This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
Fine-Grained Resource Management
Fine-Grained Resource Management #
Apache Flink works hard to auto-derive sensible default resource requirements for all applications out of the box. For users who wish to fine-tune their resource consumption, based on knowledge of their specific scenarios, Flink offers fine-grained resource management.
This page describes the fine-grained resource management’s usage, applicable scenarios, and how it works.
Note: This feature is currently an MVP (“minimum viable product”) feature and only available to DataStream API.
Applicable Scenarios #
Typical scenarios that potentially benefit from fine-grained resource management are where:
-
Tasks have significantly different parallelisms.
-
The resource needed for an entire pipeline is too much to fit into a single slot/task manager.
-
Batch jobs where resources needed for tasks of different stages are significantly different
An in-depth discussion on why fine-grained resource management can improve resource efficiency for the above scenarios is presented in How it improves resource efficiency.
How it works #
As described in Flink Architecture, task execution resources in a TaskManager are split into many slots. The slot is the basic unit of both resource scheduling and resource requirement in Flink’s runtime.
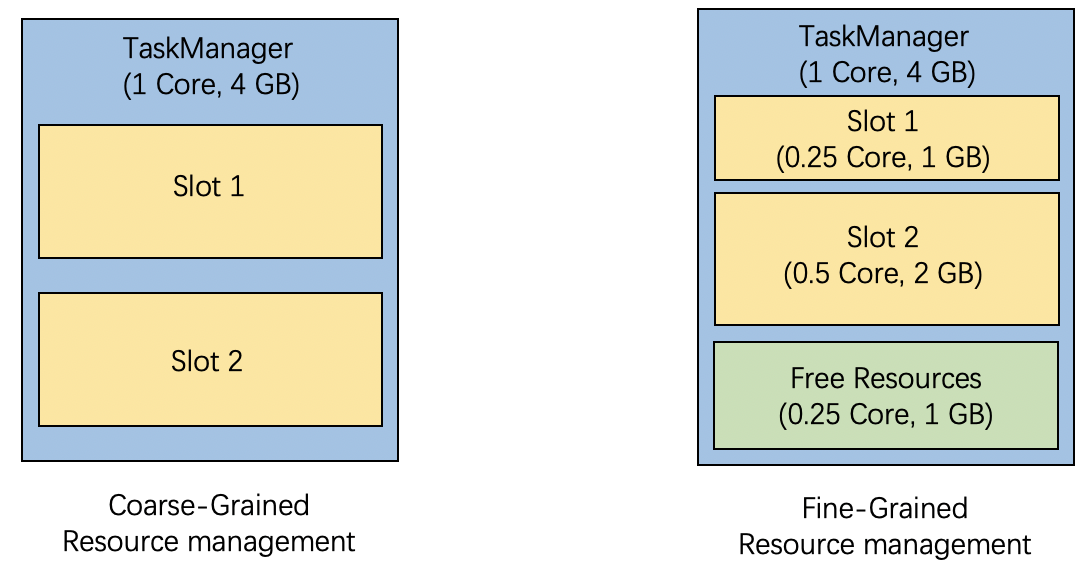
With fine-grained resource management, the slots requests contain specific resource profiles, which users can specify. Flink will respect those user-specified resource requirements and dynamically cut an exactly-matched slot out of the TaskManager’s available resources. As shown above, there is a requirement for a slot with 0.25 Core and 1GB memory, and Flink allocates Slot 1 for it.
Previously in Flink, the resource requirement only contained the required slots, without fine-grained resource profiles, namely coarse-grained resource management. The TaskManager had a fixed number of identical slots to fulfill those requirements.
For the resource requirement without a specified resource profile, Flink will automatically decide a resource profile. Currently, the resource profile of it is calculated from TaskManager’s total resource and taskmanager.numberOfTaskSlots, just like in coarse-grained resource management. As shown above, the total resource of TaskManager is 1 Core and 4 GB memory and the number of task slots is set to 2, Slot 2 is created with 0.5 Core and 2 GB memory for the requirement without a specified resource profile.
After the allocation of Slot 1 and Slot 2, there is 0.25 Core and 1 GB memory remaining as the free resources in the TaskManager. These free resources can be further partitioned to fulfill the following resource requirements.
Please refer to Resource Allocation Strategy for more details.
Usage #
To use fine-grained resource management, you need to specify the resource requirement.
Fine-grained resource requirements are defined on slot sharing groups. A slot sharing group is a hint that tells the JobManager operators/tasks in it CAN be put into the same slot.
For specifying the resource requirement, you need to:
-
Define the slot sharing group and the operators it contains.
-
Specify the resource of the slot sharing group.
There are two approaches to define the slot sharing group and the operators it contains:
-
You can define a slot sharing group only by its name and attach it to an operator through the slotSharingGroup(String name).
-
You can construct a
SlotSharingGroupinstance, which contains the name and an optional resource profile of the slot sharing group. TheSlotSharingGroupcan be attached to an operator throughslotSharingGroup(SlotSharingGroup ssg).
You can specify the resource profile for your slot sharing groups:
-
If you set the slot sharing group through
slotSharingGroup(SlotSharingGroup ssg), you can specify the resource profile in constructing theSlotSharingGroupinstance. -
If you only set the name of slot sharing group with slotSharingGroup(String name). You can construct a SlotSharingGroup instance with the same name along with the resource profile and register the resource of them with
StreamExecutionEnvironment#registerSlotSharingGroup(SlotSharingGroup ssg).
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SlotSharingGroup ssgA = SlotSharingGroup.newBuilder("a")
.setCpuCores(1.0)
.setTaskHeapMemoryMB(100)
.build();
SlotSharingGroup ssgB = SlotSharingGroup.newBuilder("b")
.setCpuCores(0.5)
.setTaskHeapMemoryMB(100)
.build();
someStream.filter(...).slotSharingGroup("a") // Set the slot sharing group with name “a”
.map(...).slotSharingGroup(ssgB); // Directly set the slot sharing group with name and resource.
env.registerSlotSharingGroup(ssgA); // Then register the resource of group “a”
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ssgA = SlotSharingGroup.newBuilder("a")
.setCpuCores(1.0)
.setTaskHeapMemoryMB(100)
.build()
val ssgB = SlotSharingGroup.newBuilder("b")
.setCpuCores(0.5)
.setTaskHeapMemoryMB(100)
.build()
someStream.filter(...).slotSharingGroup("a") // Set the slot sharing group with name “a”
.map(...).slotSharingGroup(ssgB) // Directly set the slot sharing group with name and resource.
env.registerSlotSharingGroup(ssgA) // Then register the resource of group “a”
env = StreamExecutionEnvironment.get_execution_environment()
ssg_a = SlotSharingGroup.builder('a') \
.set_cpu_cores(1.0) \
.set_task_heap_memory_mb(100) \
.build()
ssg_b = SlotSharingGroup.builder('b') \
.set_cpu_cores(0.5) \
.set_task_heap_memory_mb(100) \
.build()
some_stream.filter(...).slot_sharing_group('a') # Set the slot sharing group with name "a"
.map(...).slot_sharing_group(ssg_b) # Directly set the slot sharing group with name and resource.
env.register_slot_sharing_group(ssg_a) # Then register the resource of group "a"
Note: Each slot sharing group can only attach to one specified resource, any conflict will fail the compiling of your job.
In constructing the SlotSharingGroup, you can set the following resource components for the slot sharing group:
- CPU Cores. Defines how many CPU cores are needed. Required to be explicitly configured with positive value.
- Task Heap Memory. Defines how much task heap memory is needed. Required to be explicitly configured with positive value.
- Task Off-Heap Memory. Defines how much task off-heap memory is needed, can be 0.
- Managed Memory. Defines how much task managed memory is needed, can be 0.
- External Resources. Defines the external resources needed, can be empty.
// Directly build a slot sharing group with specific resource
SlotSharingGroup ssgWithResource =
SlotSharingGroup.newBuilder("ssg")
.setCpuCores(1.0) // required
.setTaskHeapMemoryMB(100) // required
.setTaskOffHeapMemoryMB(50)
.setManagedMemory(MemorySize.ofMebiBytes(200))
.setExternalResource("gpu", 1.0)
.build();
// Build a slot sharing group without specific resource and then register the resource of it in StreamExecutionEnvironment
SlotSharingGroup ssgWithName = SlotSharingGroup.newBuilder("ssg").build();
env.registerSlotSharingGroup(ssgWithResource);
// Directly build a slot sharing group with specific resource
val ssgWithResource =
SlotSharingGroup.newBuilder("ssg")
.setCpuCores(1.0) // required
.setTaskHeapMemoryMB(100) // required
.setTaskOffHeapMemoryMB(50)
.setManagedMemory(MemorySize.ofMebiBytes(200))
.setExternalResource("gpu", 1.0)
.build()
// Build a slot sharing group without specific resource and then register the resource of it in StreamExecutionEnvironment
val ssgWithName = SlotSharingGroup.newBuilder("ssg").build()
env.registerSlotSharingGroup(ssgWithResource)
# Directly build a slot sharing group with specific resource
ssg_with_resource = SlotSharingGroup.builder('ssg') \
.set_cpu_cores(1.0) \
.set_task_heap_memory_mb(100) \
.set_task_off_heap_memory_mb(50) \
.set_managed_memory(MemorySize.of_mebi_bytes(200)) \
.set_external_resource('gpu', 1.0) \
.build()
# Build a slot sharing group without specific resource and then register the resource of it in StreamExecutionEnvironment
ssg_with_name = SlotSharingGroup.builder('ssg').build()
env.register_slot_sharing_group(ssg_with_resource)
Note: You can construct a SlotSharingGroup with or without specifying its resource profile. With specifying the resource profile, you need to explicitly set the CPU cores and Task Heap Memory with a positive value, other components are optional.
Limitations #
Since fine-grained resource management is a new, experimental feature, not all features supported by the default scheduler are also available with it. The Flink community is working on addressing these limitations.
-
No support for the Elastic Scaling. The elastic scaling only supports slot requests without specified-resource at the moment.
-
Limited integration with Flink’s Web UI. Slots in fine-grained resource management can have different resource specs. The web UI only shows the slot number without its details at the moment.
-
Limited integration with batch jobs. At the moment, fine-grained resource management requires batch workloads to be executed with types of all edges being BLOCKING. To do that, you need to configure fine-grained.shuffle-mode.all-blocking to
true. Notice that this may affect the performance. See FLINK-20865 for more details. -
Hybrid resource requirements are not recommended. It is not recommended to specify the resource requirements only for some parts of the job and leave the requirements for the rest unspecified. Currently, the unspecified requirement can be fulfilled with slots of any resource. The actual resource acquired by it can be inconsistent across different job executions or failover.
-
Slot allocation result might not be optimal. As the slot requirements contain multiple dimensions of resources, the slot allocation is indeed a multi-dimensional packing problem, which is NP-hard. The default resource allocation strategy might not achieve optimal slot allocation and can lead to resource fragments or resource allocation failure in some scenarios.
Notice #
-
Setting the slot sharing group may change the performance. Setting chain-able operators to different slot sharing groups may break operator chains, and thus change the performance.
-
Slot sharing group will not restrict the scheduling of operators. The slot sharing group only hints the scheduler that the grouped operators CAN be deployed into a shared slot. There’s no guarantee that the scheduler always deploys the grouped operator together. In cases grouped operators are deployed into separate slots, the slot resources will be derived from the specified group requirement.
Deep Dive #
How it improves resource efficiency #
In this section, we deep dive into how fine-grained resource management improves resource efficiency, which can help you to understand whether it can benefit your jobs.
Previously, Flink adopted a coarse-grained resource management approach, where tasks are deployed into predefined, usually identical slots without the notion of how many resources each slot contains. For many jobs, using coarse-grained resource management and simply putting all tasks into one slot sharing group works well enough in terms of resource utilization.
-
For many streaming jobs that all tasks have the same parallelism, each slot will contain an entire pipeline. Ideally, all pipelines should use roughly the same resources, which can be satisfied easily by tuning the resources of the identical slots.
-
Resource consumption of tasks varies over time. When consumption of a task decreases, the extra resources can be used by another task whose consumption is increasing. This, known as the peak shaving and valley filling effect, reduces the overall resource needed.
However, there are cases where coarse-grained resource management does not work well.
-
Tasks may have different parallelisms. Sometimes, such different parallelisms cannot be avoided. E.g., the parallelism of source/sink/lookup tasks might be constrained by the partitions and IO load of the external upstream/downstream system. In such cases, slots with fewer tasks would need fewer resources than those with the entire pipeline of tasks.
-
Sometimes the resource needed for the entire pipeline might be too much to be put into a single slot/TaskManager. In such cases, the pipeline needs to be split into multiple SSGs, which may not always have the same resource requirement.
-
For batch jobs, not all the tasks can be executed at the same time. Thus, the instantaneous resource requirement of the pipeline changes over time.
Trying to execute all tasks with identical slots can result in non-optimal resource utilization. The resource of the identical slots has to be able to fulfill the highest resource requirement, which will be wasteful for other requirements. When expensive external resources like GPU are involved, such waste can become even harder to afford. The fine-grained resource management leverages slots of different resources to improve resource utilization in such scenarios.
Resource Allocation Strategy #
In this section, we talk about the slot partitioning mechanism in Flink runtime and the resource allocation strategy, including how the Flink runtime selects a TaskManager to cut slots and allocates TaskManagers on Native Kubernetes and YARN. Note that the resource allocation strategy is pluggable in Flink runtime and here we introduce its default implementation in the first step of fine-grained resource management. In the future, there might be various strategies that users can select for different scenarios.
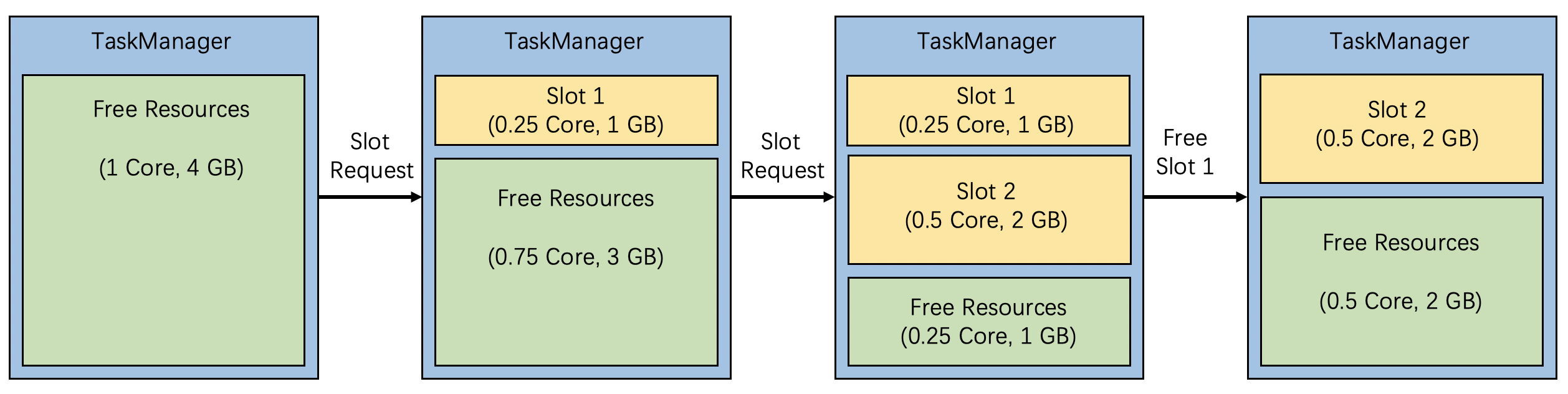
As described in How it works section, Flink will cut an exactly matched slot out of the TaskManager for slot requests with specified resources. The internal process is shown above. The TaskManager will be launched with total resources but no predefined slots. When a slot request with 0.25 Core and 1GB memory arrives, Flink will select a TaskManager with enough free resources and create a new slot with the requested resources. If a slot is freed, it will return its resources to the available resources of the TaskManager.
In the current resource allocation strategy, Flink will traverse all the registered TaskManagers and select the first one who has enough free resources to fulfill the slot request. When there is no TaskManager that has enough free resources, Flink will try to allocate a new TaskManager when deploying on Native Kubernetes or YARN. In the current strategy, Flink will allocate identical TaskManagers according to user’s configuration. As the resource spec of TaskManagers is pre-defined:
-
There might be resource fragments in the cluster. E.g. if there are two slot requests with 3 GB heap memory while the total heap memory of TaskManager is 4 GB, Flink will start two TaskManagers and there will be 1 GB heap memory wasted in each TaskManager. In the future, there might be a resource allocation strategy that can allocate heterogeneous TaskManagers according to the slot requests of the job and thus mitigate the resource fragment.
-
You need to make sure the resource components configured for the slot sharing group are no larger than the total resources of the TaskManager. Otherwise, your job will fail with an exception.