State Processor API #
Apache Flink’s State Processor API provides powerful functionality to reading, writing, and modifying savepoints and checkpoints using Flink’s DataStream API under BATCH execution.
Due to the interoperability of DataStream and Table API, you can even use relational Table API or SQL queries to analyze and process state data.
For example, you can take a savepoint of a running stream processing application and analyze it with a DataStream batch program to verify that the application behaves correctly. Or you can read a batch of data from any store, preprocess it, and write the result to a savepoint that you use to bootstrap the state of a streaming application. It is also possible to fix inconsistent state entries. Finally, the State Processor API opens up many ways to evolve a stateful application that was previously blocked by parameter and design choices that could not be changed without losing all the state of the application after it was started. For example, you can now arbitrarily modify the data types of states, adjust the maximum parallelism of operators, split or merge operator state, re-assign operator UIDs, and so on.
To get started with the state processor api, include the following library in your application.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-state-processor-api</artifactId>
<version>1.19.1</version>
</dependency>Mapping Application State to DataSets #
The State Processor API maps the state of a streaming application to one or more data sets that can be processed separately. In order to be able to use the API, you need to understand how this mapping works.
But let us first have a look at what a stateful Flink job looks like. A Flink job is composed of operators; typically one or more source operators, a few operators for the actual processing, and one or more sink operators. Each operator runs in parallel in one or more tasks and can work with different types of state. An operator can have zero, one, or more “operator states” which are organized as lists that are scoped to the operator’s tasks. If the operator is applied on a keyed stream, it can also have zero, one, or more “keyed states” which are scoped to a key that is extracted from each processed record. You can think of keyed state as a distributed key-value map.
The following figure shows the application “MyApp” which consists of three operators called “Src”, “Proc”, and “Snk”. Src has one operator state (os1), Proc has one operator state (os2) and two keyed states (ks1, ks2) and Snk is stateless.
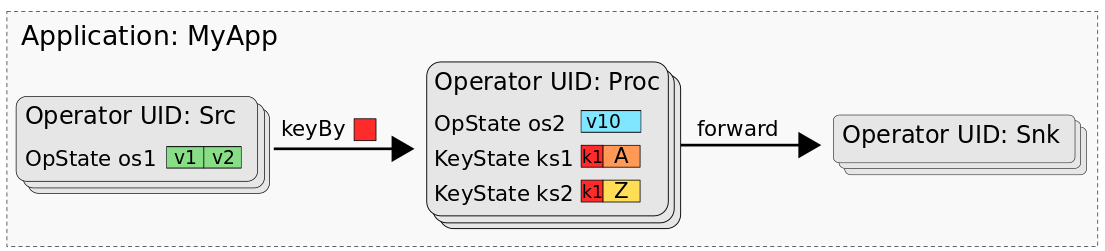
A savepoint or checkpoint of MyApp consists of the data of all states, organized in a way that the states of each task can be restored. When processing the data of a savepoint (or checkpoint) with a batch job, we need a mental model that maps the data of the individual tasks’ states into data sets or tables. In fact, we can think of a savepoint as a database. Every operator (identified by its UID) represents a namespace. Each operator state of an operator is mapped to a dedicated table in the namespace with a single column that holds the state’s data of all tasks. All keyed states of an operator are mapped to a single table consisting of a column for the key, and one column for each keyed state. The following figure shows how a savepoint of MyApp is mapped to a database.
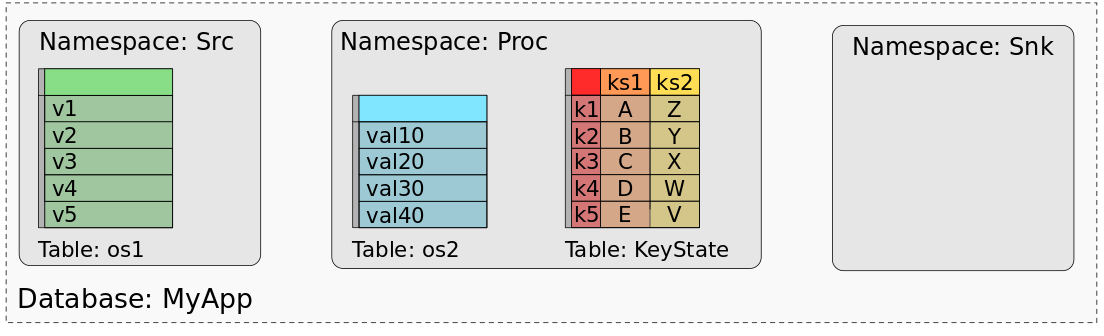
The figure shows how the values of Src’s operator state are mapped to a table with one column and five rows, one row for each of the list entries across all parallel tasks of Src. Operator state os2 of the operator “Proc” is similarly mapped to an individual table. The keyed states ks1 and ks2 are combined to a single table with three columns, one for the key, one for ks1 and one for ks2. The keyed table holds one row for each distinct key of both keyed states. Since the operator “Snk” does not have any state, its namespace is empty.
Identifying operators #
The State Processor API allows you to identify operators using UIDs or UID hashes via OperatorIdentifier#forUid/forUidHash.
Hashes should only be used when the use of UIDs is not possible, for example when the application that created the savepoint did not specify them or when the UID is unknown.
Reading State #
Reading state begins by specifying the path to a valid savepoint or checkpoint along with the StateBackend that should be used to restore the data.
The compatibility guarantees for restoring state are identical to those when restoring a DataStream application.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SavepointReader savepoint = SavepointReader.read(env, "hdfs://path/", new HashMapStateBackend());
Operator State #
Operator state is any non-keyed state in Flink.
This includes, but is not limited to, any use of CheckpointedFunction or BroadcastState within an application.
When reading operator state, users specify the operator uid, the state name, and the type information.
Operator List State #
Operator state stored in a CheckpointedFunction using getListState can be read using ExistingSavepoint#readListState.
The state name and type information should match those used to define the ListStateDescriptor that declared this state in the DataStream application.
DataStream<Integer> listState = savepoint.readListState<>(
OperatorIdentifier.forUid("my-uid"),
"list-state",
Types.INT);
Operator Union List State #
Operator state stored in a CheckpointedFunction using getUnionListState can be read using ExistingSavepoint#readUnionState.
The state name and type information should match those used to define the ListStateDescriptor that declared this state in the DataStream application.
The framework will return a single copy of the state, equivalent to restoring a DataStream with parallelism 1.
DataStream<Integer> listState = savepoint.readUnionState<>(
OperatorIdentifier.forUid("my-uid"),
"union-state",
Types.INT);
Broadcast State #
BroadcastState can be read using ExistingSavepoint#readBroadcastState.
The state name and type information should match those used to define the MapStateDescriptor that declared this state in the DataStream application.
The framework will return a single copy of the state, equivalent to restoring a DataStream with parallelism 1.
DataStream<Tuple2<Integer, Integer>> broadcastState = savepoint.readBroadcastState<>(
OperatorIdentifier.forUid("my-uid"),
"broadcast-state",
Types.INT,
Types.INT);
Using Custom Serializers #
Each of the operator state readers support using custom TypeSerializers if one was used to define the StateDescriptor that wrote out the state.
DataStream<Integer> listState = savepoint.readListState<>(
OperatorIdentifier.forUid("uid"),
"list-state",
Types.INT,
new MyCustomIntSerializer());
Keyed State #
Keyed state, or partitioned state, is any state that is partitioned relative to a key.
When reading a keyed state, users specify the operator id and a KeyedStateReaderFunction<KeyType, OutputType>.
The KeyedStateReaderFunction allows users to read arbitrary columns and complex state types such as ListState, MapState, and AggregatingState.
This means if an operator contains a stateful process function such as:
public class StatefulFunctionWithTime extends KeyedProcessFunction<Integer, Integer, Void> {
ValueState<Integer> state;
ListState<Long> updateTimes;
@Override
public void open(OpenContext openContext) {
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("state", Types.INT);
state = getRuntimeContext().getState(stateDescriptor);
ListStateDescriptor<Long> updateDescriptor = new ListStateDescriptor<>("times", Types.LONG);
updateTimes = getRuntimeContext().getListState(updateDescriptor);
}
@Override
public void processElement(Integer value, Context ctx, Collector<Void> out) throws Exception {
state.update(value + 1);
updateTimes.add(System.currentTimeMillis());
}
}
Then it can read by defining an output type and corresponding KeyedStateReaderFunction.
DataStream<KeyedState> keyedState = savepoint.readKeyedState(OperatorIdentifier.forUid("my-uid"), new ReaderFunction());
public class KeyedState {
public int key;
public int value;
public List<Long> times;
}
public class ReaderFunction extends KeyedStateReaderFunction<Integer, KeyedState> {
ValueState<Integer> state;
ListState<Long> updateTimes;
@Override
public void open(OpenContext openContext) {
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("state", Types.INT);
state = getRuntimeContext().getState(stateDescriptor);
ListStateDescriptor<Long> updateDescriptor = new ListStateDescriptor<>("times", Types.LONG);
updateTimes = getRuntimeContext().getListState(updateDescriptor);
}
@Override
public void readKey(
Integer key,
Context ctx,
Collector<KeyedState> out) throws Exception {
KeyedState data = new KeyedState();
data.key = key;
data.value = state.value();
data.times = StreamSupport
.stream(updateTimes.get().spliterator(), false)
.collect(Collectors.toList());
out.collect(data);
}
}
Along with reading registered state values, each key has access to a Context with metadata such as registered event time and processing time timers.
Note: When using a KeyedStateReaderFunction, all state descriptors must be registered eagerly inside of open. Any attempt to call a RuntimeContext#get*State will result in a RuntimeException.
Window State #
The state processor api supports reading state from a window operator. When reading a window state, users specify the operator id, window assigner, and aggregation type.
Additionally, a WindowReaderFunction can be specified to enrich each read with additional information similar
to a WindowFunction or ProcessWindowFunction.
Suppose a DataStream application that counts the number of clicks per user per minute.
class Click {
public String userId;
public LocalDateTime time;
}
class ClickCounter implements AggregateFunction<Click, Integer, Integer> {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(Click value, Integer accumulator) {
return 1 + accumulator;
}
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
}
DataStream<Click> clicks = ...;
clicks
.keyBy(click -> click.userId)
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new ClickCounter())
.uid("click-window")
.addSink(new Sink());
This state can be read using the code below.
class ClickState {
public String userId;
public int count;
public TimeWindow window;
public Set<Long> triggerTimers;
}
class ClickReader extends WindowReaderFunction<Integer, ClickState, String, TimeWindow> {
@Override
public void readWindow(
String key,
Context<TimeWindow> context,
Iterable<Integer> elements,
Collector<ClickState> out) {
ClickState state = new ClickState();
state.userId = key;
state.count = elements.iterator().next();
state.window = context.window();
state.triggerTimers = context.registeredEventTimeTimers();
out.collect(state);
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SavepointReader savepoint = SavepointReader.read(env, "hdfs://checkpoint-dir", new HashMapStateBackend());
savepoint
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate("click-window", new ClickCounter(), new ClickReader(), Types.String, Types.INT, Types.INT)
.print();
Additionally, trigger state - from CountTriggers or custom triggers - can be read using the method
Context#triggerState inside the WindowReaderFunction.
Writing New Savepoints #
Savepoint’s may also be written, which allows such use cases as bootstrapping state based on historical data.
Each savepoint is made up of one or more StateBootstrapTransformation’s (explained below), each of which defines the state for an individual operator.
When using the SavepointWriter, your application must be executed under BATCH execution.
Note The state processor api does not currently provide a Scala API. As a result it will always auto-derive serializers using the Java type stack. To bootstrap a savepoint for the Scala DataStream API please manually pass in all type information.
int maxParallelism = 128;
SavepointWriter
.newSavepoint(env, new HashMapStateBackend(), maxParallelism)
.withOperator(OperatorIdentifier.forUid("uid1"), transformation1)
.withOperator(OperatorIdentifier.forUid("uid2"), transformation2)
.write(savepointPath);
The UIDs associated with each operator must match one to one with the UIDs assigned to the operators in your DataStream application; these are how Flink knows what state maps to which operator.
Operator State #
Simple operator state, using CheckpointedFunction, can be created using the StateBootstrapFunction.
public class SimpleBootstrapFunction extends StateBootstrapFunction<Integer> {
private ListState<Integer> state;
@Override
public void processElement(Integer value, Context ctx) throws Exception {
state.add(value);
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
state = context.getOperatorState().getListState(new ListStateDescriptor<>("state", Types.INT));
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Integer> data = env.fromElements(1, 2, 3);
StateBootstrapTransformation transformation = OperatorTransformation
.bootstrapWith(data)
.transform(new SimpleBootstrapFunction());
Broadcast State #
BroadcastState can be written using a BroadcastStateBootstrapFunction. Similar to broadcast state in the DataStream API, the full state must fit in memory.
public class CurrencyRate {
public String currency;
public Double rate;
}
public class CurrencyBootstrapFunction extends BroadcastStateBootstrapFunction<CurrencyRate> {
public static final MapStateDescriptor<String, Double> descriptor =
new MapStateDescriptor<>("currency-rates", Types.STRING, Types.DOUBLE);
@Override
public void processElement(CurrencyRate value, Context ctx) throws Exception {
ctx.getBroadcastState(descriptor).put(value.currency, value.rate);
}
}
DataStream<CurrencyRate> currencyDataSet = env.fromCollection(
new CurrencyRate("USD", 1.0), new CurrencyRate("EUR", 1.3));
StateBootstrapTransformation<CurrencyRate> broadcastTransformation = OperatorTransformation
.bootstrapWith(currencyDataSet)
.transform(new CurrencyBootstrapFunction());
Keyed State #
Keyed state for ProcessFunction’s and other RichFunction types can be written using a KeyedStateBootstrapFunction.
public class Account {
public int id;
public double amount;
public long timestamp;
}
public class AccountBootstrapper extends KeyedStateBootstrapFunction<Integer, Account> {
ValueState<Double> state;
@Override
public void open(OpenContext openContext) {
ValueStateDescriptor<Double> descriptor = new ValueStateDescriptor<>("total",Types.DOUBLE);
state = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(Account value, Context ctx) throws Exception {
state.update(value.amount);
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Account> accountDataSet = env.fromCollection(accounts);
StateBootstrapTransformation<Account> transformation = OperatorTransformation
.bootstrapWith(accountDataSet)
.keyBy(acc -> acc.id)
.transform(new AccountBootstrapper());
The KeyedStateBootstrapFunction supports setting event time and processing time timers.
The timers will not fire inside the bootstrap function and only become active once restored within a DataStream application.
If a processing time timer is set but the state is not restored until after that time has passed, the timer will fire immediately upon start.
Attention If your bootstrap function creates timers, the state can only be restored using one of the process type functions.
Window State #
The state processor api supports writing state for the window operator. When writing window state, users specify the operator id, window assigner, evictor, optional trigger, and aggregation type. It is important the configurations on the bootstrap transformation match the configurations on the DataStream window.
public class Account {
public int id;
public double amount;
public long timestamp;
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Account> accountDataSet = env.fromCollection(accounts);
StateBootstrapTransformation<Account> transformation = OperatorTransformation
.bootstrapWith(accountDataSet)
.keyBy(acc -> acc.id)
.window(TumblingEventTimeWindows.of(Time.minutes(5)))
.reduce((left, right) -> left + right);
Modifying Savepoints #
Besides creating a savepoint from scratch, you can base one off an existing savepoint such as when bootstrapping a single new operator for an existing job.
SavepointWriter
.fromExistingSavepoint(env, oldPath, new HashMapStateBackend())
.withOperator(OperatorIdentifier.forUid("uid"), transformation)
.write(newPath);
Changing UID (hashes) #
SavepointWriter#changeOperatorIdenfifier can be used to modify the UIDs or UID hash of an operator.
If a UID was not explicitly set (and was thus auto-generated and is effectively unknown), you can assign a UID provided that you know the UID hash (e.g., by parsing the logs):
savepointWriter
.changeOperatorIdentifier(
OperatorIdentifier.forUidHash("2feb7f8bcc404c3ac8a981959780bd78"),
OperatorIdentifier.forUid("new-uid"))
...
You can also replace one UID with another:
savepointWriter
.changeOperatorIdentifier(
OperatorIdentifier.forUid("old-uid"),
OperatorIdentifier.forUid("new-uid"))
...