HiveServer2 Endpoint #
The Flink SQL Gateway supports deploying as a HiveServer2 Endpoint which is compatible with HiveServer2 wire protocol. This allows users to submit Hive-dialect SQL through the Flink SQL Gateway with existing Hive clients using Thrift or the Hive JDBC driver. These clients include Beeline, DBeaver, Apache Superset and so on.
It is recommended to use the HiveServer2 Endpoint with a Hive Catalog and Hive dialect to get the same experience as HiveServer2. Please refer to Hive Dialect for more details.
Setting Up #
Before the trip of the SQL Gateway with the HiveServer2 Endpoint, please prepare the required dependencies.
Configure HiveServer2 Endpoint #
The HiveServer2 Endpoint is not the default endpoint for the SQL Gateway. You can configure to use the HiveServer2 Endpoint by calling
$ ./bin/sql-gateway.sh start -Dsql-gateway.endpoint.type=hiveserver2 -Dsql-gateway.endpoint.hiveserver2.catalog.hive-conf-dir=<path to hive conf>
or add the following configuration into Flink configuration file (please replace the <path to hive conf> with your hive conf path).
sql-gateway.endpoint.type: hiveserver2
sql-gateway.endpoint.hiveserver2.catalog.hive-conf-dir: <path to hive conf>
Connecting to HiveServer2 #
After starting the SQL Gateway, you are able to submit SQL with Apache Hive Beeline.
$ ./beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/ohmeatball/Work/hive-related/apache-hive-2.3.9-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/Cellar/hadoop/3.2.1_1/libexec/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.9 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000/default;auth=noSasl
Connecting to jdbc:hive2://localhost:10000/default;auth=noSasl
Enter username for jdbc:hive2://localhost:10000/default:
Enter password for jdbc:hive2://localhost:10000/default:
Connected to: Apache Flink (version 1.16)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000/default> CREATE TABLE Source (
. . . . . . . . . . . . . . . . . . . .> a INT,
. . . . . . . . . . . . . . . . . . . .> b STRING
. . . . . . . . . . . . . . . . . . . .> );
+---------+
| result |
+---------+
| OK |
+---------+
0: jdbc:hive2://localhost:10000/default> CREATE TABLE Sink (
. . . . . . . . . . . . . . . . . . . .> a INT,
. . . . . . . . . . . . . . . . . . . .> b STRING
. . . . . . . . . . . . . . . . . . . .> );
+---------+
| result |
+---------+
| OK |
+---------+
0: jdbc:hive2://localhost:10000/default> INSERT INTO Sink SELECT * FROM Source;
+-----------------------------------+
| job id |
+-----------------------------------+
| 55ff290b57829998ea6e9acc240a0676 |
+-----------------------------------+
1 row selected (2.427 seconds)
Endpoint Options #
Below are the options supported when creating a HiveServer2 Endpoint instance with YAML file or DDL.
| Key | Required | Default | Type | Description |
|---|---|---|---|---|
sql-gateway.endpoint.type |
required | "rest" | List<String> | Specify which endpoint to use, here should be 'hiveserver2'. |
sql-gateway.endpoint.hiveserver2.catalog.hive-conf-dir |
required | (none) | String | URI to your Hive conf dir containing hive-site.xml. The URI needs to be supported by Hadoop FileSystem. If the URI is relative, i.e. without a scheme, local file system is assumed. If the option is not specified, hive-site.xml is searched in class path. |
sql-gateway.endpoint.hiveserver2.catalog.default-database |
optional | "default" | String | The default database to use when the catalog is set as the current catalog. |
sql-gateway.endpoint.hiveserver2.catalog.name |
optional | "hive" | String | Name for the pre-registered hive catalog. |
sql-gateway.endpoint.hiveserver2.module.name |
optional | "hive" | String | Name for the pre-registered hive module. |
sql-gateway.endpoint.hiveserver2.thrift.exponential.backoff.slot.length |
optional | 100 ms | Duration | Binary exponential backoff slot time for Thrift clients during login to HiveServer2,for retries until hitting Thrift client timeout |
sql-gateway.endpoint.hiveserver2.thrift.host |
optional | (none) | String | The server address of HiveServer2 host to be used for communication.Default is empty, which means the to bind to the localhost. This is only necessary if the host has multiple network addresses. |
sql-gateway.endpoint.hiveserver2.thrift.login.timeout |
optional | 20 s | Duration | Timeout for Thrift clients during login to HiveServer2 |
sql-gateway.endpoint.hiveserver2.thrift.max.message.size |
optional | 104857600 | Long | Maximum message size in bytes a HS2 server will accept. |
sql-gateway.endpoint.hiveserver2.thrift.port |
optional | 10000 | Integer | The port of the HiveServer2 endpoint. |
sql-gateway.endpoint.hiveserver2.thrift.worker.keepalive-time |
optional | 1 min | Duration | Keepalive time for an idle worker thread. When the number of workers exceeds min workers, excessive threads are killed after this time interval. |
sql-gateway.endpoint.hiveserver2.thrift.worker.threads.max |
optional | 512 | Integer | The maximum number of Thrift worker threads |
sql-gateway.endpoint.hiveserver2.thrift.worker.threads.min |
optional | 5 | Integer | The minimum number of Thrift worker threads |
HiveServer2 Protocol Compatibility #
The Flink SQL Gateway with HiveServer2 Endpoint aims to provide the same experience compared to the HiveServer2 of Apache Hive. Therefore, HiveServer2 Endpoint automatically initialize the environment to have more consistent experience for Hive users:
- create the Hive Catalog as the default catalog;
- use Hive built-in function by loading Hive function module and place it first in the function module list;
- switch to the Hive dialect (
table.sql-dialect = hive); - switch to batch execution mode (
execution.runtime-mode = BATCH); - execute DML statements (e.g. INSERT INTO) blocking and one by one (
table.dml-sync = true).
With these essential prerequisites, you can submit the Hive SQL in Hive style but execute it in the Flink environment.
Clients & Tools #
The HiveServer2 Endpoint is compatible with the HiveServer2 wire protocol. Therefore, the tools that manage the Hive SQL also work for the SQL Gateway with the HiveServer2 Endpoint. Currently, Hive JDBC, Hive Beeline, Dbeaver, Apache Superset and so on are tested to be able to connect to the Flink SQL Gateway with HiveServer2 Endpoint and submit SQL.
Hive JDBC #
SQL Gateway is compatible with HiveServer2. You can write a program that uses Hive JDBC to connect to SQL Gateway. To build the program, add the following dependencies in your project pom.xml.
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
</dependency>
After reimport the dependencies, you can use the following program to connect and list tables in the Hive Catalog.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class JdbcConnection {
public static void main(String[] args) throws Exception {
try (
// Please replace the JDBC URI with your actual host, port and database.
Connection connection = DriverManager.getConnection("jdbc:hive2://{host}:{port}/{database};auth=noSasl");
Statement statement = connection.createStatement()) {
statement.execute("SHOW TABLES");
ResultSet resultSet = statement.getResultSet();
while (resultSet.next()) {
System.out.println(resultSet.getString(1));
}
}
}
}
DBeaver #
DBeaver uses Hive JDBC to connect to the HiveServer2. So DBeaver can connect to the Flink SQL Gateway to submit Hive SQL. Considering the API compatibility, you can connect to the Flink SQL Gateway like HiveServer2. Please refer to the guidance about how to use DBeaver to connect to the Flink SQL Gateway with the HiveServer2 Endpoint.
Attention Currently, HiveServer2 Endpoint doesn’t support authentication. Please use the following JDBC URL to connect to the DBeaver:
jdbc:hive2://{host}:{port}/{database};auth=noSasl
After the setup, you can explore Flink with DBeaver.
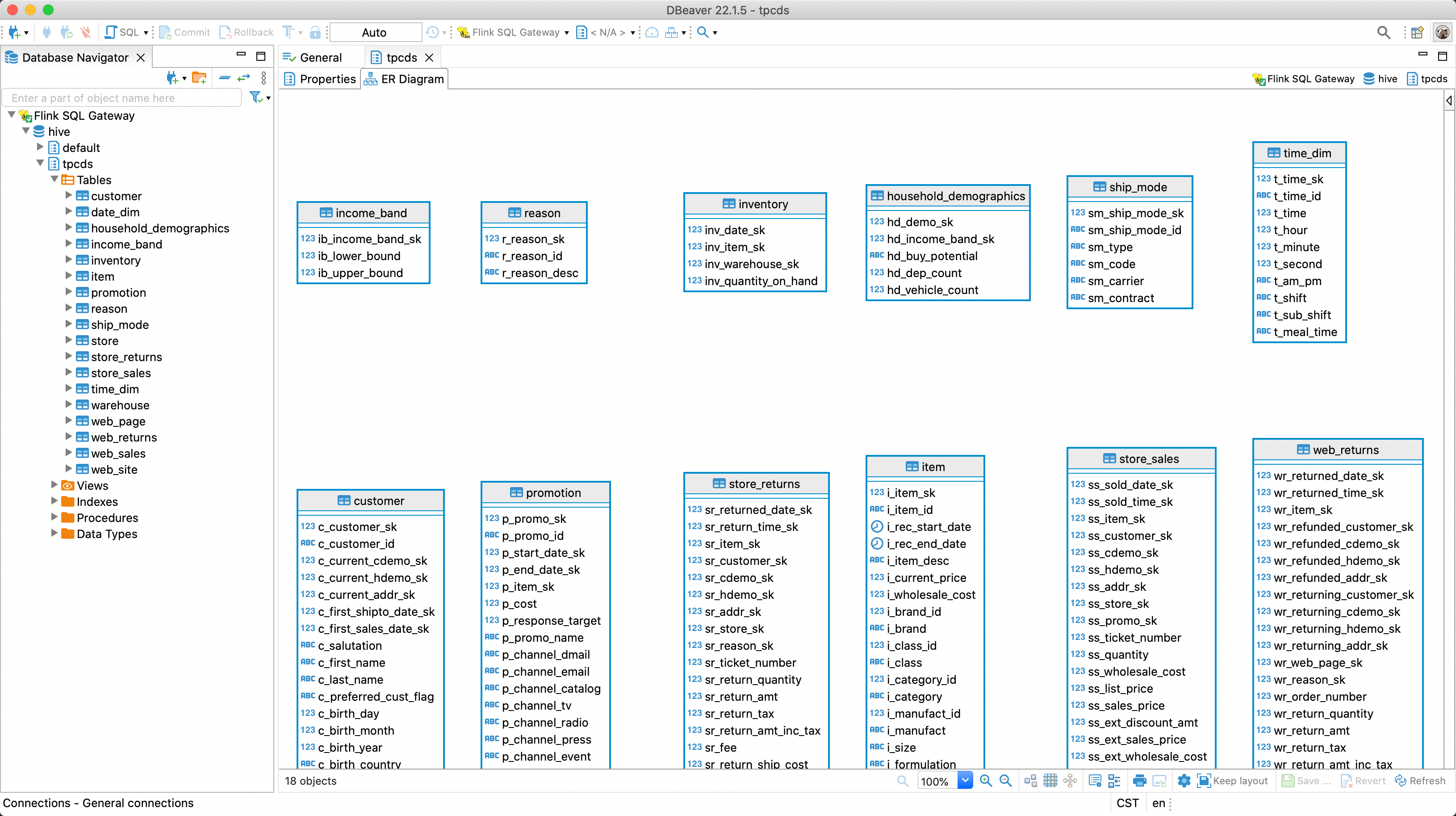
Apache Superset #
Apache Superset is a powerful data exploration and visualization platform. With the API compatibility, you can connect to the Flink SQL Gateway like Hive. Please refer to the guidance for more details.
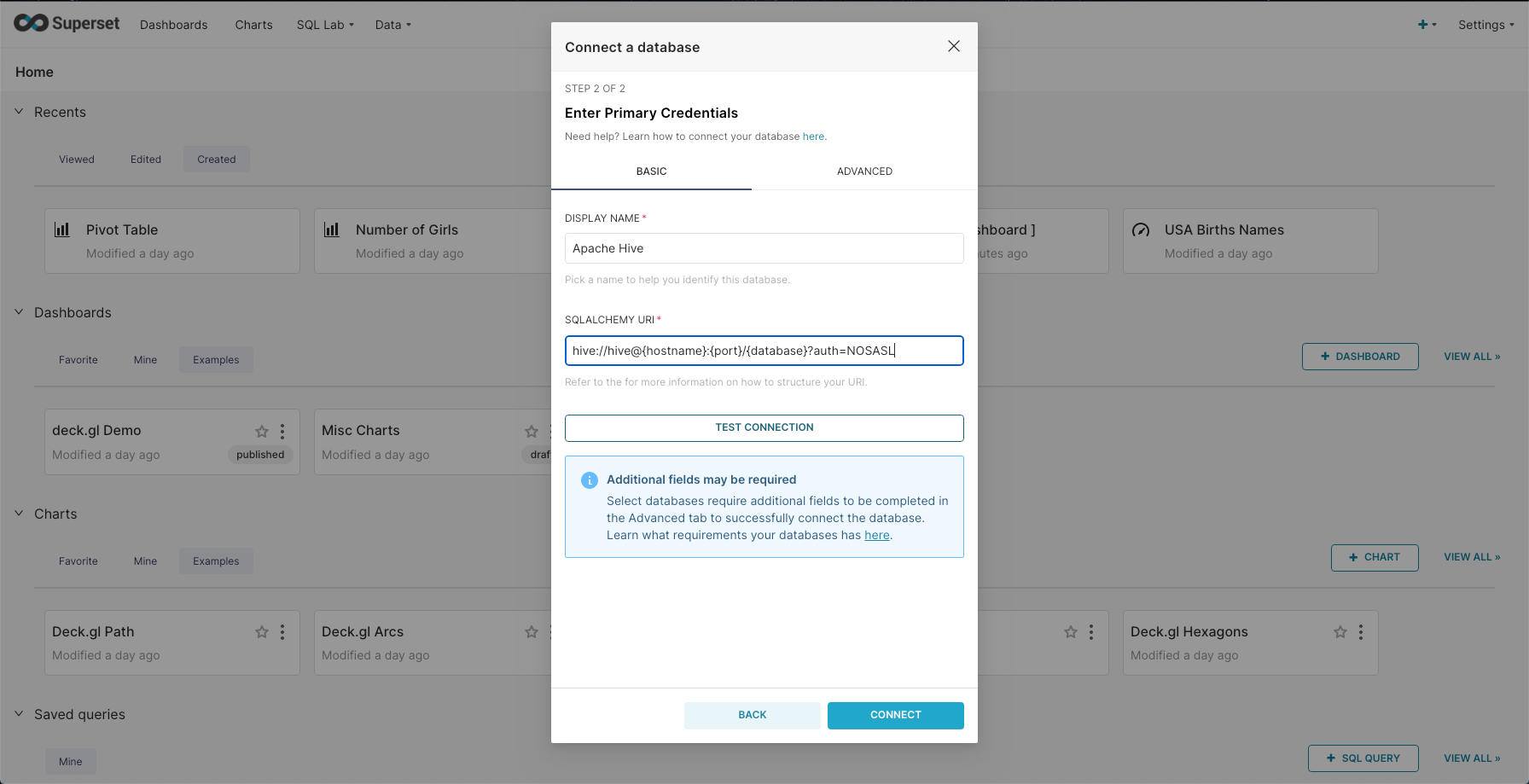
Attention Currently, HiveServer2 Endpoint doesn’t support authentication. Please use the following JDBC URL to connect to the Apache Superset:
hive://hive@{host}:{port}/{database}?auth=NOSASL
Streaming SQL #
Flink is a batch-streaming unified engine. You can switch to the streaming SQL with the following SQL
SET table.sql-dialect=default;
SET execution.runtime-mode=streaming;
SET table.dml-sync=false;
After that, the environment is ready to parse the Flink SQL, optimize with the streaming planner and submit the job in async mode.
Notice: TheRowKindin the HiveServer2 API is alwaysINSERT. Therefore, HiveServer2 Endpoint doesn’t support to present the CDC data.
Supported Types #
The HiveServer2 Endpoint is built on the Hive2 now and supports all Hive2 available types. For Hive-compatible tables, the HiveServer2 Endpoint obeys the same rule as the HiveCatalog to convert the Flink types to Hive Types and serialize them to the thrift object. Please refer to the HiveCatalog for the type mappings.