Introduction #
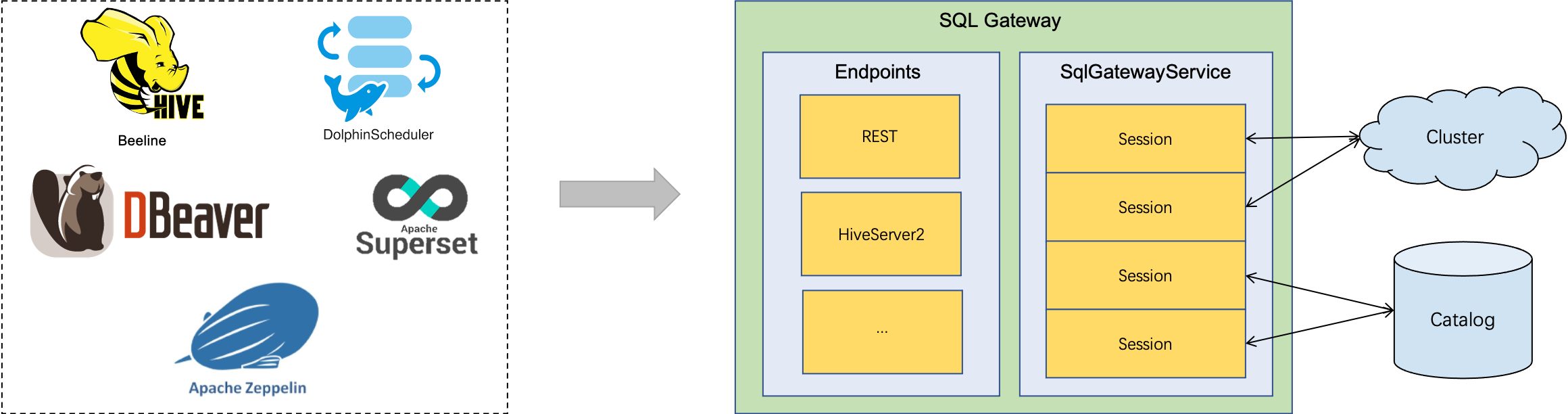
The SQL Gateway is a service that enables multiple clients from the remote to execute SQL in concurrency. It provides an easy way to submit the Flink Job, look up the metadata, and analyze the data online.
The SQL Gateway is composed of pluggable endpoints and the SqlGatewayService. The SqlGatewayService is a processor that is
reused by the endpoints to handle the requests. The endpoint is an entry point that allows users to connect. Depending on the
type of the endpoints, users can use different utils to connect.
Getting Started #
This section describes how to setup and run your first Flink SQL program from the command-line.
The SQL Gateway is bundled in the regular Flink distribution and thus runnable out-of-the-box. It requires only a running Flink cluster where table programs can be executed. For more information about setting up a Flink cluster see the Cluster & Deployment part. If you simply want to try out the SQL Client, you can also start a local cluster with one worker using the following command:
$ ./bin/start-cluster.sh
Starting the SQL Gateway #
The SQL Gateway scripts are also located in the binary directory of Flink. Users can start by calling:
$ ./bin/sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost
The command starts the SQL Gateway with REST Endpoint that listens on the address localhost:8083. You can use the curl command to check whether the REST Endpoint is available.
$ curl http://localhost:8083/v1/info
{"productName":"Apache Flink","version":"1.19.1"}
Running SQL Queries #
For validating your setup and cluster connection, you can work with following steps.
Step 1: Open a session
$ curl --request POST http://localhost:8083/v1/sessions
{"sessionHandle":"..."}
The sessionHandle in the return results is used by the SQL Gateway to uniquely identify every active user.
Step 2: Execute a query
$ curl --request POST http://localhost:8083/v1/sessions/${sessionHandle}/statements/ --data '{"statement": "SELECT 1"}'
{"operationHandle":"..."}
The operationHandle in the return results is used by the SQL Gateway to uniquely identify the submitted SQL.
Step 3: Fetch results
With the sessionHandle and operationHandle above, you can fetch the corresponding results.
$ curl --request GET http://localhost:8083/v1/sessions/${sessionHandle}/operations/${operationHandle}/result/0
{
"results": {
"columns": [
{
"name": "EXPR$0",
"logicalType": {
"type": "INTEGER",
"nullable": false
}
}
],
"data": [
{
"kind": "INSERT",
"fields": [
1
]
}
]
},
"resultType": "PAYLOAD",
"nextResultUri": "..."
}
The nextResultUri in the results is used to fetch the next batch results if it is not null.
$ curl --request GET ${nextResultUri}
Configuration #
SQL Gateway startup options #
Currently, the SQL Gateway script has the following optional commands. They are discussed in details in the subsequent paragraphs.
$ ./bin/sql-gateway.sh --help
Usage: sql-gateway.sh [start|start-foreground|stop|stop-all] [args]
commands:
start - Run a SQL Gateway as a daemon
start-foreground - Run a SQL Gateway as a console application
stop - Stop the SQL Gateway daemon
stop-all - Stop all the SQL Gateway daemons
-h | --help - Show this help message
For “start” or “start-foreground” command, you are able to configure the SQL Gateway in the CLI.
$ ./bin/sql-gateway.sh start --help
Start the Flink SQL Gateway as a daemon to submit Flink SQL.
Syntax: start [OPTIONS]
-D <property=value> Use value for given property
-h,--help Show the help message with descriptions of all
options.
SQL Gateway Configuration #
You can configure the SQL Gateway when starting the SQL Gateway below, or any valid Flink configuration entry:
$ ./sql-gateway -Dkey=value
| Key | Default | Type | Description |
|---|---|---|---|
sql-gateway.session.check-interval |
1 min | Duration | The check interval for idle session timeout, which can be disabled by setting to zero. |
sql-gateway.session.idle-timeout |
10 min | Duration | Timeout interval for closing the session when the session hasn't been accessed during the interval. If setting to zero, the session will not be closed. |
sql-gateway.session.max-num |
1000000 | Integer | The maximum number of the active session for sql gateway service. |
sql-gateway.session.plan-cache.enabled |
false | Boolean | When it is true, sql gateway will cache and reuse plans for queries per session. |
sql-gateway.session.plan-cache.size |
100 | Integer | Plan cache size, it takes effect iff `table.optimizer.plan-cache.enabled` is true. |
sql-gateway.session.plan-cache.ttl |
1 hour | Duration | TTL for plan cache, it controls how long will the cache expire after write, it takes effect iff `table.optimizer.plan-cache.enabled` is true. |
sql-gateway.worker.keepalive-time |
5 min | Duration | Keepalive time for an idle worker thread. When the number of workers exceeds min workers, excessive threads are killed after this time interval. |
sql-gateway.worker.threads.max |
500 | Integer | The maximum number of worker threads for sql gateway service. |
sql-gateway.worker.threads.min |
5 | Integer | The minimum number of worker threads for sql gateway service. |
Supported Endpoints #
Flink natively supports REST Endpoint and HiveServer2 Endpoint. The SQL Gateway is bundled with the REST Endpoint by default. With the flexible architecture, users are able to start the SQL Gateway with the specified endpoints by calling
$ ./bin/sql-gateway.sh start -Dsql-gateway.endpoint.type=hiveserver2
or add the following config in the Flink configuration file:
sql-gateway.endpoint.type: hiveserver2
Notice: The CLI command has higher priority if Flink configuration file also contains the option sql-gateway.endpoint.type.
For the specific endpoint, please refer to the corresponding page.