This documentation is for an unreleased version of Apache Flink. We recommend you use the latest stable version.
Hints
SQL Hints #
Batch Streaming
SQL hints can be used with SQL statements to alter execution plans. This chapter explains how to use hints to force various approaches.
Generally a hint can be used to:
- Enforce planner: there’s no perfect planner, so it makes sense to implement hints to allow user better control the execution;
- Append meta data(or statistics): some statistics like “table index for scan” and “skew info of some shuffle keys” are somewhat dynamic for the query, it would be very convenient to config them with hints because our planning metadata from the planner is very often not that accurate;
- Operator resource constraints: for many cases, we would give a default resource configuration for the execution operators, i.e. min parallelism or managed memory (resource consuming UDF) or special resource requirement (GPU or SSD disk) and so on, it would be very flexible to profile the resource with hints per query(instead of the Job).
Dynamic Table Options #
Dynamic table options allows to specify or override table options dynamically, different with static table options defined with SQL DDL or connect API, these options can be specified flexibly in per-table scope within each query.
Thus it is very suitable to use for the ad-hoc queries in interactive terminal, for example, in the SQL-CLI,
you can specify to ignore the parse error for a CSV source just by adding a dynamic option /*+ OPTIONS('csv.ignore-parse-errors'='true') */.
Syntax #
In order to not break the SQL compatibility, we use the Oracle style SQL hint syntax:
table_path /*+ OPTIONS(key=val [, key=val]*) */
key:
stringLiteral
val:
stringLiteral
Examples #
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);
-- override table options in query source
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;
-- override table options in join
select * from
kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1
join
kafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2
on t1.id = t2.id;
-- override table options for INSERT target table
insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2;
Query Hints #
Query hints can be used to suggest the optimizer to affect query execution plan within a specified query scope.
Their effective scope is current Query block(What are query blocks ?) which Query Hints are specified.
Now, Flink Query Hints only support Join Hints.
Syntax #
The Query Hints syntax in Flink follows the syntax of Query Hints in Apache Calcite:
# Query Hints:
SELECT /*+ hint [, hint ] */ ...
hint:
hintName
| hintName '(' optionKey '=' optionVal [, optionKey '=' optionVal ]* ')'
| hintName '(' hintOption [, hintOption ]* ')'
optionKey:
simpleIdentifier
| stringLiteral
optionVal:
stringLiteral
hintOption:
simpleIdentifier
| numericLiteral
| stringLiteral
Conflict Cases In Query Hints #
Resolution of Key-value Hint Conflicts #
For key-value hints, which are provided in the following syntax:
hintName '(' optionKey '=' optionVal [, optionKey '=' optionVal ]* ')'
When Flink encounters conflicting in key-value hints, it adopts a last-write-wins strategy. This means that if multiple hint values are provided for the same key, Flink will use the value from the last hint specified in the query. For instance, consider the following SQL query with conflicting ‘max-attempts’ values in the LOOKUP hint:
SELECT /*+ LOOKUP('table'='D', 'max-attempts'='3', 'max-attempts'='4') */ * FROM t1 T JOIN t2 AS OF T.proctime AS D ON T.id = D.id;
In this case, Flink will resolve the conflict by selecting the last specified value for ‘max-attempts’. Therefore, the effective hint for ‘max-attempts’ will be ‘4’.
Resolution of List Hint Conflicts #
List hints are provided using the following syntax:
hintName '(' hintOption [, hintOption ]* ')'
With list hints, Flink resolves conflicts by adopting a first-accept strategy. This means that the first specified hint in the list will take precedence and be effective. For example, consider the following SQL query with conflicting BROADCAST hints:
SELECT /*+ BROADCAST(t2, t1), BROADCAST(t1, t2) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
In this scenario, Flink will choose the BROADCAST hint that is listed first. Therefore, the effective broadcast hint is BROADCAST(t2, t1).
Join Hints #
Join Hints allow users to suggest the join strategy to optimizer in order to get a more high-performance execution plan.
Now Flink Join Hints support BROADCAST, SHUFFLE_HASH, SHUFFLE_MERGE and NEST_LOOP.
Note:
- The table specified in Join Hints must exist. Otherwise, a table not exists error will be thrown.
- Flink Join Hints only support one hint block in a query block, if multiple hint blocks are specified like
/*+ BROADCAST(t1) */ /*+ SHUFFLE_HASH(t1) */, an exception will be thrown when parse this query statement.- In one hint block, specifying multiple tables in a single Join Hint like
/*+ BROADCAST(t1, t2, ..., tn) */or specifying multiple Join Hints like/*+ BROADCAST(t1), BROADCAST(t2), ..., BROADCAST(tn) */are both supported.- For multiple tables in a single Join Hints or multiple Join Hints in a hint block, Flink Join Hints may conflict. If the conflicts occur, Flink will choose the most matching table or join strategy. (See: Conflict Cases In Join Hints)
BROADCAST #
BatchBROADCAST suggests that Flink uses BroadCast join. The join side with the hint will be broadcast
regardless of table.optimizer.join.broadcast-threshold, so it performs well when the data volume of the hint side of table
is very small.
Note: BROADCAST only supports join with equivalence join condition, and it doesn’t support Full Outer Join.
Examples #
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);
-- Flink will use broadcast join and t1 will be the broadcast table.
SELECT /*+ BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- Flink will use broadcast join for both joins and t1, t3 will be the broadcast table.
SELECT /*+ BROADCAST(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
-- BROADCAST don't support non-equivalent join conditions.
-- Join Hint will not work, and only nested loop join can be applied.
SELECT /*+ BROADCAST(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
-- BROADCAST don't support full outer join.
-- Join Hint will not work in this case, and the planner will choose the appropriate join strategy based on cost.
SELECT /*+ BROADCAST(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
SHUFFLE_HASH #
BatchSHUFFLE_HASH suggests that Flink uses Shuffle Hash join. The join side with the hint will be the join build side, it performs well when
the data volume of the hint side of table is not too large.
Note: SHUFFLE_HASH only supports join with equivalence join condition.
Examples #
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);
-- Flink will use hash join and t1 will be the build side.
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- Flink will use hash join for both joins and t1, t3 will be the join build side.
SELECT /*+ SHUFFLE_HASH(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
-- SHUFFLE_HASH don't support non-equivalent join conditions.
-- For this case, Join Hint will not work, and only nested loop join can be applied.
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
SHUFFLE_MERGE #
BatchSHUFFLE_MERGE suggests that Flink uses Sort Merge join. This type of Join Hint is recommended for using in the scenario of joining
between two large tables or the scenario that the data at both sides of the join is already in order.
Note: SHUFFLE_MERGE only supports join with equivalence join condition.
Examples #
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);
-- Sort merge join strategy is adopted.
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- Sort merge join strategy is both adopted in these two joins.
SELECT /*+ SHUFFLE_MERGE(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
-- SHUFFLE_MERGE don't support non-equivalent join conditions.
-- Join Hint will not work, and only nested loop join can be applied.
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
NEST_LOOP #
BatchNEST_LOOP suggests that Flink uses Nested Loop join. This type of join hint is not recommended without special scenario requirements.
Note: NEST_LOOP supports both equivalent and non-equivalent join condition.
Examples #
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);
-- Flink will use nested loop join and t1 will be the build side.
SELECT /*+ NEST_LOOP(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- Flink will use nested loop join for both joins and t1, t3 will be the join build side.
SELECT /*+ NEST_LOOP(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
LOOKUP #
StreamingThe LOOKUP hint allows users to suggest the Flink optimizer to:
- use synchronous(sync) or asynchronous(async) lookup function
- configure the async parameters
- enable delayed retry strategy for lookup
LOOKUP Hint Options: #
| option type | option name | required | value type | default value | description |
|---|---|---|---|---|---|
| table | table | Y | string | N/A | the table name of the lookup source |
| async | async | N | boolean | N/A | value can be 'true' or 'false' to suggest the planner choose the corresponding lookup function. If the backend lookup source does not support the suggested lookup mode, it will take no effect. |
| output-mode | N | string | ordered | value can be 'ordered' or 'allow_unordered'. 'allow_unordered' means if users allow unordered result, it will attempt to use AsyncDataStream.OutputMode.UNORDERED when it does not affect the correctness of the result, otherwise ORDERED will be still used. It is consistent with `ExecutionConfigOptions#TABLE_EXEC_ASYNC_LOOKUP_OUTPUT_MODE`. |
|
| capacity | N | integer | 100 | the buffer capacity for the backend asyncWaitOperator of the lookup join operator. | |
| timeout | N | duration | 300s | timeout from first invoke to final completion of asynchronous operation, may include multiple retries, and will be reset in case of failover | |
| retry | retry-predicate | N | string | N/A | can be 'lookup_miss' which will enable retry if lookup result is empty. |
| retry-strategy | N | string | N/A | can be 'fixed_delay' | |
| fixed-delay | N | duration | N/A | delay time for the 'fixed_delay' strategy | |
| max-attempts | N | integer | N/A | max attempt number of the 'fixed_delay' strategy |
Note:
- ’table’ option is required, only table name is supported(keep consistent with which in the FROM clause), note that only alias name can be used if table has an alias name.
- async options are all optional, will use default value if not configured.
- there is no default value for retry options, all retry options should be set to valid values when need to enable retry.
1. Use Sync And Async Lookup Function #
If the connector has both capabilities of async and sync lookup, users can give the option value ‘async’=‘false’ to suggest the planner to use the sync lookup or ‘async’=‘true’ to use the async lookup:
Example:
-- suggest the optimizer to use sync lookup
LOOKUP('table'='Customers', 'async'='false')
-- suggest the optimizer to use async lookup
LOOKUP('table'='Customers', 'async'='true')
Note: the optimizer prefers async lookup if no ‘async’ option is specified, it will always use sync lookup when:
- the connector only implements the sync lookup
- user enables ‘TRY_RESOLVE’ mode of ’table.optimizer.non-deterministic-update.strategy’ and the optimizer has checked there’s correctness issue caused by non-deterministic update.
2. Configure The Async Parameters #
Users can configure the async parameters via async options on async lookup mode.
Example:
-- configure the async parameters: 'output-mode', 'capacity', 'timeout', can set single one or multi params
LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
Note: the async options are consistent with the async options in job level Execution Options, will use job level configuration if not set. Another difference is that the scope of the LOOKUP hint is smaller, limited to the table name corresponding to the hint option set in the current lookup operation (other lookup operations will not be affected by the LOOKUP hint).
e.g., if the job level configuration is:
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
then the following hints:
1. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered')
2. LOOKUP('table'='Customers', 'async'='true', 'timeout'='300s')
are equivalent to:
1. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
2. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='ordered', 'capacity'='100', 'timeout'='300s')
3. Enable Delayed Retry Strategy For Lookup #
Delayed retry for lookup join is intended to solve the problem of delayed updates in external system which cause unexpected enrichment with stream data. The hint option ‘retry-predicate’=‘lookup_miss’ can enable retry on both sync and async lookup, only fixed delay retry strategy is supported currently.
Options of fixed delay retry strategy:
'retry-strategy'='fixed_delay'
-- fixed delay duration
'fixed-delay'='10s'
-- max number of retry(counting from the retry operation, if set to '1', then a single lookup process
-- for a specific lookup key will actually execute up to 2 lookup requests)
'max-attempts'='3'
Example:
- enable retry on async lookup
LOOKUP('table'='Customers', 'async'='true', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
- enable retry on sync lookup
LOOKUP('table'='Customers', 'async'='false', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
If the lookup source only has one capability, then the ‘async’ mode option can be omitted:
LOOKUP('table'='Customers', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
Further Notes #
Effect Of Enabling Caching On Retries #
FLIP-221 adds caching support for lookup source, which has PARTIAL and FULL caching mode(the mode NONE means disable caching). When FULL caching is enabled, there’ll be no retry at all(because it’s meaningless to retry lookup via a full cached mirror of lookup source). When PARTIAL caching is enabled, it will lookup from local cache first for a coming record and will do an external lookup via backend connector if cache miss(if cache hit, then return the record immediately), and this will trigger a retry when lookup result is empty(same with caching disabled), the final lookup result is determined when retry completed(in PARTIAL caching mode, it will also update local cache).
Note On Lookup Keys And ‘retry-predicate’=‘lookup_miss’ Retry Conditions #
For different connectors, the index-lookup capability maybe different, e.g., builtin HBase connector
can lookup on rowkey only (without secondary index), while builtin JDBC connector can provide more
powerful index-lookup capabilities on arbitrary columns, this is determined by the different physical
storages.
The lookup key mentioned here is the field or combination of fields for the index-lookup,
as the example of lookup join, where
c.id is the lookup key of the join condition “ON o.customer_id = c.id”:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id
if we change the join condition to “ON o.customer_id = c.id and c.country = ‘US’":
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id and c.country = 'US'
both c.id and c.country will be used as lookup key when Customers table was stored in MySql:
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
)
only c.id can be the lookup key when Customers table was stored in HBase, and the remaining join
condition c.country = 'US' will be evaluated after lookup result returned
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'hbase-2.2',
...
)
Accordingly, the above query will have different retry effects on different storages when enable ’lookup_miss’ retry predicate and the fixed-delay retry strategy.
e.g., if there is a row in the Customers table:
id=100, country='CN'
When processing an record with ‘id=100’ in the order stream, in ‘jdbc’ connector, the corresponding
lookup result is null (country='CN' does not satisfy the condition c.country = 'US') because both
c.id and c.country are used as lookup keys, so this will trigger a retry.
When in ‘hbase’ connector, only c.id will be used as the lookup key, the corresponding lookup result
will not be empty(it will return the record id=100, country='CN'), so it will not trigger a retry
(the remaining join condition c.country = 'US' will be evaluated as not true for returned record).
Currently, based on SQL semantic considerations, only the ’lookup_miss’ retry predicate is provided, and when it is necessary to wait for delayed updates of the dimension table (where a historical version record already exists in the table, rather than not), users can try two solutions:
- implements a custom retry predicate with the new retry support in DataStream Async I/O (allows for more complex judgments on returned records).
- enable delayed retry by adding another join condition including comparison on some kind of data version generated by timestamp
for the above example, assume the
Customerstable is updated every hour, we can add a new time-dependent version fieldupdate_version, which is reserved to hourly precision, e.g., update time ‘2022-08-15 12:01:02’ of record will store theupdate_versionas ’ 2022-08-15 12:00’
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING,
-- the newly added time-dependent version field
update_version STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers'
)
append an equal condition on both time field of Order stream and Customers.update_version to the join condition:
ON o.customer_id = c.id AND DATE_FORMAT(o.order_timestamp, 'yyyy-MM-dd HH:mm') = c.update_version
then we can enable delayed retry when Order’s record can not lookup the new record with ‘12:00’ version in Customers table.
Trouble Shooting #
When turning on the delayed retry lookup, it is more likely to encounter a backpressure problem in the lookup node, this can be quickly confirmed via the ‘Thread Dump’ on the ‘Task Manager’ page of web ui. From async and sync lookups respectively, call stack of thread sleep will appear in:
- async lookup:
RetryableAsyncLookupFunctionDelegator - sync lookup:
RetryableLookupFunctionDelegator
Note:
- async lookup with retry is not capable for fixed delayed processing for all input data (should use other lighter ways to solve, e.g., pending source consumption or use sync lookup with retry)
- delayed waiting for retry execution in sync lookup is fully synchronous, i.e., processing of the next record does not begin until the current record has completed.
- in async lookup, if ‘output-mode’ is ‘ORDERED’ mode, the probability of backpressure caused by delayed retry maybe higher than ‘UNORDERED’ mode, in which case increasing async ‘capacity’ may not be effective in reducing backpressure, and it may be necessary to consider reducing the delay duration.
Conflict Cases In Join Hints #
If the Join Hints conflicts occur, Flink will choose the most matching one.
- First,
Join Hintswill follow the logic of Flink query hint for resolving conflicts (see: Conflict Cases In Query Hints) - Conflict in one same Join Hint strategy, Flink will choose the first matching table for a join.
- Conflict in different Join Hints strategies, Flink will choose the first matching hint for a join.
Examples #
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);
-- Conflict in One Same Join Hints Strategy Case
-- The first hint will be chosen, t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2), BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- BROADCAST(t2, t1) will be chosen, and t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2, t1), BROADCAST(t1, t2) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- This case equals to BROADCAST(t1, t2) + BROADCAST(t3),
-- when join between t1 and t2, t1 will be the broadcast table,
-- when join between the result after t1 join t2 and t3, t3 will be the broadcast table.
SELECT /*+ BROADCAST(t1, t2, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
-- Conflict in Different Join Hints Strategies Case
-- The first Join Hint (BROADCAST(t1)) will be chosen, and t1 will be the broadcast table.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
-- Although BROADCAST is first one hint, but it doesn't support full outer join,
-- so the following SHUFFLE_HASH(t1) will be chosen, and t1 will be the join build side.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
-- Although there are two Join Hints were defined, but all of them are neither support non-equivalent join,
-- so only nested loop join can be applied.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id > t2.id;
State TTL Hints #
StreamingFor stateful computation Regular Join
and Group Aggregation, users can
use STATE_TTL hint to
specify operator-level Idle State Retention Time,
which enables the aforementioned operators to have a different TTL against the pipeline level configuration table.exec.state.ttl.
Regular Join Examples #
CREATE TABLE orders (
o_orderkey INT,
o_custkey INT,
o_status BOOLEAN,
o_totalprice DOUBLE
) WITH (...);
CREATE TABLE lineitem (
l_linenumber int,
l_orderkey int,
l_partkey int,
l_extendedprice double
) WITH (...);
CREATE TABLE customers (
c_custkey int,
c_address string
) WITH (...);
-- table name as hint key
SELECT /*+ STATE_TTL('orders'='3d', 'lineitem'='1d') */ * FROM
orders LEFT JOIN lineitem
ON orders.o_orderkey = lineitem.l_orderkey;
-- table alias as hint key
SELECT /*+ STATE_TTL('o'='3d', 'l'='1d') */ * FROM
orders o LEFT JOIN lineitem l
ON o.o_orderkey = l.l_orderkey;
-- temporary view name as hint key
CREATE TEMPORARY VIEW left_input AS SELECT ... FROM orders WHERE ...;
CREATE TEMPORARY VIEW right_input AS SELECT ... FROM lineitem WHERE ...;
SELECT /*+ STATE_TTL('left_input'= '360000s', 'right_input' = '15h') */ *
FROM left_input JOIN right_input
ON left_input.join_key = right_input.join_key;
-- cascade joins
SELECT /*+ STATE_TTL('o' = '3d', 'l' = '1d', 'c' = '10d') */ *
FROM orders o LEFT OUTER JOIN lineitem l
ON o.o_orderkey = l.l_orderkey
LEFT OUTER JOIN customers c
ON o.o_custkey = c.c_custkey;
Group Aggregation Examples #
-- table name as hint key
SELECT /*+ STATE_TTL('orders' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenue
FROM orders
GROUP BY o_orderkey;
-- table alias as hint key
SELECT /*+ STATE_TTL('o' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenue
FROM orders AS o
GROUP BY o_orderkey;
-- query block alias as hint key
SELECT /*+ STATE_TTL('tmp' = '1d') */ o_orderkey, SUM(o_totalprice) AS revenue
FROM (SELECT o_orderkey, o_totalprice
FROM orders
WHERE o_shippriority = 0) tmp
GROUP BY o_orderkey;
Note:
- Users can choose either table/view name or table alias as the hint key. However, once the alias is specified, the
STATE_TTLmust be hinted on the alias.- For cascade joins, the specified state TTLs will be interpreted as the left and right state TTL for the first join operator and the right state TTL for the second join operator (from a bottom-up order). The left state TTL for the second join operator will be retrieved from the configuration
table.exec.state.ttl. If users need to set a specific TTL value for the left state of the second join operator, the query needs to be split into query blocks likeCREATE TEMPORARY VIEW V AS SELECT /*+ STATE_TTL('A' = '1d', 'B' = '12h')*/ * FROM A JOIN B ON...; SELECT /*+ STATE_TTL('V' = '1d', 'C' = '3d')*/ * FROM V JOIN C ON ...;- STATE_TTL hint only applies on the underlying query block.
- When the
STATE_TTLhint key is duplicated, the value is applied from the last occurrence. For example, in cases likeSELECT /*+ STATE_TTL('A' = '1d', 'A' = '2d')*/ * FROM ..., the TTL for input A will be taken as 2d.- When there are multiple
STATE_TTLhints appear with duplicated hint key, the value is applied from the first occurrence. For example, in cases likeSELECT /*+ STATE_TTL('A' = '1d', 'B' = '2d'), STATE_TTL('C' = '12h', 'A' = '6h')*/ * FROM ..., the TTL for input A will be taken as 1d.
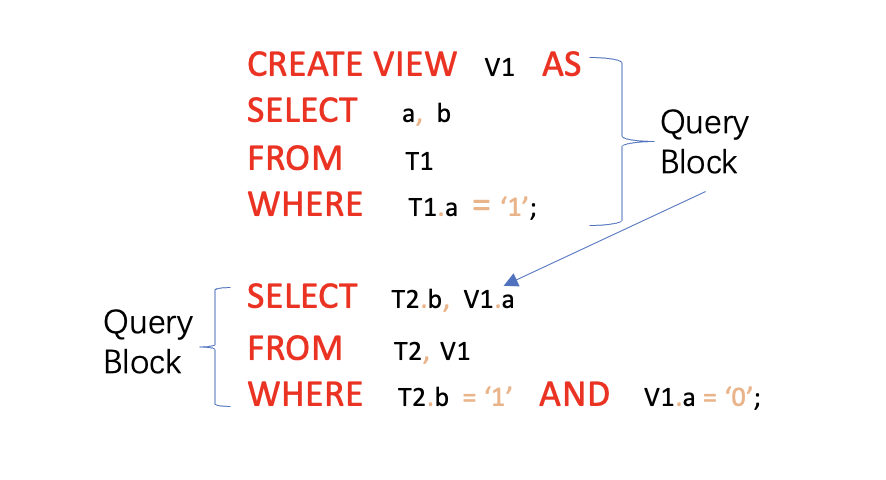
What are query blocks ? #
A query block is a basic unit of SQL. For example, any inline view or sub-query of a SQL statement are considered separate
query block to the outer query.
Examples #
An SQL statement can consist of several sub-queries. The sub-query can be a SELECT, INSERT or DELETE. A sub-query can contain
other sub-queries in the FROM clause, the WHERE clause, or a sub-select of a UNION or UNION ALL.
For these different sub-queries or view types, they can be composed of several query blocks, For example:
The simple query below has just one sub-query, but it has two query blocks - one for the outer SELECT and another for the
sub-query SELECT.

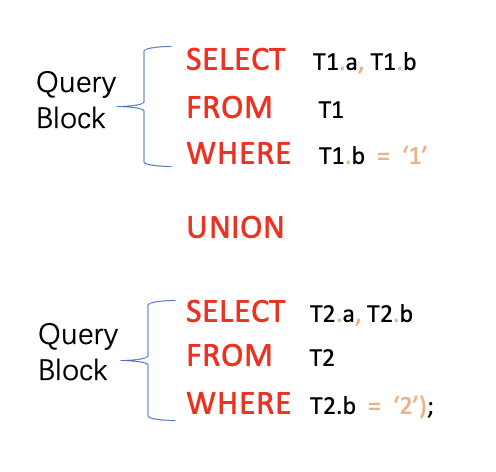
The query below is a union query, which contains two query blocks - one for the first SELECT and another for the second SELECT.
The query below contains a view, and it has two query blocks - one for the outer SELECT and another for the view.