see more in FLIP-24 and FLIP-91.