This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
First steps
First steps #
Welcome to Flink! :)
Flink is designed to process continuous streams of data at a lightning fast pace. This short guide will show you how to download the latest stable version of Flink, install, and run it. You will also run an example Flink job and view it in the web UI.
Downloading Flink #
Note: Flink is also available as a Docker image.
Flink runs on all UNIX-like environments, i.e. Linux, Mac OS X, and Cygwin (for Windows). You need to have Java 11 installed. To check the Java version installed, type in your terminal:
$ java -version
Next, download the latest binary release of Flink, then extract the archive:
$ tar -xzf flink-*.tgz
Browsing the project directory #
Navigate to the extracted directory and list the contents by issuing:
$ cd flink-* && ls -l
You should see something like:
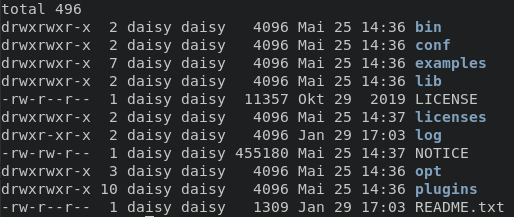
For now, you may want to note that:
- bin/ directory contains the
flinkbinary as well as several bash scripts that manage various jobs and tasks - conf/ directory contains configuration files, including Flink configuration file
- examples/ directory contains sample applications that can be used as is with Flink
Starting and stopping a local cluster #
To start a local cluster, run the bash script that comes with Flink:
$ ./bin/start-cluster.sh
You should see an output like this:

Flink is now running as a background process. You can check its status with the following command:
$ ps aux | grep flink
You should be able to navigate to the web UI at localhost:8081 to view the Flink dashboard and see that the cluster is up and running.
To quickly stop the cluster and all running components, you can use the provided script:
$ ./bin/stop-cluster.sh
Submitting a Flink job #
Flink provides a CLI tool, bin/flink, that can run programs packaged as Java ARchives (JAR) and control their execution. Submitting a job means uploading the job’s JAR file and related dependencies to the running Flink cluster and executing it.
Flink releases come with example jobs, which you can find in the examples/ folder.
To deploy the example word count job to the running cluster, issue the following command:
$ ./bin/flink run examples/streaming/WordCount.jar
You can verify the output by viewing the logs:
$ tail log/flink-*-taskexecutor-*.out
Sample output:
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
Additionally, you can check Flink’s web UI to monitor the status of the cluster and running job.
You can view the data flow plan for the execution:
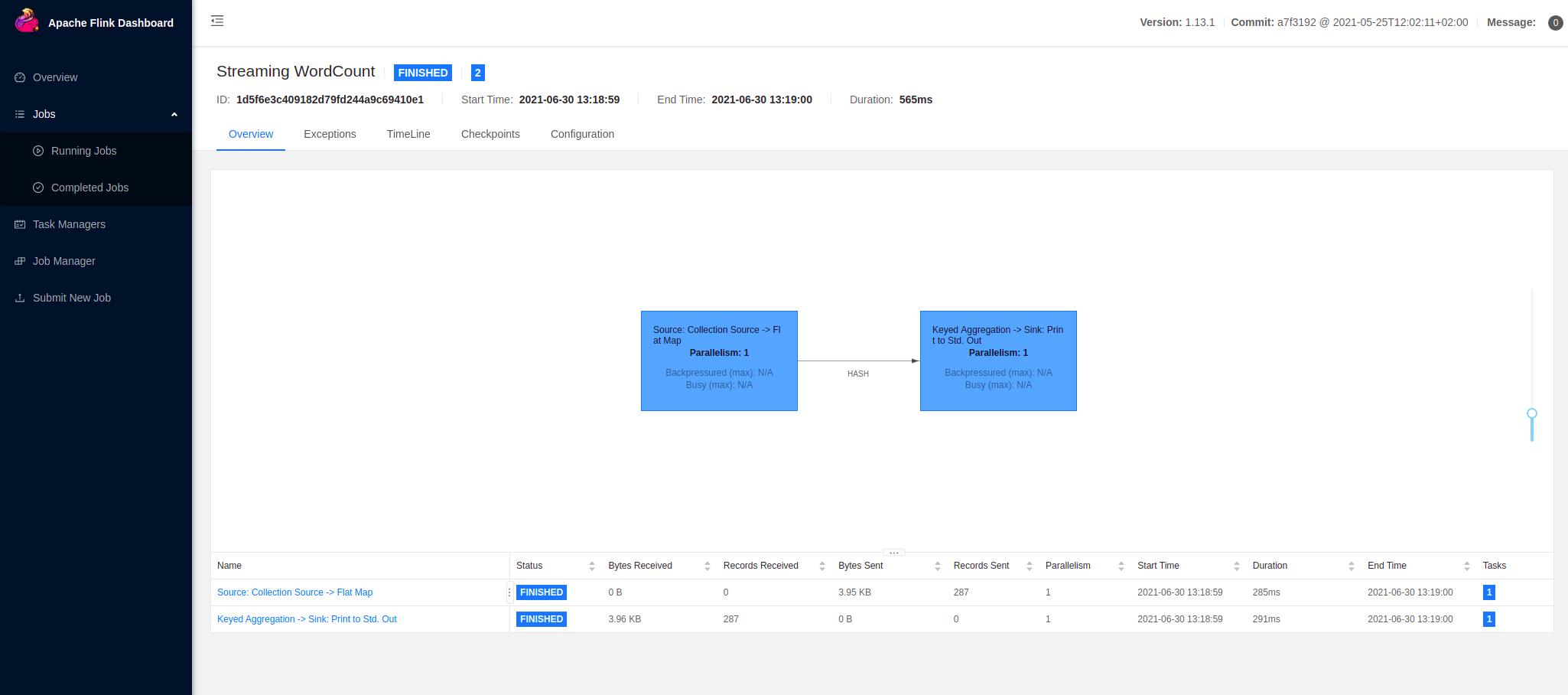
Here for the job execution, Flink has two operators. The first is the source operator which reads data from the collection source. The second operator is the transformation operator which aggregates counts of words. Learn more about DataStream operators.
You can also look at the timeline of the job execution:
You have successfully ran a Flink application! Feel free to select any other JAR archive from the examples/ folder or deploy your own job!
Summary #
In this guide, you downloaded Flink, explored the project directory, started and stopped a local cluster, and submitted a sample Flink job!
To learn more about Flink fundamentals, check out the concepts section. If you want to try something more hands-on, try one of the tutorials.