Streaming Concepts #
Flink’s Table API and SQL support are unified APIs for batch and stream processing. This means that Table API and SQL queries have the same semantics regardless whether their input is bounded batch input or unbounded stream input.
The following pages explain concepts, practical limitations, and stream-specific configuration parameters of Flink’s relational APIs on streaming data.
State Management #
Table programs that run in streaming mode leverage all capabilities of Flink as a stateful stream processor.
In particular, a table program can be configured with a state backend and various checkpointing options for handling different requirements regarding state size and fault tolerance. It is possible to take a savepoint of a running Table API & SQL pipeline and to restore the application’s state at a later point in time.
State Usage #
Due to the declarative nature of Table API & SQL programs, it is not always obvious where and how much state is used within a pipeline. The planner decides whether state is necessary to compute a correct result. A pipeline is optimized to claim as little state as possible given the current set of optimizer rules.
Conceptually, source tables are never kept entirely in state. An implementer deals with logical tables (i.e. dynamic tables). Their state requirements depend on the used operations.
Stateful Operators #
Queries contain stateful operations such as joins, aggregations, or deduplication require keeping intermediate results in a fault-tolerant storage for which Flink’s state abstractions are used.
For example, a regular SQL join of two tables requires the operator to keep both input tables in state entirely. For correct SQL semantics, the runtime needs to assume that a matching could occur at any point in time from both sides. Flink provides optimized window and interval joins that aim to keep the state size small by exploiting the concept of watermarks.
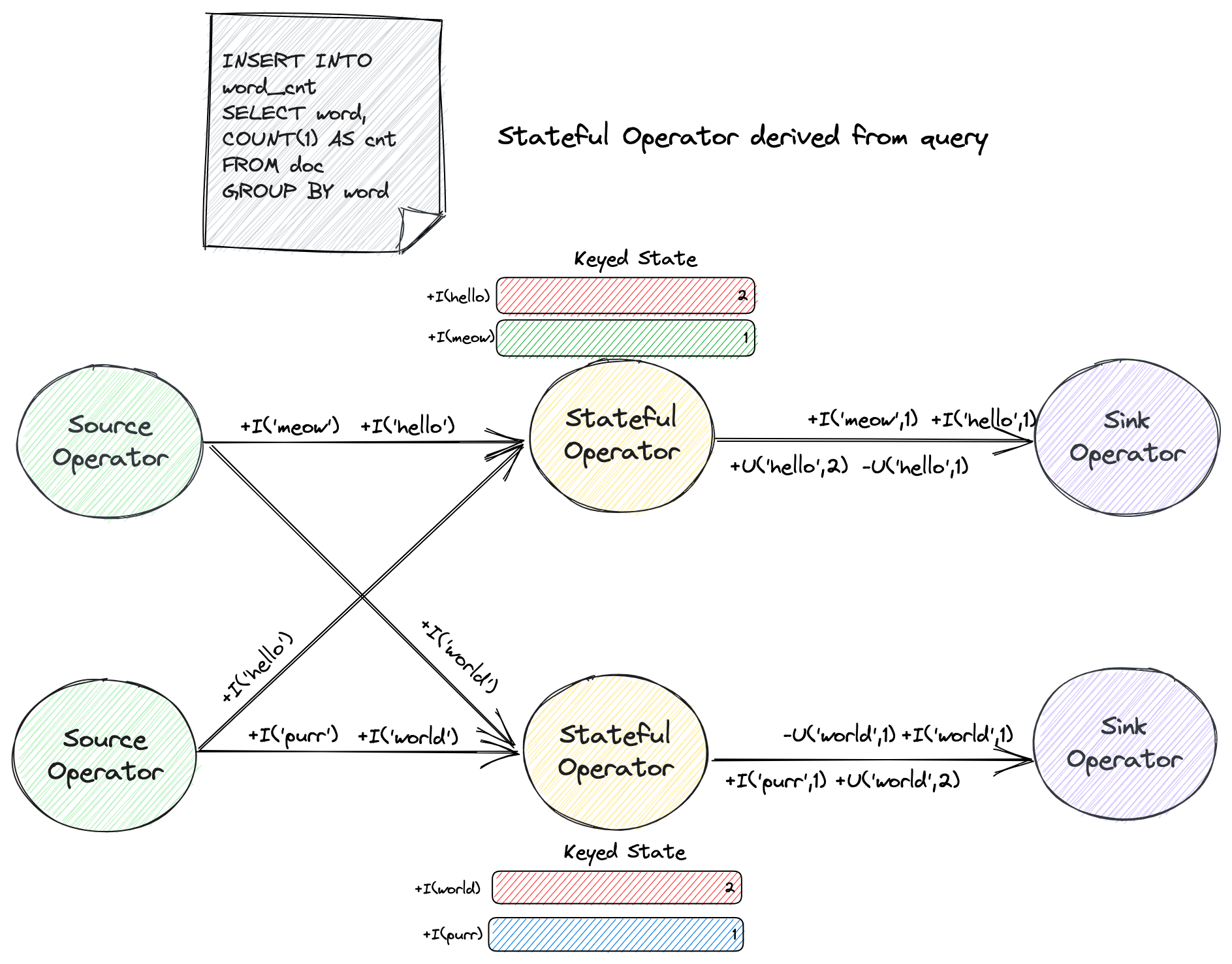
Another example is the following query that computes the word count.
CREATE TABLE doc (
word STRING
) WITH (
'connector' = '...'
);
CREATE TABLE word_cnt (
word STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
) WITH (
'connector' = '...'
);
INSERT INTO word_cnt
SELECT word, COUNT(1) AS cnt
FROM doc
GROUP BY word;
The word field is used as a grouping key, and the continuous query writes a count
for each word it observes to the sink.
The word value is evolving over time, and due to the continuous query never ends, the framework needs to maintain a count for each observed word value.
Consequently, the total state size of the query is continuously growing as more and more word values are observed.
Queries such as SELECT ... FROM ... WHERE which only consist of field projections or filters are usually
stateless pipelines.
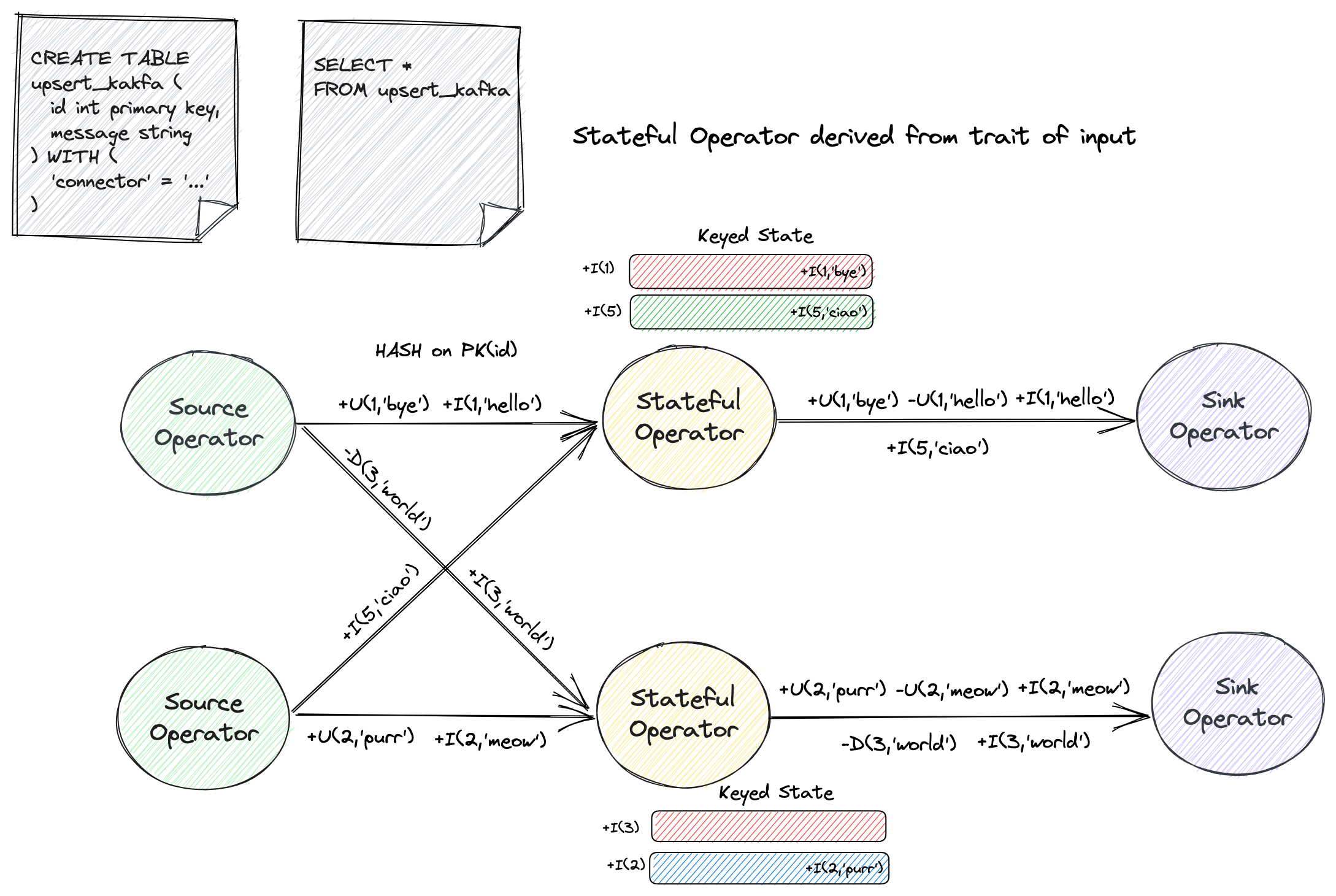
However, under some situations, the stateful operation is implicitly derived through the trait of input (e.g., input is a changelog without UPDATE_BEFORE, see
Table to Stream Conversion),
or through user configuration (see table-exec-source-cdc-events-duplicate).
The following figure illustrates a SELECT ... FROM statement that querying an upsert kafka source.
CREATE TABLE upsert_kakfa (
id INT PRIMARY KEY NOT ENFORCED,
message STRING
) WITH (
'connector' = 'upsert-kafka',
...
);
SELECT * FROM upsert_kakfa;
The table source only provides messages with INSERT, UPDATE_AFTER and DELETE type, while the downstream sink requires a complete changelog (including UPDATE_BEFORE).
As a result, although this query itself does not involve explicit stateful calculation, the planner still generates a stateful operator called “ChangelogNormalize” to help obtain the complete changelog.
Please refer to the individual operator documentation for more details about how much state is required and how to limit a potentially ever-growing state size.
Idle State Retention Time #
The Idle State Retention Time parameter table.exec.state.ttl
defines for how long the state of a key is retained without being updated before it is removed.
For the previous example query, the count of a word would be removed as soon as it has not
been updated for the configured period of time.
By removing the state of a key, the continuous query completely forgets that it has seen this key
before. If a record with a key, whose state has been removed before, is processed, the record will
be treated as if it was the first record with the respective key. For the example above this means
that the count of a word would start again at 0.
Different Ways to Configure State TTL #
| Configuration | TableAPI/SQL Support | Granularity | Priority |
|---|---|---|---|
| SET 'table.exec.state.ttl' = '...' | TableAPI SQL | Pipeline level, all stateful operators will use the value by default. | This is the default state TTL configuration and can be overridden by enabling the STATE_TTL hint or modifying the value of the serialized CompiledPlan. |
| SELECT /*+ STATE_TTL(...) */ ... | SQL | Operator level with only regular join and group aggregation support. | The hint precedes the default table.exec.state.ttl. This value will be serialized to the CompiledPlan during the plan translation phase. See more at State TTL Hint. |
| Modify serialized JSON content of CompiledPlan | TableAPI SQL | Operator level with a generalized support. The TTL for each stateful operator is explicitly serialized as an entry of the JSON. Modifying the JSON file can change the TTL for any stateful operator. | The TTL in CompiledPlan derives from either table.exec.state.ttl or STATE_TTL hint. If the job is submitted via CompiledPlan, the ultimate TTL value is decided by the last modified state metadata. |
Configure Operator-level State TTL #
This is an advanced feature and should be used with caution. It is only suitable for the cases
in which there are multiple states used in the pipeline,
and you need to set different TTL (Time-to-Live) for each state.
If the pipeline does not involve stateful computations, you do not need to follow this procedure.
If the pipeline only uses one state, you only need to set table.exec.state.ttl
at pipeline level.
Table API & SQL supports configuring fine-grained state TTL at operator-level to improve the state usage.
The configurable granularity is defined as the number of incoming input edges for each state operator.
Specifically, OneInputStreamOperator can configure the TTL for one state, while TwoInputStreamOperator (such as regular join), which has two inputs, can configure the TTL for the left and right states separately.
More generally, for MultipleInputStreamOperator which has K inputs, K state TTLs can be configured.
Typical use cases are as follows:
- Set different TTLs for regular joins.
Regular join generates a
TwoInputStreamOperatorwith left state to keep left input and right state to keep right input. You can set the different state TTL for left state and right state. - Set different TTLs for different transformations within one pipeline.
For example, there is an ETL pipeline which uses
ROW_NUMBERto perform deduplication, and then useGROUP BYto perform aggregation. This table program will generate twoOneInputStreamOperators with their own states. Now you can set different state TTL for deduplicate state and aggregate state.
Window-based operations (like Window Join, Window Aggregation, Window Top-N etc.) and Interval Joins do not rely on table.exec.state.ttl to control the state retention, and their state TTLs cannot be configured at operator-level.
Generate a Compiled Plan
The setup process begins by generating a JSON file using the COMPILE PLAN statement,
which represents the serialized execution plan of the current table program.
Currently,COMPILE PLANstatement does not supportSELECT... FROM...queries.
- Run a
COMPILE PLANstatement
TableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode());
tableEnv.executeSql(
"CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)");
tableEnv.executeSql(
"CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)");
tableEnv.executeSql(
"CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)");
// CompilePlan#writeToFile only supports a local file path, if you need to write to remote filesystem,
// please use tableEnv.executeSql("COMPILE PLAN 'hdfs://path/to/plan.json' FOR ...")
CompiledPlan compiledPlan =
tableEnv.compilePlanSql(
"INSERT INTO enriched_orders \n"
+ "SELECT a.order_id, a.order_line_id, b.order_status, ... \n"
+ "FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id");
compiledPlan.writeToFile("/path/to/plan.json");
val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode())
tableEnv.executeSql(
"CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)")
tableEnv.executeSql(
"CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)")
tableEnv.executeSql(
"CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)")
val compiledPlan =
tableEnv.compilePlanSql(
"""
|INSERT INTO enriched_orders
|SELECT a.order_id, a.order_line_id, b.order_status, ...
|FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id
|""".stripMargin)
// CompilePlan#writeToFile only supports a local file path, if you need to write to remote filesystem,
// please use tableEnv.executeSql("COMPILE PLAN 'hdfs://path/to/plan.json' FOR ...")
compiledPlan.writeToFile("/path/to/plan.json")
Flink SQL> CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...);
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...);
[INFO] Execute statement succeed.
Flink SQL> CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...);
[INFO] Execute statement succeed.
Flink SQL> COMPILE PLAN 'file:///path/to/plan.json' FOR INSERT INTO enriched_orders
> SELECT a.order_id, a.order_line_id, b.order_status, ...
> FROM orders a JOIN line_orders b ON a.order_line_id = b.order_line_id;
[INFO] Execute statement succeed.
-
SQL Syntax
COMPILE PLAN [IF NOT EXISTS] <plan_file_path> FOR <insert_statement>|<statement_set>; statement_set: EXECUTE STATEMENT SET BEGIN insert_statement; ... insert_statement; END; insert_statement: <insert_from_select>|<insert_from_values>This will generate a JSON file at
/path/to/plan.json.
COMPILE PLANstatement supports writing the plan to a remote filesystem scheme likehdfs://ors3://. Please be sure that the target path has set up the write access.
Modify the Compiled Plan
Every operator that uses state will explicitly generate a JSON array named “state” with the following structure. Theoretically, A k-th input stream operator will have k-th state.
"state": [
{
"index": 0,
"ttl": "0 ms",
"name": "${1st input state name}"
},
{
"index": 1,
"ttl": "0 ms",
"name": "${2nd input state name}"
},
...
]
Locate the operator you need to modify, change the value of the TTL to a positive integer, and pay attention to including the time unit “ms”. For example, if you want to set 1 hour as TTL for the state, you can modify the JSON like the following:
{
"index": 0,
"ttl": "3600000 ms",
"name": "${1st input state name}"
}
Save the file, and then use the EXECUTE PLAN statement to submit your job.
Conceptually, the TTL of downstream stateful operator should be greater than or equal to the TTL of upstream stateful operator.
Execute the Compiled Plan
EXECUTE PLAN statement will deserialize the specified file back to execution plan of the current table program and then submit the job.
The job submitted via EXECUTE PLAN statement will apply state TTL read from the file, instead of the configuration table.exec.state.ttl.
-
Run an
EXECUTE PLANstatementTableEnvironment tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode()); tableEnv.executeSql( "CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)"); tableEnv.executeSql( "CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)"); tableEnv.executeSql( "CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)"); // PlanReference#fromFile only supports a local file path, if you need to read from remote filesystem, // please use tableEnv.executeSql("EXECUTE PLAN 'hdfs://path/to/plan.json'").await(); tableEnv.loadPlan(PlanReference.fromFile("/path/to/plan.json")).execute().await();val tableEnv = TableEnvironment.create(EnvironmentSettings.inStreamingMode()) tableEnv.executeSql( "CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...)") tableEnv.executeSql( "CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...)") tableEnv.executeSql( "CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...)") // PlanReference#fromFile only supports a local file path, if you need to read from remote filesystem, // please use tableEnv.executeSql("EXECUTE PLAN 'hdfs://path/to/plan.json'").await() tableEnv.loadPlan(PlanReference.fromFile("/path/to/plan.json")).execute().await()Flink SQL> CREATE TABLE orders (order_id BIGINT, order_line_id BIGINT, buyer_id BIGINT, ...); [INFO] Execute statement succeed. Flink SQL> CREATE TABLE line_orders (order_line_id BIGINT, order_status TINYINT, ...); [INFO] Execute statement succeed. Flink SQL> CREATE TABLE enriched_orders (order_id BIGINT, order_line_id BIGINT, order_status TINYINT, ...); [INFO] Execute statement succeed. Flink SQL> EXECUTE PLAN 'file:///path/to/plan.json'; [INFO] Submitting SQL update statement to the cluster... [INFO] SQL update statement has been successfully submitted to the cluster: Job ID: 79fbe3fa497e4689165dd81b1d225ea8 -
SQL Syntax
EXECUTE PLAN [IF EXISTS] <plan_file_path>;This will deserialize the JSON file and submit an insert statement job.
A Full Example
The following table program computes the enriched order shipment information. It performs a regular inner join with different state TTL for left and right side.
-
Generate compiled plan
-- left source table CREATE TABLE Orders ( `order_id` INT, `line_order_id` INT ) WITH ( 'connector'='...' ); -- right source table CREATE TABLE LineOrders ( `line_order_id` INT, `ship_mode` STRING ) WITH ( 'connector'='...' ); -- sink table CREATE TABLE OrdersShipInfo ( `order_id` INT, `line_order_id` INT, `ship_mode` STRING ) WITH ( 'connector' = '...' ); COMPILE PLAN '/path/to/plan.json' FOR INSERT INTO OrdersShipInfo SELECT a.order_id, a.line_order_id, b.ship_mode FROM Orders a JOIN LineOrders b ON a.line_order_id = b.line_order_id;The generated JSON file has the following contents:
{ "flinkVersion" : "1.18", "nodes" : [ { "id" : 1, "type" : "stream-exec-table-source-scan_1", "scanTableSource" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`Orders`", "resolvedTable" : { ... } } }, "outputType" : "ROW<`order_id` INT, `line_order_id` INT>", "description" : "TableSourceScan(table=[[default_catalog, default_database, Orders]], fields=[order_id, line_order_id])", "inputProperties" : [ ] }, { "id" : 2, "type" : "stream-exec-exchange_1", "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT>", "description" : "Exchange(distribution=[hash[line_order_id]])" }, { "id" : 3, "type" : "stream-exec-table-source-scan_1", "scanTableSource" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`LineOrders`", "resolvedTable" : {...} } }, "outputType" : "ROW<`line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "TableSourceScan(table=[[default_catalog, default_database, LineOrders]], fields=[line_order_id, ship_mode])", "inputProperties" : [ ] }, { "id" : 4, "type" : "stream-exec-exchange_1", "inputProperties" : [ ... ], "outputType" : "ROW<`line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Exchange(distribution=[hash[line_order_id]])" }, { "id" : 5, "type" : "stream-exec-join_1", "joinSpec" : { ... }, "state" : [ { "index" : 0, "ttl" : "0 ms", "name" : "leftState" }, { "index" : 1, "ttl" : "0 ms", "name" : "rightState" } ], "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `line_order_id0` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Join(joinType=[InnerJoin], where=[(line_order_id = line_order_id0)], select=[order_id, line_order_id, line_order_id0, ship_mode], leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey])" }, { "id" : 6, "type" : "stream-exec-calc_1", "projection" : [ ... ], "condition" : null, "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Calc(select=[order_id, line_order_id, ship_mode])" }, { "id" : 7, "type" : "stream-exec-sink_1", "configuration" : { ... }, "dynamicTableSink" : { "table" : { "identifier" : "`default_catalog`.`default_database`.`OrdersShipInfo`", "resolvedTable" : { ... } } }, "inputChangelogMode" : [ "INSERT" ], "inputProperties" : [ ... ], "outputType" : "ROW<`order_id` INT, `line_order_id` INT, `ship_mode` VARCHAR(2147483647)>", "description" : "Sink(table=[default_catalog.default_database.OrdersShipInfo], fields=[order_id, line_order_id, ship_mode])" } ], "edges" : [ ... ] } -
Modify the plan content and execute plan
The JSON representation for join operator’s state has the following structure:
"state": [ { "index": 0, "ttl": "0 ms", "name": "leftState" }, { "index": 1, "ttl": "0 ms", "name": "rightState" } ]The
"index"indicates the current state is the i-th input the operator, and the index starts from zero. The current TTL value for both left and right side is"0 ms", which means the state never expires. Now change the value of left state to"3000 ms"and right state to"9000 ms"."state": [ { "index": 0, "ttl": "3000 ms", "name": "leftState" }, { "index": 1, "ttl": "9000 ms", "name": "rightState" } ]Save the changes made on the file and then execute the plan.
EXECUTE PLAN '/path/to/plan.json'
Stateful Upgrades and Evolution #
Table programs that are executed in streaming mode are intended as standing queries which means they are defined once and are continuously evaluated as static end-to-end pipelines.
In case of stateful pipelines, any change to both the query or Flink’s planner might lead to a completely different execution plan. This makes stateful upgrades and the evolution of table programs challenging at the moment. The community is working on improving those shortcomings.
For example, by adding a filter predicate, the optimizer might decide to reorder joins or change the schema of an intermediate operator. This prevents restoring from a savepoint due to either changed topology or different column layout within the state of an operator.
The query implementer must ensure that the optimized plans before and after the change are compatible.
Use the EXPLAIN command in SQL or table.explain() in Table API to get insights.
Since new optimizer rules are continuously added, and operators become more efficient and specialized, also the upgrade to a newer Flink version could lead to incompatible plans.
Currently, the framework cannot guarantee that state can be mapped from a savepoint to a new table operator topology.
In other words: Savepoints are only supported if both the query and the Flink version remain constant.
Since the community rejects contributions that modify the optimized plan and the operator topology
in a patch version (e.g. from 1.13.1 to 1.13.2), it should be safe to upgrade a Table API & SQL
pipeline to a newer bug fix release. However, major-minor upgrades from (e.g. from 1.12 to 1.13)
are not supported.
For both shortcomings (i.e. modified query and modified Flink version), we recommend to investigate whether the state of an updated table program can be “warmed up” (i.e. initialized) with historical data again before switching to real-time data. The Flink community is working on a hybrid source to make this switching as convenient as possible.
Where to go next? #
- Dynamic Tables: Describes the concept of dynamic tables.
- Time attributes: Explains time attributes and how time attributes are handled in Table API & SQL.
- Versioned Tables: Describes the Temporal Table concept.
- Joins in Continuous Queries: Different supported types of Joins in Continuous Queries.
- Determinism in Continuous Queries: Determinism in Continuous Queries.
- Query configuration: Lists Table API & SQL specific configuration options.