Execution Mode #
The Python API supports different runtime execution modes from which you can choose depending on the requirements of your use case and the characteristics of your job. The Python runtime execution mode defines how the Python user-defined functions will be executed.
Prior to release-1.15, there is the only execution mode called PROCESS execution mode. The PROCESS
mode means that the Python user-defined functions will be executed in separate Python processes.
In release-1.15, it has introduced a new execution mode called THREAD execution mode. The THREAD
mode means that the Python user-defined functions will be executed in JVM.
NOTE: Multiple Python user-defined functions running in the same JVM are still affected by GIL.
When can/should I use THREAD execution mode? #
The purpose of the introduction of THREAD mode is to overcome the overhead of serialization/deserialization
and network communication introduced of inter-process communication in the PROCESS mode.
So if performance is not your concern, or the computing logic of your Python user-defined functions is the performance bottleneck of the job,
PROCESS mode will be the best choice as PROCESS mode provides the best isolation compared to THREAD mode.
Configuring Python execution mode #
The execution mode can be configured via the python.execution-mode setting.
There are two possible values:
PROCESS: The Python user-defined functions will be executed in separate Python process. (default)THREAD: The Python user-defined functions will be executed in JVM.
You could specify the execution mode in Python Table API or Python DataStream API jobs as following:
## Python Table API
# Specify `PROCESS` mode
table_env.get_config().set("python.execution-mode", "process")
# Specify `THREAD` mode
table_env.get_config().set("python.execution-mode", "thread")
## Python DataStream API
config = Configuration()
# Specify `PROCESS` mode
config.set_string("python.execution-mode", "process")
# Specify `THREAD` mode
config.set_string("python.execution-mode", "thread")
# Create the corresponding StreamExecutionEnvironment
env = StreamExecutionEnvironment.get_execution_environment(config)
Supported Cases #
Python Table API #
The following table shows where the THREAD execution mode is supported in Python Table API.
| UDFs | PROCESS |
THREAD |
|---|---|---|
| Python UDF | Yes | Yes |
| Python UDTF | Yes | Yes |
| Python UDAF | Yes | No |
| Pandas UDF & Pandas UDAF | Yes | No |
Python DataStream API #
The following Table shows the supported cases in Python DataStream API.
| Operators | PROCESS |
THREAD |
|---|---|---|
| Map | Yes | Yes |
| FlatMap | Yes | Yes |
| Filter | Yes | Yes |
| Reduce | Yes | Yes |
| Union | Yes | Yes |
| Connect | Yes | Yes |
| CoMap | Yes | Yes |
| CoFlatMap | Yes | Yes |
| Process Function | Yes | Yes |
| Window Apply | Yes | Yes |
| Window Aggregate | Yes | Yes |
| Window Reduce | Yes | Yes |
| Window Process | Yes | Yes |
| Side Output | Yes | Yes |
| State | Yes | Yes |
| Iterate | No | No |
| Window CoGroup | No | No |
| Window Join | No | No |
| Interval Join | No | No |
| Async I/O | No | No |
Currently, it still doesn’t support to execute Python UDFs inTHREADexecution mode in all places. It will fall back toPROCESSexecution mode in these cases. So it may happen that you configure a job to execute inTHREADexecution mode, however, it’s actually executed inPROCESSexecution mode.
THREAD execution mode is only supported in Python 3.8+.
Execution Behavior #
This section provides an overview of the execution behavior of THREAD execution mode and contrasts
they with PROCESS execution mode. For more details, please refer to the FLIP that introduced this feature:
FLIP-206.
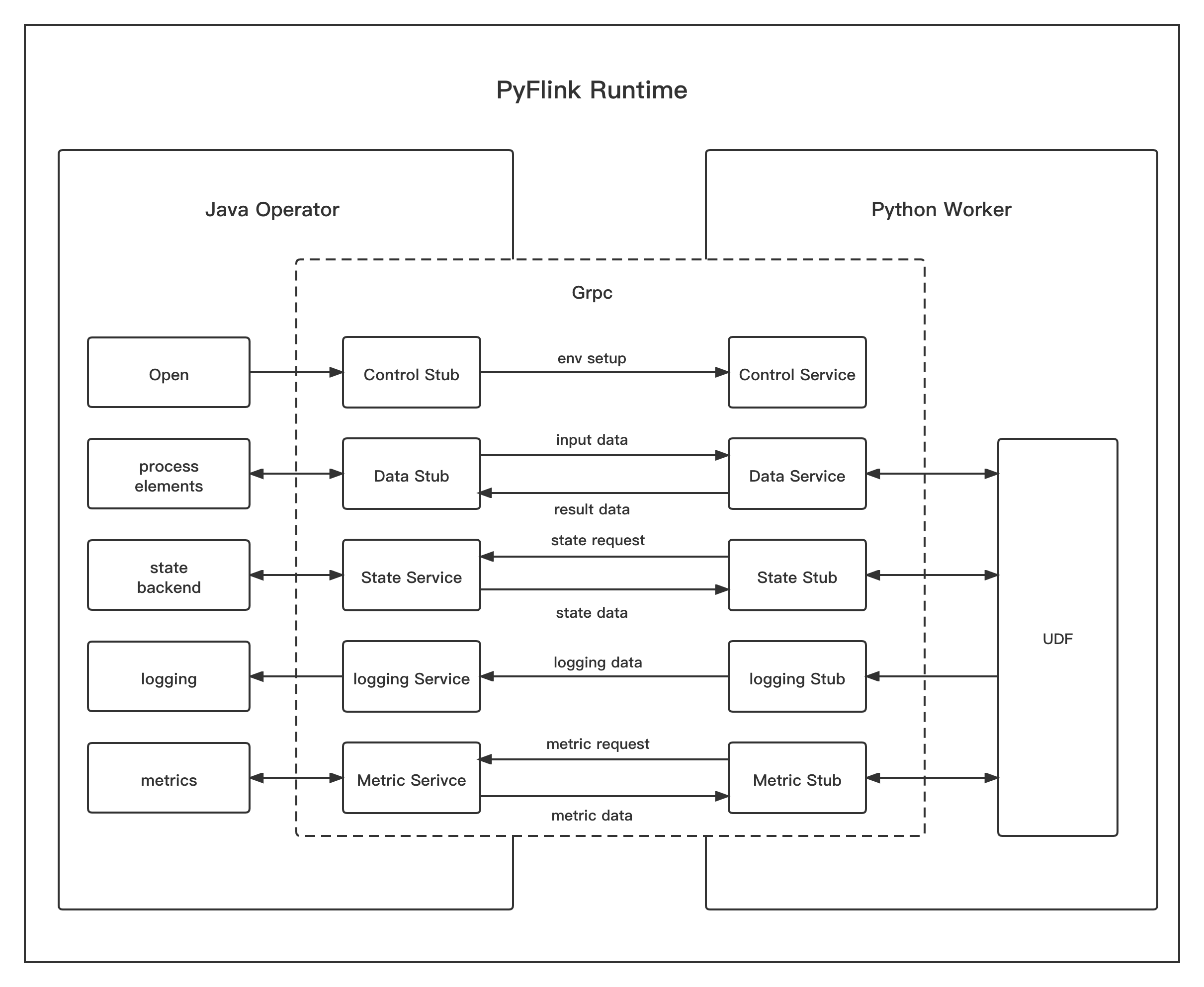
PROCESS Execution Mode #
In PROCESS execution mode, the Python user-defined functions will be executed in separate Python Worker process.
The Java operator process communicates with the Python worker process using various Grpc services.
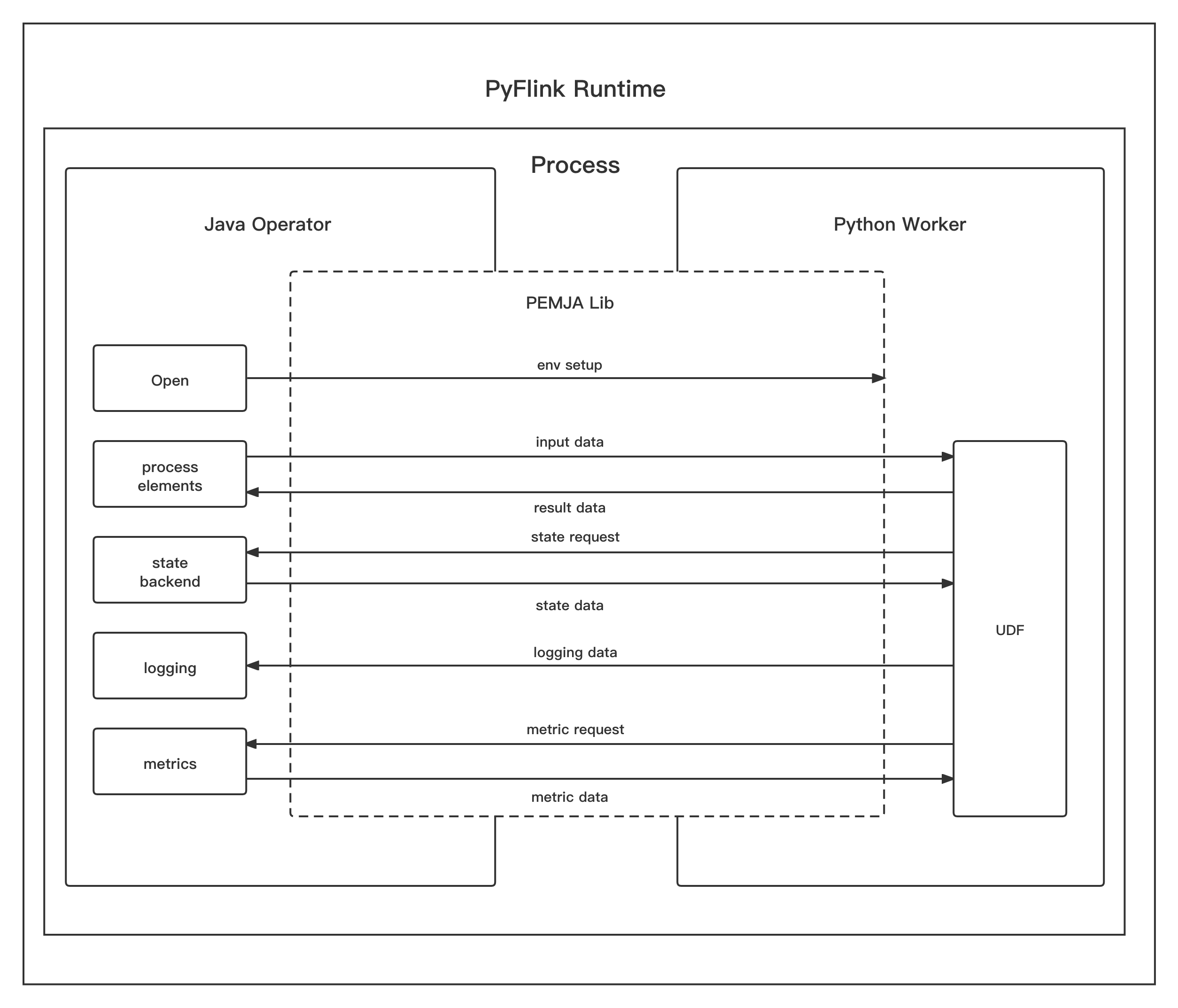
THREAD Execution Mode #
In THREAD execution mode, the Python user-defined functions will be executed in the same process
as Java operators. PyFlink takes use of third part library PEMJA
to embed Python in Java Application.