This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
本地模式安装
本地模式安装 #
注意:Apache Flink 社区只发布 Apache Flink 的 release 版本。
由于你当前正在查看的是文档最新的 SNAPSHOT 版本,因此相关内容会被隐藏。请通过左侧菜单底部的版本选择将文档切换到最新的 release 版本。
请按照以下几个步骤下载最新的稳定版本开始使用。
步骤 1:下载 #
为了运行Flink,只需提前安装好 Java 11。你可以通过以下命令来检查 Java 是否已经安装正确。
java -version
下载 release 2.0-SNAPSHOT 并解压。
$ tar -xzf flink-2.0-SNAPSHOT-bin-scala_2.12.tgz
$ cd flink-2.0-SNAPSHOT-bin-scala_2.12
步骤 2:启动集群 #
Flink 附带了一个 bash 脚本,可以用于启动本地集群。
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
步骤 3:提交作业(Job) #
Flink 提供了一个 CLI 工具 bin/flink,它可以运行打包为 Java ARchives (JAR) 的程序,并控制其执行。 提交作业(//nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/glossary/#flink-job) 意味着将作业的 JAR 文件和相关依赖项上载到运行中的 Flink 集群并执行它。 并执行它。
Flink 的 Releases 附带了许多的示例作业。您可以在 examples/ 文件夹中找到。
要将字数统计作业示例部署到运行中的群集,请执行以下命令:
$ ./bin/flink run examples/streaming/WordCount.jar
您可以通过查看日志来验证输出结果:
$ tail log/flink-*-taskexecutor-*.out
输出示例:
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
另外,你可以通过 Flink 的 Web UI 来监视集群的状态和正在运行的作业。
您可以查看执行的数据流计划(data flow plan):
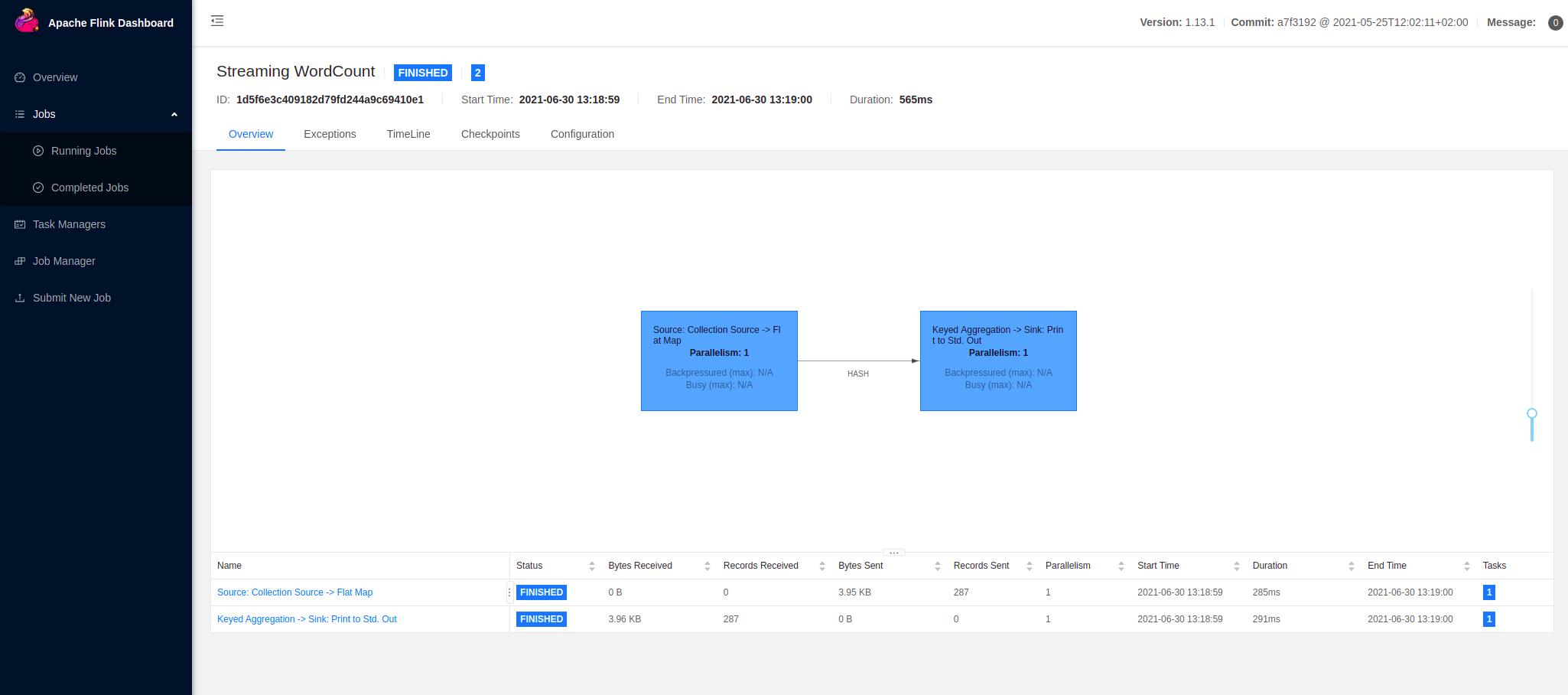
在这里,Flink 有两个操作符(operator)来执行作业。第一个操作符是源操作符,它从收集源中读取数据。 第二个运算符是转换运算符,用于汇总单词计数。了解更多信息,请参阅数据流操作符 。
您还可以查看任务执行的时间轴:
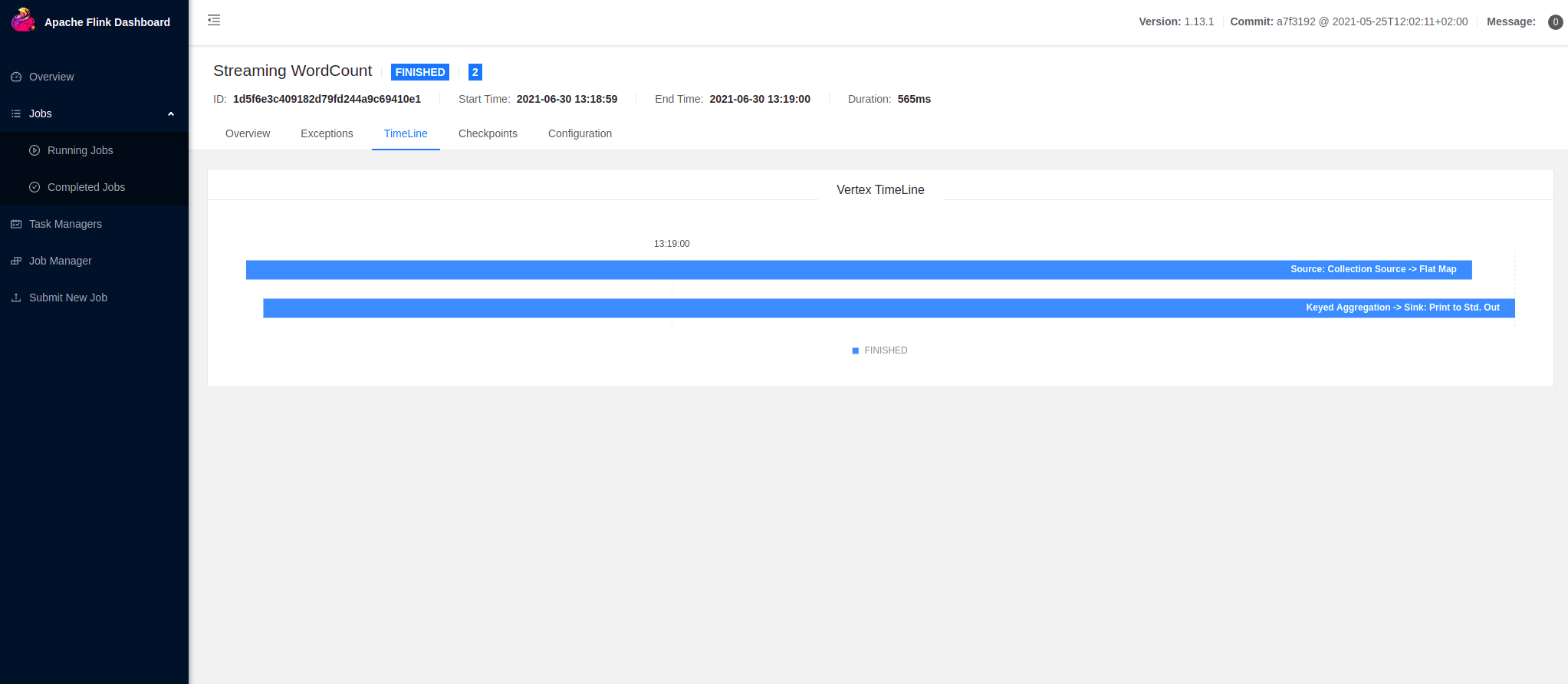
您已成功运行了 Flink 应用程序 ! 请从 examples/ 文件夹中选择任何其他 JAR 归档文件或部署您自己的作业!
步骤 4:停止集群 #
完成后,你可以快速停止集群和所有正在运行的组件。
$ ./bin/stop-cluster.sh